- @DK_Allen
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
技术咨询
摘要:AKS MCP Server是基于Azure Kubernetes Service的标准化AI模型接口服务,深度集成Azure OpenAI(如GPT-4),提供开发/生产双模式支持。其核心优势包括Kubernetes原生扩展性、Azure服务无缝对接及5ire网络可选扩展,但需Azure账户且配置较复杂。适用于快速测试AI应用原型或生产级部署,尤其适合已使用Azure生态的团队实现高效AI

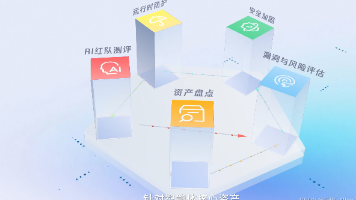
火山引擎发布大模型安全测评平台和智能体安全管理平台,全面保障智能体全生命周期安全。测评平台基于TC260标准提供5大类31项安全检测,30分钟完成智能体检并输出合规报告。安全管理平台通过资产盘点、漏洞评估和提示词加固三大能力,实现99%+攻击拦截率。已应用于汽车、金融等行业,帮助客户显著降低风险项,提升安全防护能力,为智能体合规落地提供保障。
摘要:大模型时代面临新型安全威胁——Prompt注入攻击,AI客服系统可能被恶意指令诱导泄露敏感数据。研究揭示攻击者通过直接或间接方式注入精心设计的指令,利用AI对文本的依赖性突破安全限制。金融行业尤为脆弱,需构建全方位防御体系,包括数据净化、权限管理、行为监控等措施。专家警告,传统安全思维已不足以应对AI特有的"可被说服"特性,必须重新审视AI系统的安全框架。(149字)

OpenClaw是一个工程化能力极强、设计思想前卫的开源AI智能体项目。它通过精巧的模块化解耦、本地优先的隐私设计、强大的扩展能力和活跃的社区生态,向我们展示了AI从“回答问题”到“执行任务”的可行路径。然而,它目前的高门槛、高成本、稳定性不足以及突出的安全风险,决定了它更适合技术爱好者的深度把玩、有专门团队维护的企业探索,以及在隔离环境下的特定任务自动化。对于普通用户,它远未到可以无脑安装、放心

本文系统梳理了当前主流的大模型推理部署框架,包括vLLM、SGLang、TensorRT-LLM、Ollama、XInference等。vLLM基于PyTorch,采用PagedAttention和ContinuousBatching技术,适合高并发企业级应用;SGLang通过RadixAttention优化缓存复用,擅长多轮交互场景;TensorRT-LLM由NVIDIA深度优化,在GPU上性能

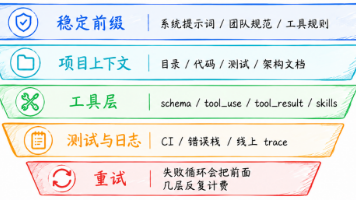
摘要: 随着AI编程工具的普及,Token消耗激增成为开发者面临的痛点,尤其在复杂任务中,上下文膨胀、工具调用和领域知识加载导致账单失控。本文从工程角度提出十项优化策略:1)清理无关会话历史,保留关键摘要;2)建立代码导航机制,减少无效搜索;3)复杂任务先规划,避免返工;4)按需分配工具集;5)过滤日志/测试噪声;6)利用PromptCache复用稳定前缀;7)分层使用模型(小任务用小模型);8)
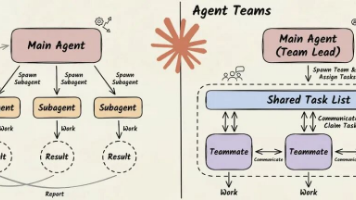
文章摘要:本文探讨了AI多代理系统的设计原则,区分了两种核心范式:子代理(隔离并行)和代理团队(协作协调)。子代理适用于可并行化的独立任务,而代理团队适合需要持续协商的复杂工作。作者提出五种编排模式(提示链、路由、并行化、协调者-工作者、评估者-优化者),并强调应根据任务上下文而非角色进行系统设计。关键建议包括:从简单代理开始,仅在明确需求时增加复杂性;避免常见失败模式(任务模糊、验证不足、成本失
AI系统演进:从单一模型到多智能体协同,Orchestration成为关键指挥者 过去两年,大模型从单一问答机器人发展为多智能体协同的"数字团队"。复杂任务被拆解为规划、检索、编码、测试等环节,由不同Agent分工完成。但随着Agent数量增加,传统固定流程(Workflow)暴露出协调混乱、重复执行等问题,导致效率下降。 为解决这一挑战,**Orchestration(编排)
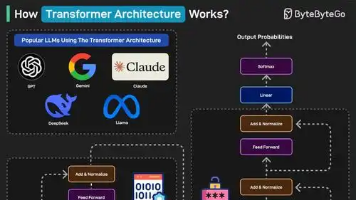
摘要:Transformer是当前大模型(如ChatGPT、Gemini等)的核心架构,其革命性在于通过自注意力机制(Self-Attention)全局理解文本关系,解决了传统RNN/LSTM的长距离依赖和训练效率问题。它将文本拆分为Token并编码为向量,通过Query/Key/Value机制动态分配注意力权重,结合位置编码保留顺序信息。Encoder负责理解输入,Decoder负责生成输出,而
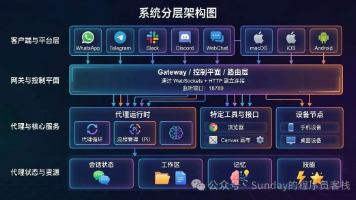
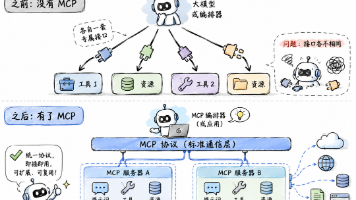
因为 OpenClaw 从来就不是一个只会聊天的机器人。它背后是 一个长期运行的 Gateway,是一套真正会处理 session、调 tools、接 channels、管 nodes、写 memory 的 Agent 系统 。你越把它当成AI 操作层来看,就越能理解它为什么会有这么大的争议。所以这篇文章我真正想说的,不是 OpenClaw 能不能用。