- @u012121721
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文针对关联分析技术进行研究,探讨了其在数据挖掘中的应用及重要性。通过详细阐述关联规则算法,分析了算法原理及其在实际场景中的优化策略。研究结果表明,关联分析能有效挖掘数据间的潜在关系,为决策提供有力支持,具有较高的实用价值和广泛的应用前景。
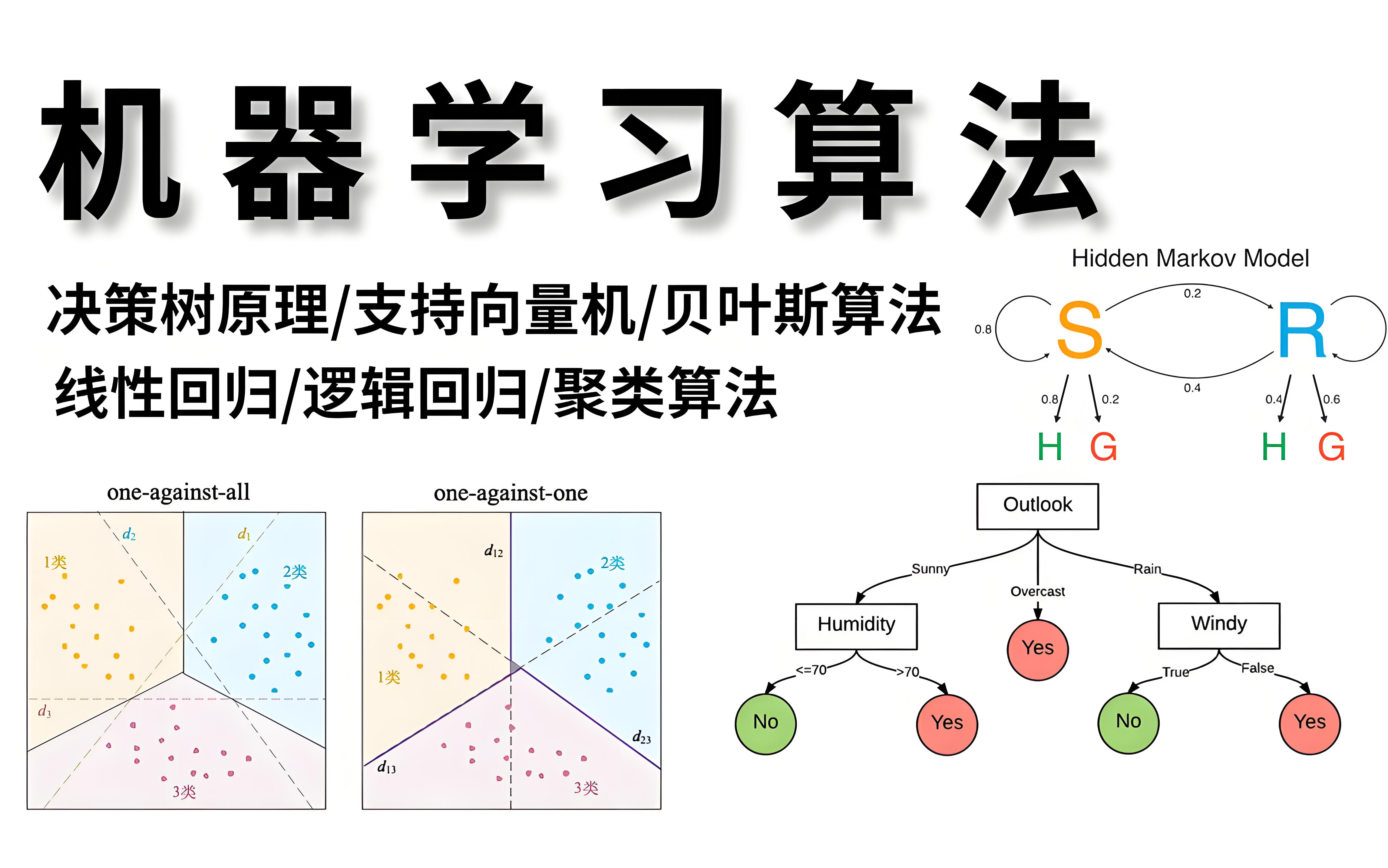
数据分析是挖掘数据价值、驱动决策优化的重要工具,而数据分析思维则是高效分析和解读数据的核心能力。本博客将探讨数据分析的本质、常见工具及其在实际应用中的价值,同时深入解析如何培养数据分析思维,助力读者提升数据驱动决策能力,让数据真正成为业务增长与创新的引擎。

数据库是用于存储和管理数据的系统,常见类型包括关系型数据库(如MySQL、PostgreSQL)和非关系型数据库(如MongoDB)。在SQL中,数据表的创建使用 CREATE TABLE 语句,插入数据用 INSERT INTO,查询数据常用 SELECT。数据查询涉及七个重要关键词:SELECT(查询)、FROM(指定表)、WHERE(筛选条件)、GROUP BY(分组)、HAVING(筛选分

业务分析模型是解读数据、指导决策的重要工具,涵盖多种方法:对比分析法通过横向或纵向比较揭示差异;漏斗分析法追踪用户行为路径,识别转化瓶颈;矩阵分析法用于分类评估,如波士顿矩阵;公式分析法量化关键指标关系;多维度拆解法从时间、地域、用户等角度细分问题。综合运用这些方法,可全面洞察业务表现,精准定位问题,优化运营策略,提升企业竞争力。

数据分析是挖掘数据价值、驱动决策优化的重要工具,而数据分析思维则是高效分析和解读数据的核心能力。本博客将探讨数据分析的本质、常见工具及其在实际应用中的价值,同时深入解析如何培养数据分析思维,助力读者提升数据驱动决策能力,让数据真正成为业务增长与创新的引擎。
数据库是用于存储和管理数据的系统,常见类型包括关系型数据库(如MySQL、PostgreSQL)和非关系型数据库(如MongoDB)。在SQL中,数据表的创建使用 CREATE TABLE 语句,插入数据用 INSERT INTO,查询数据常用 SELECT。数据查询涉及七个重要关键词:SELECT(查询)、FROM(指定表)、WHERE(筛选条件)、GROUP BY(分组)、HAVING(筛选分
三种数据标准化

文章详细介绍了YOLOv5的架构、训练过程及优化策略,并通过实验验证了其在不同场景下的检测性能。研究结果表明,YOLOv5在速度和准确性上具有显著优势,为实时物体检测提供了高效解决方案。

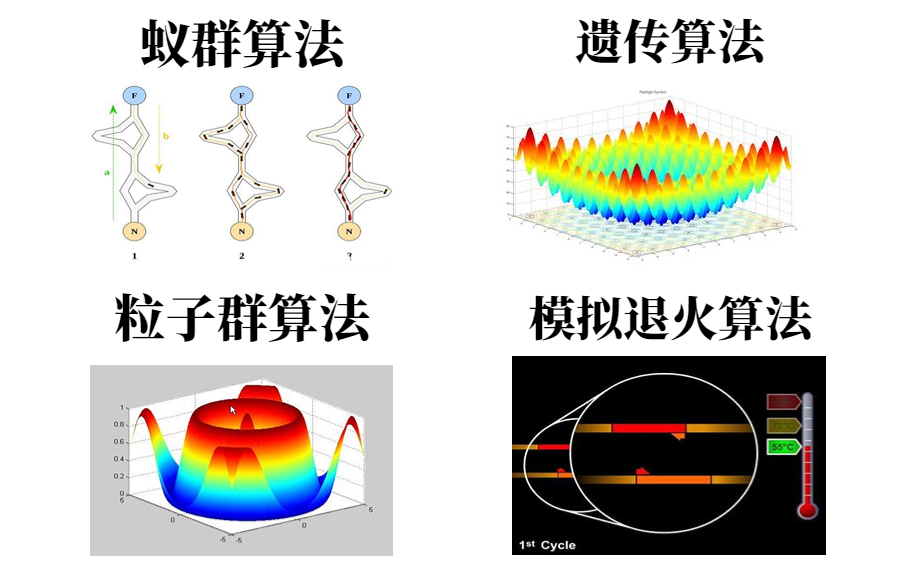
蚁群算法(Ant Colony Optimization, ACO)是一种模拟自然界蚂蚁觅食行为的优化算法,广泛应用于解决组合优化问题。通过信息素的传递与挥发,蚂蚁在解空间中探索并寻找最优解。该算法具有全局搜索能力和较强的适应性,能有效处理TSP、排程、路径规划等问题。通过不断迭代更新信息素,蚁群能够渐进式地优化解,逐步收敛至全局最优或近似最优解。
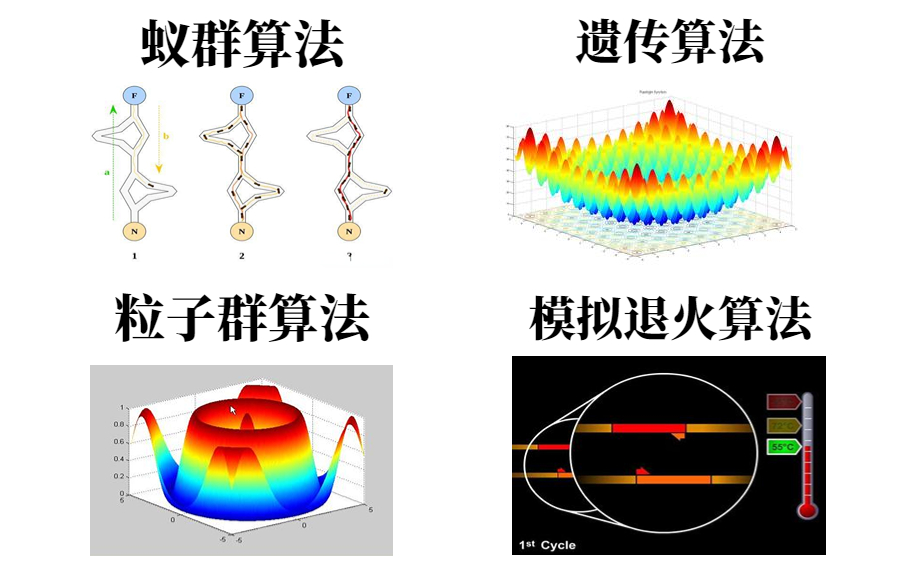
粒子群优化算法(PSO)是一种基于群体智能的全局优化算法,模拟鸟群觅食行为,通过粒子在解空间中的迭代更新,实现最优解搜索。该算法具有计算简单、易于实现、收敛速度快等特点,广泛应用于函数优化、神经网络训练、路径规划等领域。本文介绍了PSO的基本原理、求解过程及改进方法,并探讨其在复杂优化问题中的应用与优势。