




- @kunhe0512
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
NVIDIA Isaac Lab与Newton物理引擎的结合开创了机器人学习新范式,实现了从仿真到现实的完整工作流。Newton作为专为机器人学习设计的开源引擎,支持大规模并行计算和精确物理仿真。本文展示了四足机器人运动策略的端到端开发流程:首先在Newton中进行高效训练,接着通过Sim2Sim验证策略鲁棒性,最后无缝部署到物理硬件。这套方案还适用于复杂任务如布料操作,展现了在柔性物体交互中的强

随着数据规模的不断扩大,传统的 CPU 计算已经难以满足现代数据科学和机器学习任务的需求。在处理大规模数据集时,训练模型和进行预测可能需要数小时甚至数天的时间。为了解决这一挑战,NVIDIA 推出了 RAPIDS 生态系统,其中的 cuML 库提供了 GPU 加速的机器学习算法,能够显著提高计算速度,同时保持与流行的 scikit-learn API 的兼容性。本文将详细介绍 NVIDIA cuM

在人工智能快速发展的今天,下一代AI驱动的机器人,如人形机器人和自动驾驶汽车,都依赖于高保真、物理感知的训练数据。然而,如果没有多样化且具代表性的数据集,这些系统将无法获得适当的训练,并在测试中面临诸多风险:泛化能力差、对真实世界变化的适应有限、在边缘情况下行为不可预测等。而收集大规模真实世界数据集不仅成本高昂,还极其耗时,且常常受到现实可能性的限制。NVIDIA Cosmos通过加速世界基础模型

摘要: 本文详细介绍了在NVIDIA Jetson设备上运行HuggingFace LeRobot机器人学习框架的完整流程。内容包括硬件要求(推荐Jetson AGX Orin)、JetPack 6环境配置、存储优化建议,以及真实机器人(以Koch v1.1为例)的端到端工作流程:从硬件连接、音频配置、udev规则设置,到数据记录、模型训练和策略评估。特别强调了NVMe SSD存储的重要性,并提供

如果您想知道AI服务器与AI工作站有何不同,那么您不是唯一一个。假设严格的AI用例具有最小的图形工作量,明显的差异可能很小甚至没有。从技术上讲,您可以将一个用作另一个。但是,根据要求每个人执行的工作量,每个人的结果将完全不同。因此,重要的是要清楚地了解AI服务器和AI工作站之间的区别。暂时将AI放在一边,服务器通常倾向于联网,并可作为共享资源使用,运行通过网络访问的服务。工作站通常旨在执行特定用户

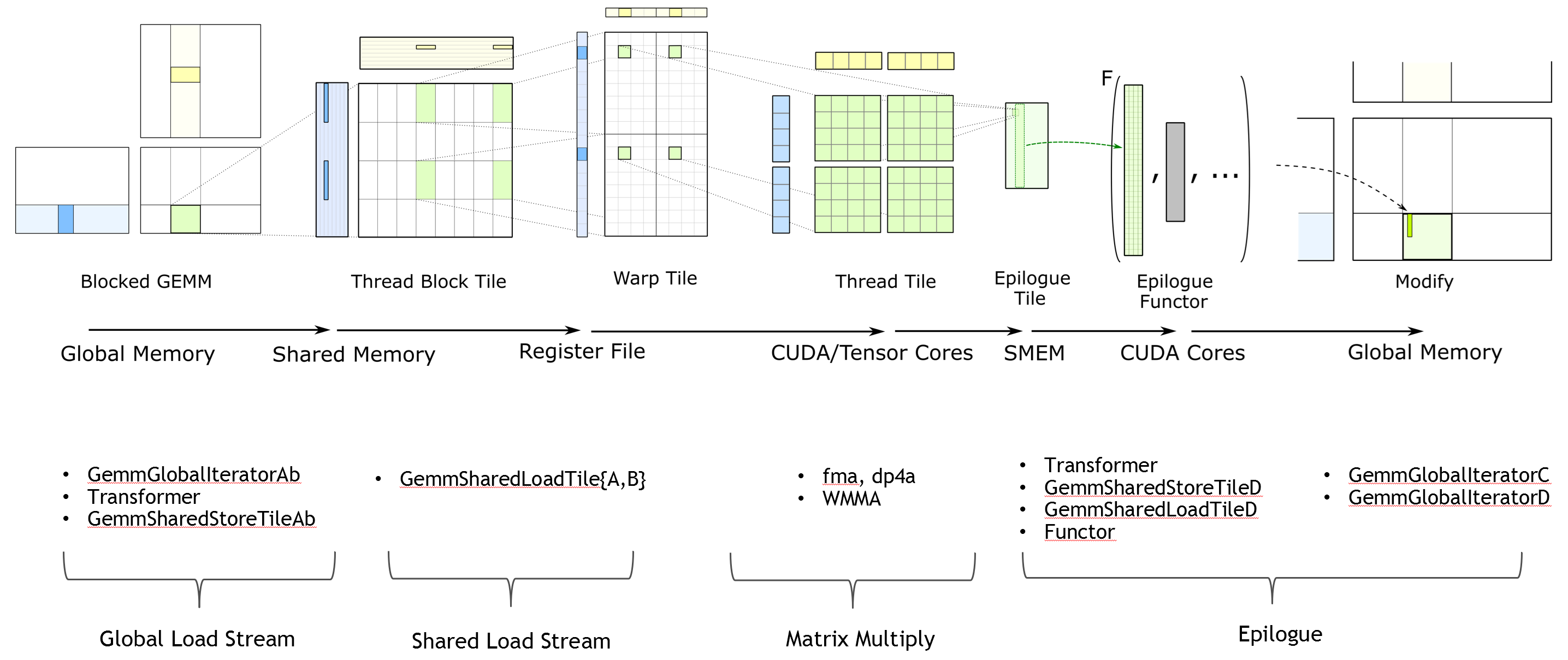
NVIDIA CUTLASS (CUDA Templates for Linear Algebra Subroutines and Solvers) 是一个用于线性代数运算的CUDA C++模板库。它专门为深度学习中的矩阵运算优化,提供了高性能的GEMM(通用矩阵乘法)实现。
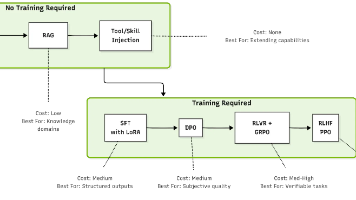
AI Agent 定制技术全景与实践路径 本文系统梳理了AI Agent定制的九类关键技术,包括从轻量级的提示词工程到深度强化学习等不同方法。文章指出,企业需要根据任务特点、资源条件和项目成熟度选择适合的定制路线,使通用AI模型能够真正适配特定业务场景。核心定制方法包括:提示词工程解决行为塑造问题,RAG补充知识缺口,工具/技能注入扩展行动能力,监督微调优化特定任务表现等。文章强调,有效的Agen
NVIDIA推出Verified Agent Skills治理机制,为AI Agent能力层建立信任体系。该方案将Skill从简单说明文件升级为可发布、可扫描、可签名的软件资产,包含加密签名、风险扫描、能力声明等关键元数据。通过Skill Card实现机器可读的信任记录,支持来源验证、完整性检查和安全策略执行。这套机制解决了Agent能力扩展中的透明度问题,使企业能够在加载前对Skill进行治理,

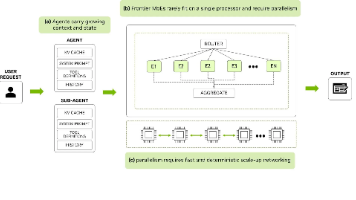
NVIDIA Vera Rubin平台通过软硬件协同设计解决Agentic AI的规模化难题。该平台结合Vera Rubin NVL72的高吞吐计算能力和Groq 3 LPX的低延迟执行能力,专门针对Agentic推理中非确定性轨迹、长上下文和多工具调用等挑战。其核心技术包括高radix点对点连接、编译器调度数据移动和硬件驱动的近同步时序,可显著降低跨芯片通信的不确定性,改善尾延迟问题。开发者需关
在传统(“经典”)计算机中,一个比特只能是0或1。而量子比特(“quantum bit"或"qubit”)则可以表示为两种状态的线性叠加。∣ψ⟩α∣0⟩β∣1⟩∣ψ⟩α∣0⟩β∣1⟩其中∣0⟩|0\rangle∣0⟩和∣1⟩|1\rangle∣1⟩⟨0∣0⟩1⟨1∣1⟩1⟨0∣1⟩0⟨1∣0⟩0⟨0∣0⟩1⟨1∣1⟩1⟨0∣1⟩0⟨1∣0⟩0而α\alphaα和β。