登录社区云,与社区用户共同成长
邀请您加入社区
时序数据正在成为物联网、工业互联网、车联网等领域的核心数据资产。如何高效管理海量带时间戳的数据?Apache IoTDB 给出了答案。本文面向零基础读者,带你从下载到运行,完成第一次数据写入,全程动手实操。
Apache IoTDB时序数据库性能测评(2026年) 本文对Apache IoTDB 1.3.6进行深度测评,结果显示其作为国产时序数据库在工业物联网场景表现优异: 1️⃣ 存储引擎:自研TsFile列式存储格式,支持10-20x压缩率,边缘设备可直接传输文件至云端 2️⃣ 写入性能:3600万点/秒吞吐量,P99延迟仅2.3ms,优于InfluxDB/TimescaleDB 3️⃣ 查询优化
本文介绍了 Apache IoTDB 的三种连接方式:JDBC 适合标准 Java 应用,Shell 适合快速测试,Java API 适合复杂业务场景。开发者可以根据实际需求选择合适的方式。通过灵活运用这些方法,能够高效地管理和分析时序数据。
`std::unique_ptr` | 独占所有权(Move Only)| 资源句柄传递|| `std::weak_ptr`| 观察共享资源(无计数)| 避免 `shared_ptr` 循环引用 || 2. `shared_ptr` 引用循环| 用 `weak_ptr` 打破循环链接|| `std::shared_ptr` | 共享所有权(引用计数)| 多线程共享资源|
C++开发如同建造摩天大楼:地基是核心语法,钢架是优秀设计模式,而创新思维则是持续推动向上发展的动力。不妨以螺旋木的双线成长方式进行:每周抽出两小时实验新技术,同时每季度重写某个模块,用最新C++特性重构旧代码就会发现:代码效率能提升30%,Bug自然减少一半。通过将技术讲解与实战案例结合螺旋式优化思维,本文旨在帮助开发者既能快速掌握C++核心要素,又能在开发中不断突破技术边界。明日的开发者是你今
Java逆向工程是指通过分析已编译的字节码文件(.class)来还原出近似源代码的过程。通过深入理解Java逆向工程的原理和工具,开发人员可以更好地保护自己的代码,同时在必要时也能有效地分析和理解第三方代码的实现逻辑。4. 语法糖消失:Lambda表达式、try-with-resources等语法糖被展开。### Java逆向工程:从字节码到源代码的转换。2. 第三方库分析:理解依赖库的内部实现机
摘要:本文介绍了一种使用Python csv模块解析IoTDB路径的方法。IoTDB路径如root.database.123gr``o.up.device需要特殊处理,其格式类似CSV。通过自定义IOTDB_PATH_Dialect类指定分隔符为点号、引号字符为反引号等参数,再利用csv.reader即可正确解析包含特殊字符的路径。示例代码成功将三种不同格式的路径分割为组件列表,验证了该方法的有效
集成后开发者可直接使用 Spring 风格的操作模板进行时序数据的读写,避免了繁琐的底层 JDBC 连接管理,让开发者能专注于业务逻辑,显著提升代码质量和开发效率。:借助 SpringBoot Starter,开发者仅需在配置文件中添加简单参数,即可自动完成数据源配置与模板 Bean 的初始化,大幅降低了项目集成的复杂度。开发者仅需引入依赖,即可使用 IoTDB 功能或模块,显著降低时序数据场景下
IoTDB 与 TsFile Skills 是一次面向“被理解”的尝试,协变量预测与 AINode 则是走向“内生智能”的探索。从连接,到理解,再到内生智能 —— 这正是数据库在 Agent 时代完成角色升级的三条关键路径。未来,也许不是所有数据库都要变成 Agent,但所有数据库都需要适配 Agent 时代的需求。如何让 AI 突破 “只会调用、不懂逻辑” 的瓶颈,真正准确理解时序数据库的核心逻
为AI提供时序数据(时间序列数据)的存储和查询能力,专为物联网场景设计。
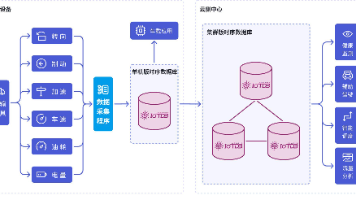
组件角色定位通俗比喻地基与总管像是房子的地基和水电总闸,提供了运行环境和基础能力。对外接口像是大门和邮筒,专门负责和外部特定的系统(MQTT 服务器)收发信件。内部流水线像是屋内的传送带和处理工人,负责把大门收进来的信件进行筛选、加工和流转。通过这三者的结合,可以轻松构建出一个既能与物联网设备通信,又能在内部高效处理业务逻辑的消息驱动应用。
进入2026年,时序数据已成为企业数字化转型中最具价值的核心资产之一。全球时序数据库(Time-Series Database, TSDB)市场持续蓬勃发展,预计到2031年,市场规模将达到7.76亿美元 。面对全球已知的超过41款时序数据库产品,如何进行科学、高效、前瞻性的技术选型,已成为企业首席技术官(CTO)、架构师和数据工程师面临的关键挑战。
本手册旨在提供Apache IoTDB的完整部署指南,重点关注AINode机器学习集成与Kubernetes集群管理。Kubernetes则提供容器化部署和集群管理能力,确保系统高可用和弹性伸缩。手册结构清晰,逐步指导您完成部署、配置和验证过程,内容基于官方文档和最佳实践,力求真实可靠。其中 $y_i$ 是真实值,$\hat{y}_i$ 是预测值,$n$ 是样本数。这里 $\beta_0$ 是截距
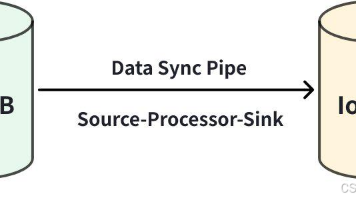
Apache IoTDB的Pipe功能提供高效时序数据同步方案,采用"抽取-处理-发送"三段式架构,支持跨节点、跨区域毫秒级数据复制。通过SQL语句声明式配置同步任务,可灵活选择同步范围(默认同步新写入数据)。任务管理包含创建、启动、停止、删除等操作,系统支持自动重启异常任务。元数据同步需满足特定协议要求并关闭自动创建功能。插件扩展机制使架构更灵活,支持自定义数据同步场景。该方
TDengine 中的流计算,功能相当于简化版的 FLINK , 具有实时计算,计算结果可以输出到超级表中存储,同时也可用于窗口预计算,加快查询速度。
前言上篇教程介绍了 Apache IoTDB 处理时序数据时,能够实现的部分具体功能和具体的操作命令,包括数据导入、基本查询、和聚合查询。本篇将继续介绍 Apache IoTDB 可实现的其他功能和相关 SQL 语句命令,包括数据的写入、删除、导出、元数据操作和时区设置的注意事项。1数据写入、删除与导出1.1插入数据物联网场景下,元件产生数据将自动写入,但有时候,如果过去的一些数据需要修改,可以使
Iotdb时序数据库
大数据时序数据库选型是企业在数字化转型中的重要决策。本文从架构设计、生态集成、性能测试三个维度深入分析了时序数据库选型策略,重点探讨了LSM树、B+树等存储引擎特点,以及与Spark、Flink等大数据组件的集成方案。通过制造、交通等领域的实战案例,展示了时序数据库在工业物联网和智慧城市中的典型应用。最后提出四阶段选型方法论,强调需要根据数据规模、访问模式和生态兼容性选择合适方案,并指出AI原生、
DBeaver连接IoTDB
IoTDB凭借本土化部署优势、行业协议深度适配及卓越的时序处理性能,特别适合受合规性约束的能源、工业、交通等领域。在选型过程中,建议结合具体业务场景的$ \frac{\text{设备规模}}{\text{数据精度}} $比值进行压力测试,可参考官方提供的基准测试工具IoTDB-Benchmark获取量化对比数据。
出自物联网新人之手,有什么不对的还请赐教,欢迎感兴趣的小伙伴提出自己宝贵的意见。
本文介绍了Apache IoTDB在工业物联网场景下的数据删除策略。IoTDB针对时序数据管理提供了从单点删除到企业级生命周期管理的完整解决方案,包括单传感器精准删除、多传感器批量删除、TTL自动清理、时间分区管理等核心功能。文章详细解析了各类删除操作的SQL语法和使用场景,同时强调了权限控制和操作审计等安全机制。通过合理配置数据删除策略,可有效降低存储成本、提升查询性能,实现从数据管理到数据治理
12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。我们邀请到天谋科技联合创始人、CTO 乔嘉林参加此次大会,并做主题报
Apache IoTDB:工业物联网时序数据库的理想选择 在工业物联网场景中,时序数据库选型需要综合考虑架构设计、性能、生态集成、可靠性和成本等因素。Apache IoTDB作为专为工业物联网设计的时序数据库,具备端边云协同架构、高性能写入与高压缩比、贴合工业场景的数据模型等优势。其单机版资源占用低,支持断网续传;分布式集群可实现水平扩展和高可用。IoTDB与主流工业协议和大数据工具无缝集成,并提
欢迎业内专家、合作伙伴到场,深入交流核电数字化、智能化实践,探讨时序数据技术如何赋能行业安全运营、降本增效与自主创新。通过时序数据库 IoTDB 与时序智能服务平台 TimechoAI 深度融合,打造全栈解决方案,全方位支撑核电站安全监测、故障预警、智能运维与数字化转型。💡核电作为清洁能源的核心力量,是保障能源安全、实现“双碳”目标的重要支撑,而数字化、智能化转型已成为推动核电行业高质量发展的必
Apache IoTDB 全场景部署:基于 Apache IoTDB 的跨「端-边-云」的时序数据库 DB+AI
iotdb
——iotdb
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI Agent技术社区
AI Agent技术社区






 DAMO开发者矩阵
DAMO开发者矩阵