- @taos_data
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
近日,中国信息通信研究院(简称"中国信通院")2026 上半年"可信数据库"评估测试结果正式揭晓。经来自联通软研院、陕西移动、瑞众人寿、上海国际汽车城、中国航信、邮储银行等单位的行业专家评审,涛思数据 TDengine 系列产品一举通过三项专项测评,成为本批次中同时斩获 AI 大模型时序数据管理平台、时序数据库性能、时序数据库稳定性三大领域认可的数据库产品。

Pandas 之所以受欢迎,是因为它让数据分析变得直接;TDengine TSDB 之所以适合时序场景,是因为它面向海量时序数据的写入、存储和查询做了专门设计。两者连接起来以后,开发者和分析人员就可以在熟悉的 Python 工作流里,直接处理 TDengine TSDB 中的时序数据。对很多团队来说,这种集成的意义并不复杂:数据继续存放在适合时序场景的数据库里,分析继续使用成熟顺手的 Pandas

云鼎科技采用TDengine TSDB和TDgpt优化煤矿与风电数据管理 云鼎科技在煤矿安全生产管控平台中选用TDengine TSDB,实现对75对矿井、1100余个系统的工业数据采集与分析,构建了云端协同的时序数据体系。

同等条件下测试结果显示,TDengine的压缩率最高,查询性能最优。
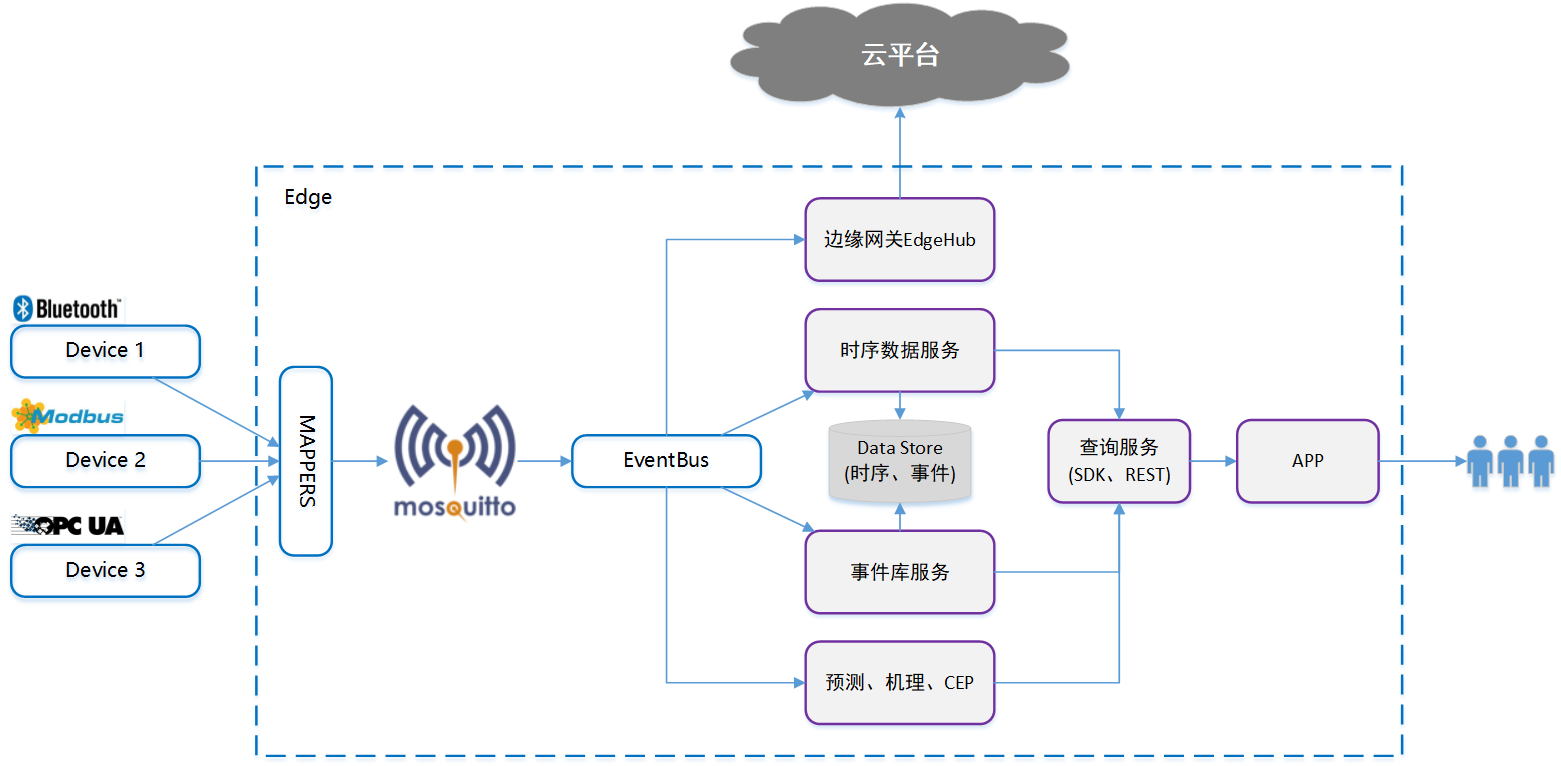
近日,3.3.7.0 版本正式发布。本次更新聚焦“时序数据处理与集成能力”双重提升,围绕数据处理的实时性、复杂性和低延迟需求,全面升级流计算架构,并新增 MQTT 数据订阅、BLOB 数据类型、多级存储共享存储支持、IPv6 通信等关键能力,持续强化时序数据平台的场景适应力与可扩展性。如果你关注 AIoT、车联网、工业控制等前沿领域的时序数据管理,这一版本更新将为你带来更多“用得上”的技术能力👇

undefined
undefined
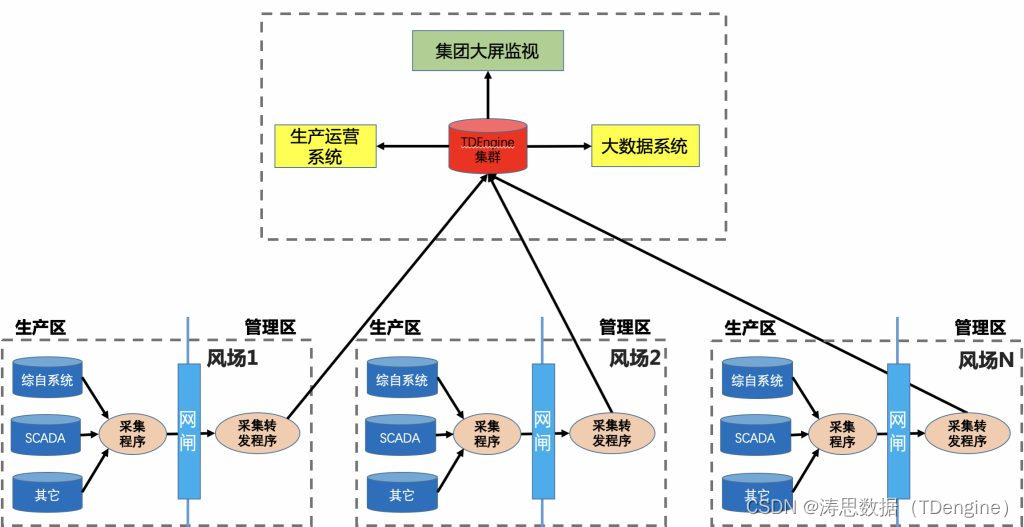
在应对海量时序数据处理需求时,如关系型数据库、工业实时库、Hadoop 大数据平台在内的传统数据库解决方案问题重重,严重阻碍数字化进程。在此背景下,一些企业开始尝试进行数据架构改造,选择适合的时序数据库产品。
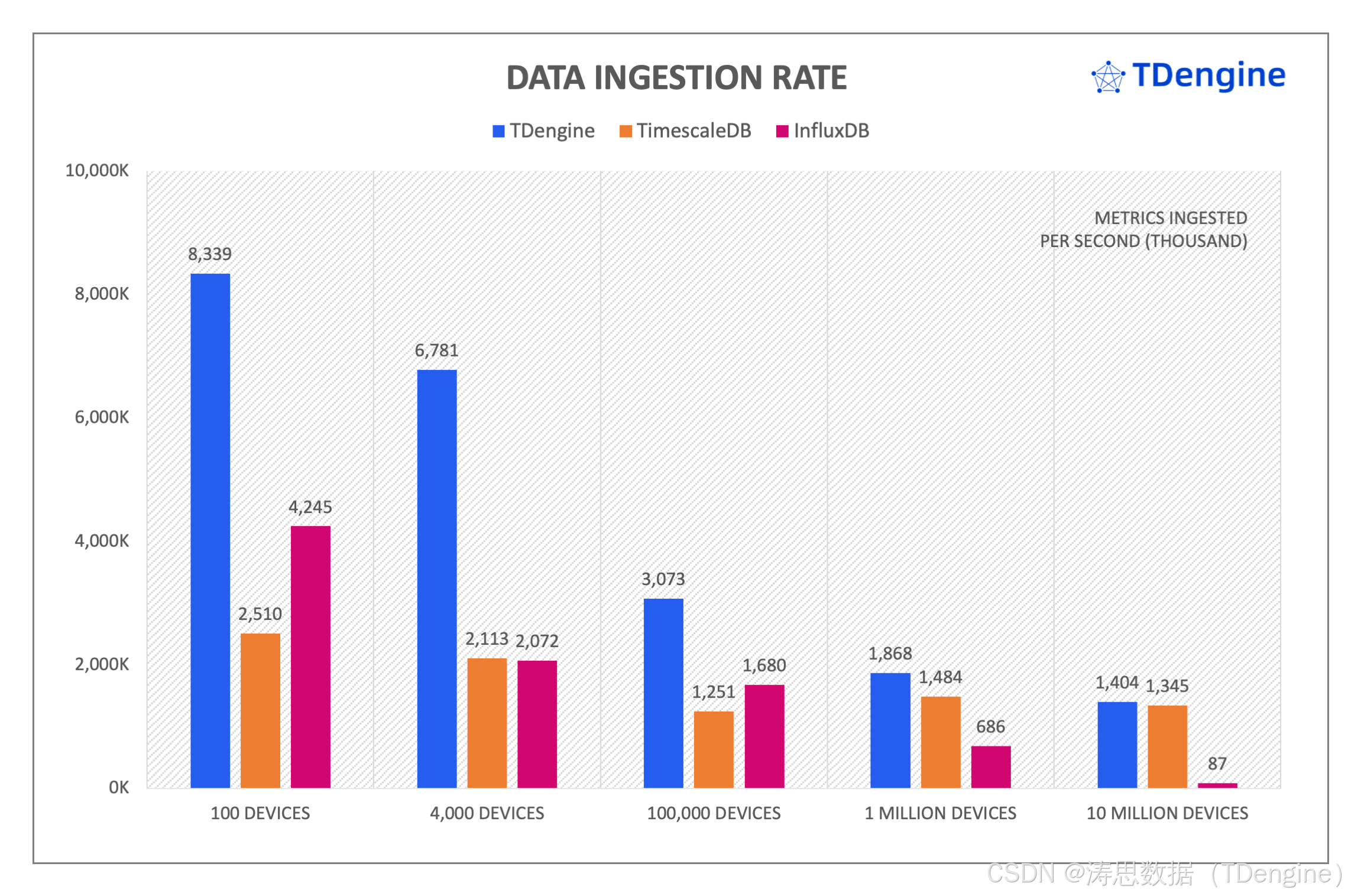
TDengine、InfluxDB & TimescaleDB 的查询性能大比拼

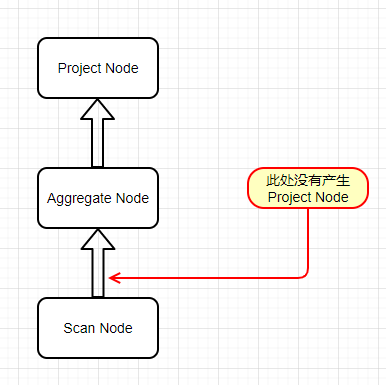
在使用或者实现分布式数据库(Distributed Database)时,会面临把一个表的数据按照一定的策略分散到各个数据库节点上的情况,随之而来的是多节点数据查询复杂性的问题,例如 Join 和子查询。本文将会为你解读分布式数据库下子查询和 Join 等复杂 SQL 如何实现,来帮助你更好地解决上述问题。......