登录社区云,与社区用户共同成长
邀请您加入社区
Linux作为服务器、云计算、嵌入式开发和数据科学领域的核心操作系统,掌握其命令行操作是每个技术人员的必备技能。本文将带你从零开始,系统学习Linux命令的基础知识、常用操作和实用技巧。
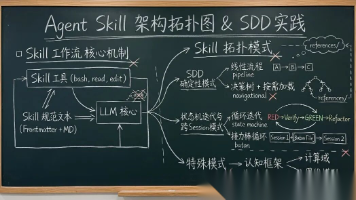
Skill 是 Claude Code 扩展体系中最灵活的一层。一个 Skill 就是一个 Markdown 文件,不需要定义工具权限、不需要管理会话状态——它只是在你调用时注入一段领域知识或操作指令。我在下积累了 27 个 Skill,经过反复迭代,总结出 4 种通用设计模式。每种模式解决一类问题,学会之后你也能在 30 分钟内写出自己的 Skill。
摘要: Codex Beacon 是一款专为 Windows 设计的轻量悬浮工具,用于实时监控 Codex 任务状态,减少频繁切换窗口的干扰。它通过本地 Hook 精准获取任务进展、等待审批或完成状态,并以颜色区分(青蓝/琥珀/绿/红)。支持查看最近任务记录,点击跳转回原对话。工具保持简洁,默认折叠置顶,不替代 Codex 核心功能。基于 React + Tauri 开发,开源且无需云端中转,适合
让 OpenAI Codex 在执行任务时把子任务"交接"给 WorkBuddy(生成文档 / PPT / 数据分析 / 研究报告等)。
当 AI Agent 从"能对话"进化到"能干活",Skill(技能包)就成了决定其执行质量的关键基础设施。它不是简单的 Prompt 堆砌,而是一套让 LLM 在特定场景下"知道该做什么、知道怎么做"的知识注入体系。
Mozilla/5.0 (Tablet; OpenHarmony 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 ArkWeb/4.1.6.1360Browser/1.1.30
服务器上的cursor同步本地插件
写法:cursor:url(images/arrow.cur),auto; /* auto是当自定义图标不起作用时鼠标的状态*/也可写:cursor: url(mouse-notexist.cur), url(vote.gif), auto;cursor:url(images/logo.cur) 100 20,auto; /* 100 20 是cursor 的坐标*/
FisherAI是一款Chrome浏览器的AI大模型插件,可以利用各种大模型为网页提供自动摘要、网页翻译、视频翻译等功能。AnythingLLM可以帮助用户在本地或云端搭建个性化的聊天机器人系统,将本地文档、资源或内容转化为大语言模型在聊天过程中可以用作参考的上下文(RAG),可用于文档处理、代码生成、创意写作、数据分析、项目管理等多种场景,是一款功能强大、易用、可本地部署的大模型集成应用平台。直
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。🧡AI职场汇报智能办公文案写作效率提升教程 🧡专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的
自动输入账号密码是一种自动化过程,使用编程代码代替我们手动输入账号和密码。我们可以使用Python编写脚本,模拟手动输入账号和密码的过程。这将大大简化我们的日常工作并提高我们的效率。现在您知道如何使用Python自动化输入用户名和密码。虽然这对于每个人来说并不适用,但是如果您是一个活跃的互联网用户或开发人员,那么自动输入用户名和密码将是很好的技巧,帮助我们提高工作效率。但是,在使用工具时,您需要注
《架构师之路600篇里程碑》摘要:本文总结了600篇架构师系列文章的完整学习路径,分为入门、计算机基础、软件开发方法论和架构设计核心四个阶段。重点回顾了架构设计原则、分布式系统理论和云原生技术等核心知识点。作者分享了"理解原理→对比记忆→实践巩固→教学相长"的学习方法论,并为备考系统架构设计师考试提供详细建议。最后展望了云原生2.0、AI工程化和安全领域的技术趋势,为读者指明持续学习方向。
Claude Code 内置了多种 Agent 类型:general-purpose、Explore、Plan、等等。但内置的 Agent 是通用的——它不懂你的项目规范、不懂你的技术栈、不懂你的团队习惯。自定义 Agent就是解决这个问题——定义一个专属角色,让它成为你项目的"专家"。Agent 定义文件放在│ ├── backend-developer.md # 后端开发 Agent│ ├──
首先确保系统依赖齐全,安装和相关开发工具。尝试安装预编译的grpcio二进制包,以避免编译。尝试使用兼容的grpcio版本,尤其是使用较低版本如1.51.x。如果依然有问题,可以考虑使用 Python 3.10 或更低版本,以提升兼容性。这应该能够帮助您解决编译问题并成功安装grpcio。
addCommentAndUpdateProcessStatus 这个方法是添加审批意见和更新流程状态,由于流程状态没有,我这里扩展了一张表,状态主要有审批中,驳回,暂存,转办,撤回,终止等等状态。AddChildExecutionCmd 添加一个流程实例下面的执行实例。DeleteChildExecutionCmd 删除执行实例。DeleteTaskCmd 删除任务命令。JumpActivity
nginx独立增加端口
二、安装python3.7.2。四、安装chrome浏览器驱动。三、安装chrome浏览器。一、安装jdk1.8。
自动生成GPG密钥对。列出当前系统中的GPG密钥。导出生成的GPG公钥和私钥。自动删除生成的GPG密钥。本文介绍了如何通过Bash脚本自动化GPG密钥的生成、导出和删除操作。通过这种方式,开发者和系统管理员可以有效地简化密钥管理流程,提升工作效率。如果你需要频繁生成和管理GPG密钥,推荐将此脚本纳入你的工具集。
在 macOS 上安装 Nginx 有几种常用方法,最推荐使用包管理器,因为它简单、方便管理。
涵盖了Linux系统管理的大部分常用命令,掌握这些命令将大大提高效率。:从基础命令开始,逐步学习高级用法。:不仅记住命令,还要理解其工作原。:在虚拟机或测试环境中多练习。
A variable is a standby where you assign some value for later use for your code. The declare command in Linux bash scripts is used to declare shell variables and functions. It sets their attributes an
linux服务器某些情况下,需要使用不同版本的jdk,写了一个切换器。
如果你希望每次输入一个简短的命令就能看到文件列表,可以在你的.zshrc文件中添加自定义别名。在文件末尾添加以下行(你可以起个新名字,比如glggs# 显示图形化列表 + 文件统计# 或者如果你想看更详细的改动内容 (Patch)使用--stat使用使用-p(patch)在查看列表时,如果内容太长进入了分页器(less),你可以按jk上下滚动,按q退出查看。
在生产环境中对接 baodanbao.com.cn 霸王餐API时,常遇到接口突然变慢、CPU飙升或返回异常数据等问题。Arthas 作为 Alibaba 开源的 Java 诊断工具,可在不重启、不修改代码的前提下实时监控、追踪和分析线上应用。通过上述 Arthas 命令组合,可在分钟级内完成从现象发现、根因定位到验证修复的完整闭环,极大提升对 baodanbao.com.cn 霸王餐接口线上问题
【代码】How to Run a Bash Script in Linux。
docker-compose文件属性,插值
本文深入解析Linux进程信号的保存与阻塞机制。首先明确三个核心概念:信号递达(实际处理动作)、信号未决(产生但未处理状态)和信号阻塞(暂时屏蔽信号)。通过对比阻塞与忽略的区别,指出阻塞是延迟处理而忽略是主动丢弃。接着剖析内核数据结构,展示信号在PCB中的存储方式,包括阻塞信号集(block位图)、未决信号集(pending位图)和信号处理函数表。通过具体示例说明不同信号状态下的处理流程,帮助读者
curl是一个强大的命令行工具,用于传输数据,支持多种协议(HTTP、HTTPS、FTP 等)。
本文摘要总结了Linux系统管理的核心命令,涵盖文件和目录管理、文本处理、系统信息查询、网络配置、软件包管理等多个方面。重点包括:基础文件操作(ls/cp/mv/rm)、文本处理工具(grep/sed/awk)、系统监控命令(top/ps/df)、网络工具(ping/ssh/curl)以及用户权限管理(sudo/chmod)。文章还提供了实用技巧如命令历史搜索、快捷键使用建议,并强调实践练习的重要
命令说明示例ls列出目录内容ls -lcd切换目录cd /homemkdir创建目录mkdir testrmdir删除空目录rmdir testtouch创建空文件rm删除文件或目录pwd显示当前目录pwdcp复制文件或目录mv移动或重命名文件mv old new多练习基础命令,理解每个命令的常用选项。掌握 Shell 编程基础,能编写自动化脚本。理解权限、进程、网络配置,这是系统管理的核心。善用
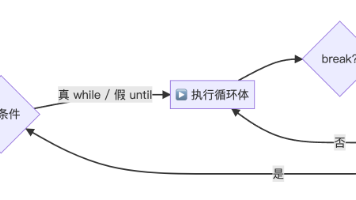
本文摘要介绍了Bash脚本编程中的循环控制、函数以及Linux进程管理核心知识。主要内容包括:1) while/until/for循环及break/continue控制语句的使用场景;2) 函数的定义与调用方法;3) 进程基本概念(PID、状态、优先级)及查看命令(ps/top/pstree);4) 进程信号处理(SIGHUP/SIGKILL等)和前后台作业管理。通过生活化类比和实用脚本示例,帮助
环境变量(environment variables)是操作系统中用来指定运行环境的动态参数,本质上是 “键值对” 形式的字符串(如程序运行时的路径查找(如PATH变量);用户身份与工作目录的定义(如HOMEUSER变量);编译器 / 解释器的配置(如CCPYTHONPATH变量);自定义程序的运行参数(如自定义变量)。举个生活中的例子:环境变量就像公司的 “规章制度”—— 新员工(新进程)入职后
本文介绍了Spring Boot中自定义错误页面的方法,包括404/500页面定制和ErrorController的实现。Spring Boot默认提供BasicErrorController处理错误,开发者可通过三种方式定制:静态错误页面、自定义ErrorController或使用@ControllerAdvice。文章详细解析了错误处理流程,并针对不同场景(Web应用、REST API等)给出
使用实现了我的目的,但是使用却没有成功运行脚本,这是为什么呢?
如果你是直接连接显示器到 Orange Pi 的 HDMI 接口,看到的是黑色背景的,那么printf出现方块是因为该界面缺乏中文字库渲染引擎。在没有图形桌面(GUI)的情况下,安装并配置fbterm是最经典的解决方案。
不仅仅是一个命令,它代表着一种工程文化的转变从个人到团队:你的代码不再只是你的代码从结果到过程:重视代码的质量和可维护性从命令到协作:审查不是找茬,而是共同进步正如一位前辈所说:“Code Review不是门槛,而是阶梯。每一次审查,都是你代码质量的跃迁。现在,当你再执行这个"魔法"命令时,希望你看到的不仅是一个Git操作,而是一个专业开发者对代码的敬畏之心。延伸阅读Gerrit官方文档如何写好C
Linux内核调度器采用双时钟设计,运行队列(runqueue)维护了clock(墙上时钟)和clock_task(任务时钟)两套时间基准。clock记录物理CPU时间,用于负载均衡和全局统计;clock_task仅统计任务实际执行时间,用于公平调度和资源计费。这种设计能准确区分CPU空闲与工作状态,是支持高吞吐和低延迟任务的关键基础设施。通过动态追踪和可视化工具可观察两者的差异,该机制在云原生计
Linux Idle调度机制是系统能效优化的关键技术。本文深入解析了Idle调度类作为最低优先级"守门人"的特性,详细拆解了从do_idle循环到CPUIDle框架的完整路径,包括C-state选择策略(menu/teo/ladder)和硬件抽象层实现。通过工具集(turbostat、ftrace等)和实际案例(云数据中心、笔记本续航等),展示了如何诊断"CPU利用率
PSI(压力停滞信息)是Linux内核提供的一种新型资源监控机制,它通过量化任务因等待CPU、内存或IO资源而停滞的时间占比,更准确地反映系统资源竞争状况。相比传统利用率指标,PSI能直接衡量资源竞争对业务延迟的影响,帮助开发者精准定位性能瓶颈、预防系统故障。本文详细介绍了PSI的核心概念、监控方法和实际应用场景,包括基础监控脚本、cgroup级别监控、智能OOM预防等实用方案。PSI机制特别适用
本文深入解析了Linux内核CPU时间统计机制,重点介绍了用户态(utime)和内核态(stime)时间的记录方式,以及自愿(nvcsw)与非自愿(nivcsw)上下文切换的区分方法。通过C语言和Python代码示例,演示了如何读取/proc文件系统获取进程CPU时间统计和上下文切换信息,并提供了pidstat、perf等专业工具的使用方法。文章还分析了CPU时间统计在云原生计费、数据库优化和实时
为什么要分错误和异常?Java 区分 Error 和 Exception,是为了明确:哪些问题程序可以处理,哪些问题必须放弃。处理不了可以通过代码处理为什么要分成运行时异常和编译时异常?编译时异常本身不是在编译阶段发生的,只是编译器在提醒你“调用这个方法可能会抛出异常,你必须处理它”也就是java在设计时,提示开发者代码可能会出现这些错误。Java 没有把所有异常都设计成编译时异常(Checked
find是 Linux/Unix 系统中最强大、最灵活的文件搜索工具。与locate(基于数据库)不同,find是,因此它能找到最新的文件,但也相对较慢。以下是find命令的全方位详解,从基础语法到高级用法。
chrome
——chrome
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 AI编程社区
AI编程社区





 智能体开发者社区
智能体开发者社区

 HarmonyOS开发者社区
HarmonyOS开发者社区







 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区