




- @m0_61864577
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
背景: 我想在GPU上运行AscendSpeed框架,因为没有torch_npu、deepspeed_npu,又不想一个个注释掉方法:

自动化收集多个AI助手的回答标准化输出为Markdown格式,方便阅读和存档集成最终用Claude生成综合报告整个过程只需要你手动登录一次,之后就可以反复运行脚本,快速获取多方观点。希望这个教程对你有所帮助,你也可以根据自己的需求修改脚本,适配更多AI平台。

本文展示了如何利用AI(以Claude Code为例)实现从需求到发布的软件开发全流程自动化。通过一个待办事项API案例,演示了AI如何自动完成代码编写、测试生成、CI/CD配置及发布部署等环节。关键步骤包括:1)在GitLab搭建基础环境;2)编写清晰AI提示词明确技术栈和功能需求;3)AI自动生成完整项目结构、文档及测试代码;4)配置GitLab Runner实现持续集成;5)最终自动打包并发
文章摘要: MCP(模型上下文协议)让AI助手Claude具备连接外部工具的能力,实现新闻搜索、代码管理、笔记整理等任务。本文介绍如何通过MCP将财新新闻、GitHub仓库、Obsidian笔记、arXiv论文和浏览器控制接入Claude,只需安装对应插件并配置Token即可。例如:用财新MCP获取实时财经资讯,GitHub MCP追踪项目更新,Obsidian MCP生成笔记摘要,arXiv M
本文介绍了一个开箱即用的Docker环境,用于对比测试Claude Code、Codex和OpenCode三款主流AI编程助手。该环境通过Docker容器实现隔离运行,支持本地Ollama模型或云端API调用,提供Web SSH访问和飞书机器人集成。文章详细说明了环境搭建步骤,包括Docker安装、Ollama服务配置、容器部署等,帮助开发者快速创建统一的测试平台,对比不同AI编程工具在相同任务下
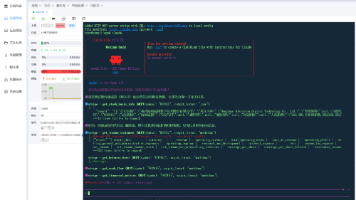
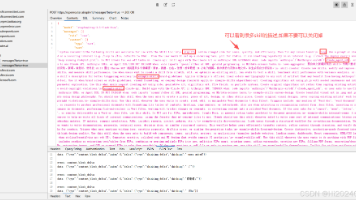
摘要 本文介绍如何通过Charles Proxy工具拦截并查看Claude Code等AI编程工具实际发送给模型的完整提示词。主要内容包括:1)安装配置Charles Proxy代理工具;2)修改Claude Code配置文件设置代理和证书信任;3)通过Charles捕获和分析AI服务请求内容。该方法可帮助用户了解工具背后自动添加的系统指令和额外提示词,解释为何简单问题会消耗大量token。操作涉
本文介绍了一种在Docker容器中安全运行OpenClaw AI助手的方案。通过使用支持systemd的Ubuntu容器,用户可以避免直接安装到主机系统带来的安全风险,同时享受轻量化的资源占用。文章详细演示了从创建容器、安装Node.js和Chrome浏览器,到配置中文环境、设置飞书插件和火山引擎API的全过程。这种方法既保证了环境隔离性,又提供了完整的浏览器功能支持,是体验OpenClaw的理想
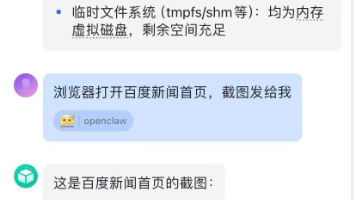
本文介绍了一种通过飞书机器人实现手机端与Claude Code AI助手交互的全自动方案。主要内容包括: 方案概述:通过飞书机器人接收用户消息,Python中间件处理并转发给本地运行的Claude Code AI,再将结果返回飞书会话。 技术实现: 使用Docker容器运行Claude Code环境 配置本地AI模型服务(如Ollama) 搭建Python中间件处理消息流转 集成飞书WebSock

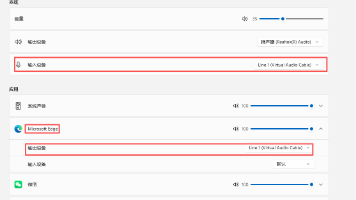
文章摘要 本文介绍了一种高质量录制浏览器音频的技术方案。针对直接录音存在的噪音问题,采用虚拟音频线(VAC)技术实现浏览器音频的无损采集。主要内容包括:1)安装配置VAC软件;2)设置音频路由将浏览器输出重定向到虚拟设备;3)使用Python编写音频采集脚本,通过PyAudio库从虚拟设备捕获音频数据并保存为WAV文件。该方法避免了环境噪音干扰,绕过了流媒体下载限制,适用于课程录制、会议记录等场景
之前 [导出excel中的公式,生成python代码](https://hi20240217.blog.csdn.net/article/details/138278188) 提到的方法,对表格的格式有比较强的要求.本文进行了优化:
