登录社区云,与社区用户共同成长
邀请您加入社区
node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate
Prometheus 是一个开源的系统监控和告警工具包,最初由 SoundCloud 开发,现在是 CNCF(云原生计算基金会)的毕业项目。
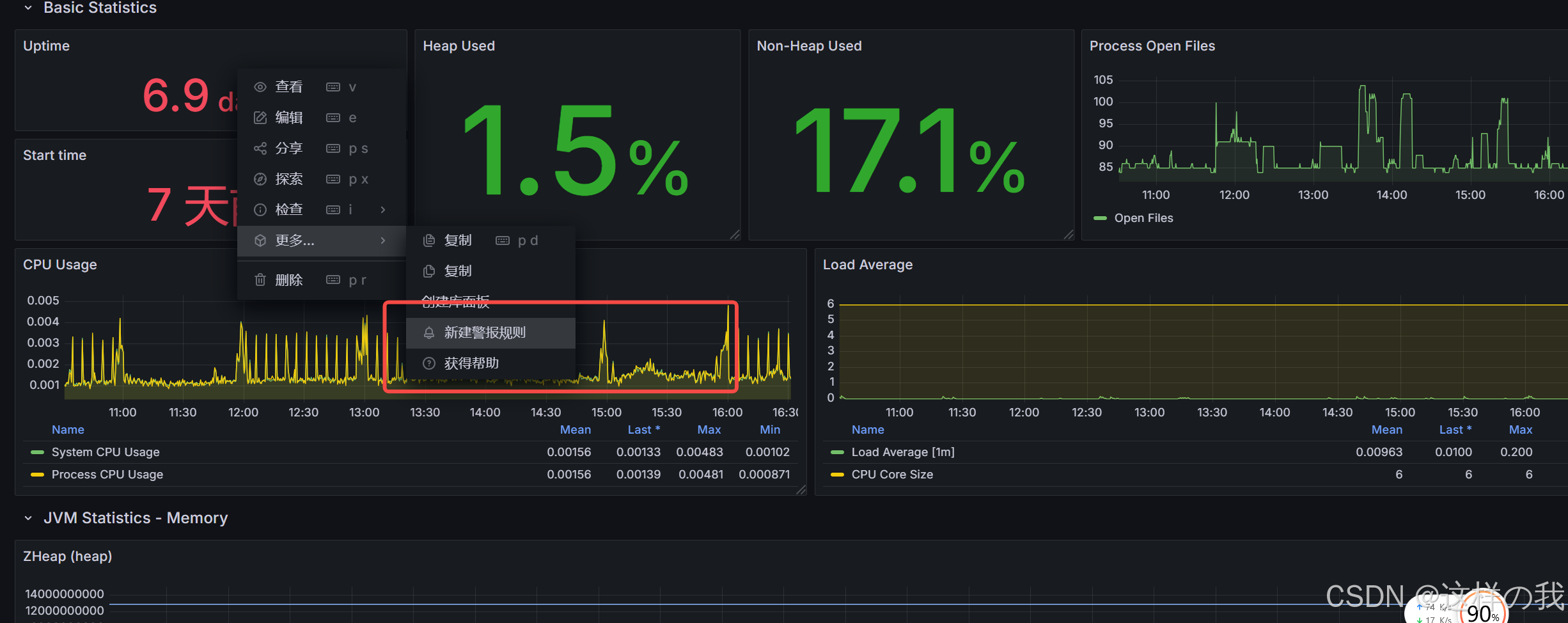
插件安装好后就可以登录 grafana 的前端界面来配置 zabbix 数据源了。登录 http://192.168.43.39:3000,如图。grafana集成zabbix的话需要去安装插件:grafana-cli plugins list-remote。注意:url填写 zabbix 的api 地址。这里不能错,否则就会出问题采集不到数据。需要安装这个插件:alexanderzobnin-z
获取通用配置wget https://raw.githubusercontent.com/grafana/loki/main/clients/cmd/promtail/promtail-local-config.yaml。获取官方通用配置wget https://raw.githubusercontent.com/grafana/loki/master/cmd/loki/loki-local-co
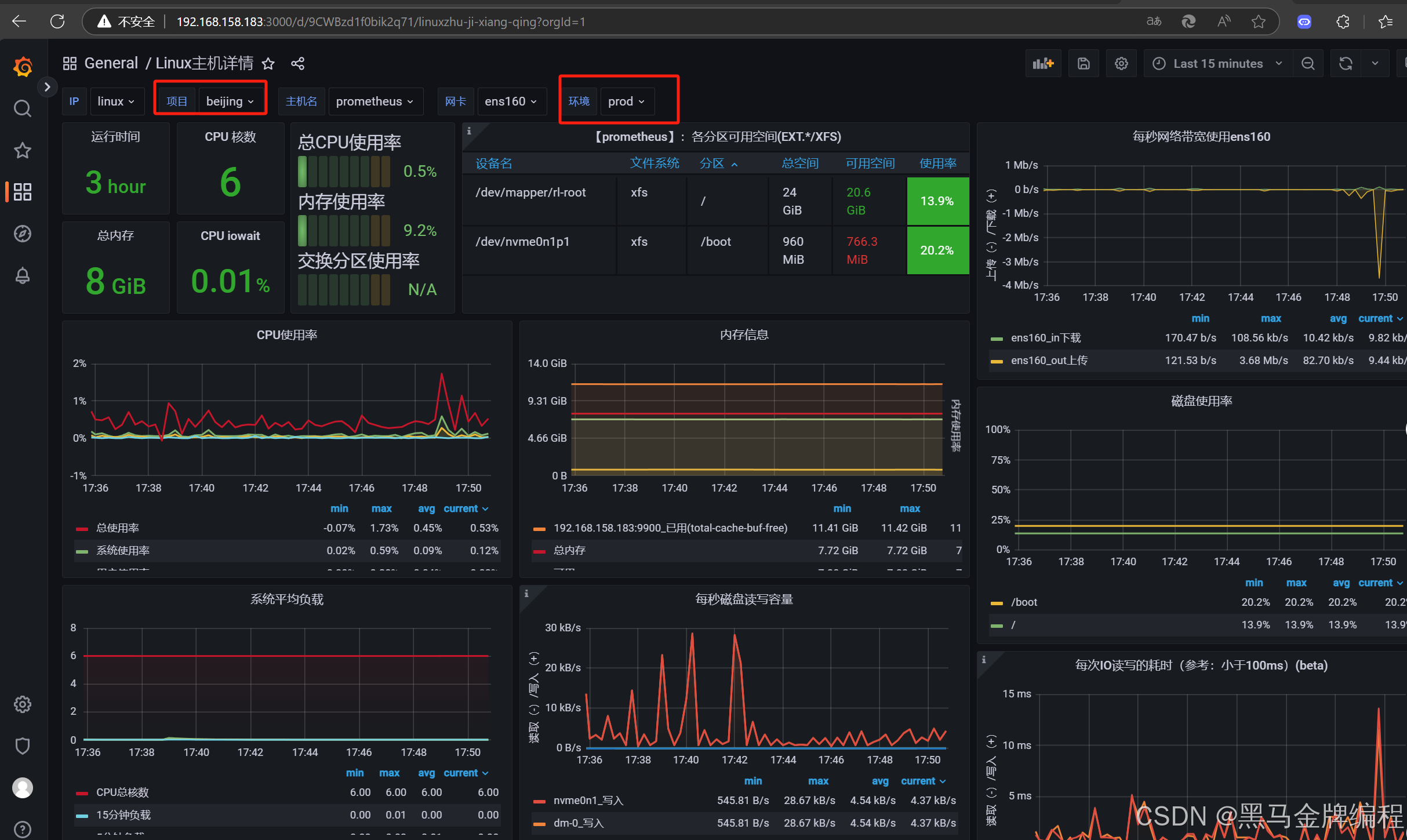
grafana: 前台 + 配置模板influxdb: 时序数据库 存储数据 根据时间进行数据存储influxdb: 版本 1.x 不建议用2.x启动influxdb1.x: influxd进入influxdb的客户端模式: influxjmeter来产生数据jmeter的**后端监听器**中配置 ---配置jmeter的数据写入influxbd数据库grafana的管理平台配置 -----gra
Grafana开源版本没有report功能,根据官方企业版本的Requirements声明,也使用grafana-image-renderer开源项目,实现report功能。
global:alerting:- targets:labels:介绍一下如下:scrape_interval: 15s #每隔15秒向目标抓取一次数,默认为一分钟evaluation_interval: 15s #每隔15秒执行一次告警规则检查,默认为一分钟scrape_configs指定的是prometheus要监控的目标,这里是整个prometheus的核心部分,在srape_config中
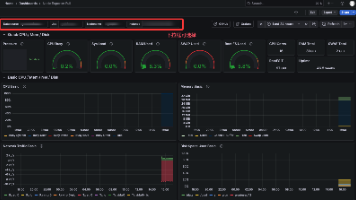
本文详细介绍了在Linux系统中搭建Prometheus监控系统和Grafana可视化平台的完整过程。主要内容包括:1)下载并配置Prometheus,创建专用用户和启动服务;2)部署node_exporter采集节点数据,配置多服务器监控;3)安装Grafana并进行服务配置。文档提供了详细的命令操作、配置文件修改说明及效果截图,最终实现通过Prometheus采集服务器指标数据,并通过Graf
Metrics 的类型如下:常用的如 Counter,写过 mapreduce 作业的开发人员就应该很熟悉 Counter,其实含义都是一样的,就是对一个计数器进行累加,即对于多条数据和多兆数据一直往上加的过程。Gauge,Gauge 是最简单的 Metrics,它反映一个值。比如要看现在 Java heap 内存用了多少,就可以每次实时的暴露一个 Gauge,Gauge 当前的值就是heap使用
注意:这里添加的一定要在 /opt/prometheus/prometheus.yml文件中操作,否则会导致后续prometheus中没有node节点,grafana表盘中无数据。点击Endpoint目标的值,再从exporter具体能抓到的数据,随便复制一个值就好,比如go_gc_pauses_seconds_count。访问:http://IP地址:3000,默认账号/密码:admin/adm
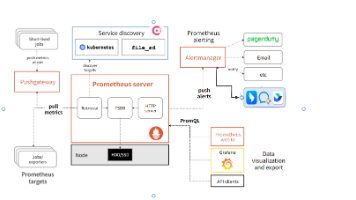
grafana:看板工具,所有采集的性能数据都会展示在这个看板上,官网:linkPrometheus: 监控系统,数据的采集、存储、查询等主要功能都是在它这里,参考文档:linknode_exporter:其是Prometheus的一个采集组件,可以用来采集机器上的数据,并暴露接口给Prometheus,以此将数据传过去。这是prometheus官网的架构图,可以参考这个看一下。
(使用 Values 文件)直接使用 helm install会采用 Chart 的默认配置。要自定义(例如设置持久化存储、配置抓取规则、修改 Grafana 密码等),你需要一个自定义的 values.yaml文件。编辑 custom-values.yaml文件,根据你的需求修改配置。
Prometheus监控主机资源情况, influxdb接收jmeter脚本执行信息.所有的图表都可以使用grafana的模版来展示.
【代码】Prometheus实战教程:k8s平台手动部署Grafana。
【代码】centos7安装zabbix6.0+安装grafana-9.5.2-1+设计监控图表+添加监控主机+汉化。
在不改变原配置的情况下使用java+prometheus自定义nginx的p99指标且暴露接口,并用grafana展示p99耗时数据。2.openresty需要自定的lua脚本、各种的配置和nginx-plus都会改变原先的nginx结构。1.nginx-prometheus-exporter和nginx-vts 两种是无法暴露这个指标的。
菜单路径:Administration -> Users and access -> Service accounts。
这里我使用的 springboot Apm ,直接填入id12900即可。使用garafana仪表盘创建dashboard,这里可直接使用别人写好的。然后把重采样结果取最后一组数据即可,判断最后一组数据是否未0即可。
http://192.168.174.128:9090服务器地址。右上角+导入仪表盘->添加8919模板ID->加载->加载。
除此之外,其他配置保持默认即可。
重置 Grafana 登录密码
监控平台包含基本组件:grafana、prometheus、node-exporter、alertmanager、loki、alloy,实现对服务器的监控,对Java应用的监控,对服务器异常的报警,对Java服务异常的报警,日志的抽取和查看
插件安装好后就可以登录 grafana 的前端界面来配置 zabbix 数据源了。登录 http://192.168.43.39:3000,如图。注意:url填写 zabbix 的api 地址。这里不能错,否则就会出问题采集不到数据。需要安装这个插件:alexanderzobnin-zabbix-app。需要添加zabbix和mysql数据源。
【代码】grafana使用。
摘要:本文介绍通过海康威视智慧商业地产管理平台API获取客流数据的方法。首先在系统管理中配置API网关并生成AK/SK密钥,然后编写Python脚本实现数据采集。脚本使用requests库发送POST请求,通过HMAC-SHA256签名认证,获取指定区域(J区)的客流统计信息(进/出客量)。最后将采集到的JSON数据接入Zabbix监控系统,创建两个依赖项分别提取进/出客量,并通过Grafana实
根据 tag 创建 git分支,git checkout -b 分支名 标签名。启动 grafana,通过。
请求总数 = vus * rps * durance(s)
本文介绍了使用kube-prometheus在Kubernetes集群中部署完整的Prometheus监控方案。基于Kubernetes v1.32.5环境,选择kube-prometheus release-0.16版本,部署内容包括:通过NodePort暴露Prometheus、Grafana和Alertmanager服务;为Prometheus启用basic-auth认证;配置多副本部署并集
摘要:用户在fluentd配置日志源和Elasticsearch后,发现Grafana无法查询日志记录,次日恢复但存在8小时时差问题。经排查发现Grafana默认使用浏览器时区,导致19点日志显示为3点。通过在grafana.ini配置时区参数后问题解决。该问题凸显了时区配置在日志监控系统中的重要性,需确保各组件时区设置一致。(150字)
grafana常见问题-时间多8小时问题
启动成功之后,前往网页输入:http:192.168.190.148:3000(http://本机ip:3000)A、pkill prometheus##终止Prometheus进程(因为第③步启动了Prometheus)E、systemctl status prometheus.service##查看Prometheus状态。D、systemctl start prometheus.servic
基于Prometheus+Grafana实现Linux操作系统的监控与可视化
Grafana是一个开源的度量分析和可视化工具,可以通过将采集的数据分析,查询,然后进行可视化的展示,并能实现报警。
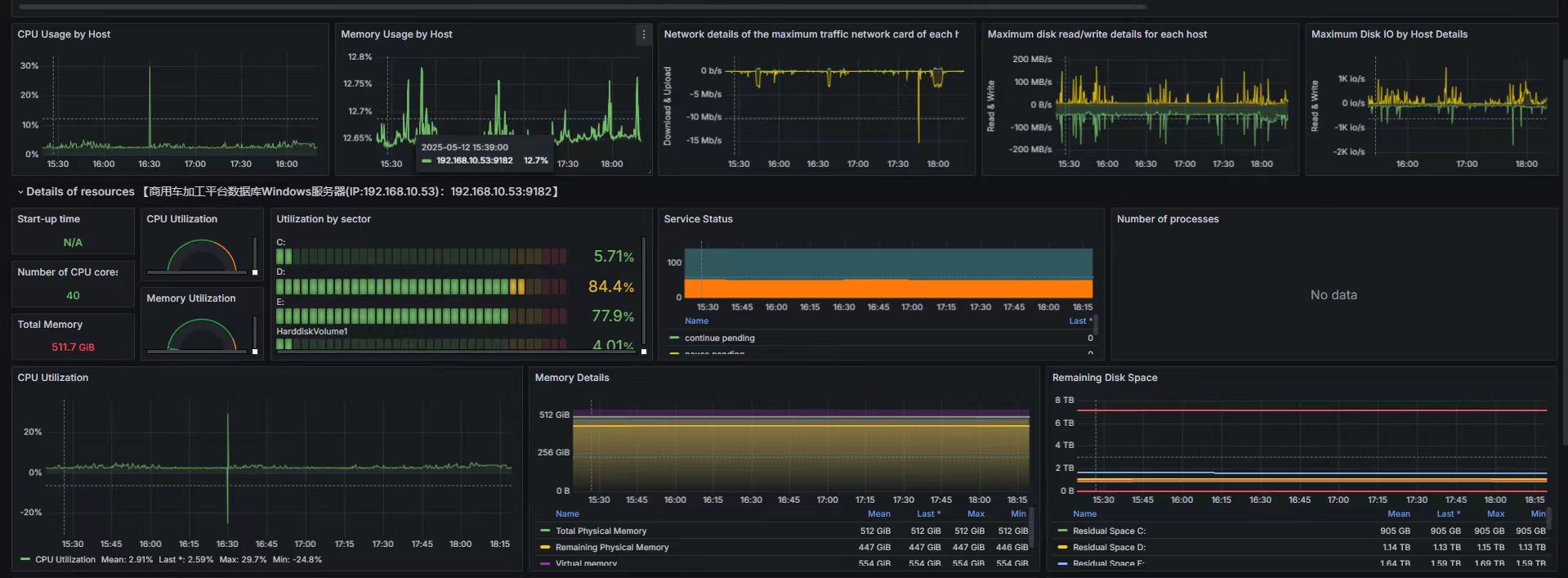
基于Prometheus+Grafana实现windows操作系统的监控与可视化
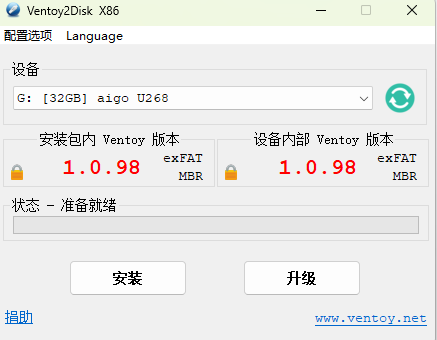
方法很简单,在电脑磁盘用ventoy-1.0.98,执行Ventoy2Disk.exe选择这个设备编号,之后就OK了。
服务器测试的核心类型:性能测试:评估响应时间、吞吐量(如TPS/QPS)、资源利用率(CPU/内存)安全测试:模拟SQL注入、DDoS攻击等,验证防御机制。可用性测试:检测系统持续服务能力(如故障切换、容灾恢复)。负载测试、压力测试、大量数据测试的区别:压力测试:施加远超正常负载(如10倍流量),探测系统崩溃点及恢复能力。负载测试:模拟正常业务流量(如日活用户并发),验证系统在预期负载下的稳定性
复制一份 defaults.ini 为 custom.ini。登录后需要重置密码, 充值密码后点击右上角头像的。点击 Add new data source。
Granfa 踩坑记录
【代码】Prometheus[2.33.3]grafana[12.3.1]监控安装。
这套监控功能还是挺强大的,就是Prometheus的表达式有点多。附上几个链接:Prometheus官方文档Grafana官方文档代码地址。
今天,我们将介绍如何通过Grafana的Polystat面板与腾讯云可观测平台实现深度融合,打造直观高效的云服务健康状态监控大屏。通过Grafana Polystat面板与腾讯云可观测平台的深度融合,我们成功构建了一套直观、高效、易用的云服务健康状态监控体系。在prometheus实例的集成中心里通过云监控启用所有云产品监控集成(包括CLB、COS、CVM、ES、Nacos、RabbitMQ、MQ
【代码】install grafana on windows。
示例规则groups:rules:for: 5mlabels:summary: "容器 CPU 使用率过高 ({{ $labels.container_label_com_docker_swarm_service_name }})"description: "{{ $labels.container_label_com_docker_swarm_service_name }} CPU 5 分钟以上
本文介绍了Grafana和Prometheus两大监控工具及其在Spring Boot应用监控中的应用。Grafana是一个开源的仪表盘可视化工具,支持多种数据源;Prometheus是一个时间序列数据库,专门用于系统监控。二者配合使用,Grafana通过查询Prometheus获取数据并可视化展示。文章详细说明了如何在Spring Boot项目中集成Prometheus,配置Grafana数据源
本文详细介绍了Prometheus+Grafana监控系统的部署流程。1) 内网集群的时钟同步配置,通过chrony实现NTP服务端与客户端的时间同步;2) Prometheus的安装部署,包括解压安装包、;3) Node-exporter,mysql-exporter的安装配置,用于收集服务器资源使用数据;4) 修改Prometheus配置关联Node-exporter;5) Grafana的安
面向对象:后端/架构/运维/平台工程团队,希望把“出了问题才看日志”升级为“分钟级定位与可量化治理”交付目标:一套可复制的可观测性平台(Metrics/Logs/Traces),配套埋点规范、仪表盘、告警与故障定位手册。
grafana
——grafana
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI硬件创业社区
AI硬件创业社区


 AI编程社区
AI编程社区