
写文章




- @python1234567_
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
CV工程师:做了五年目标检测,我发现多模态大模型在抢饭碗
一个模型能看、能读、能描述、能问答,很多原来需要专门训练的任务,现在写一段Prompt就能覆盖。
大模型微调指南:让通用模型适配你的业务场景
如果说大模型是"大脑",AI Agent就是"完整的人":有大脑、有手脚、有记忆、能使用工具、能自主规划。
大模型微调指南:让通用模型适配你的业务场景
如果说大模型是"大脑",AI Agent就是"完整的人":有大脑、有手脚、有记忆、能使用工具、能自主规划。
AI 界的大谎言?DeepSeek-OCR 告诉你使用 Tokenizers 全错了!用图像来表达效果更好
DeepSeek 近期发布了他们的新模型和相关论文。说实话,这次发布的 DeepSeek-OCR 多少有点出乎大家意料,但鉴于 DeepSeek 团队发布的作品向来都是大事件,想谈谈自己的看法。

如何选择AI Agent框架?主流Agent框架对比!
什么是LLM Agent? 大模型Agent是一种构建于大型语言模型(LLM)之上的智能体,它具备环境感知能力、自主理解、决策制定及执行行动的能力。
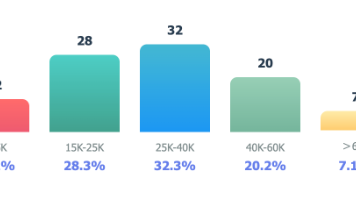
2025年AI Agent岗位市场调研:基于101个职位的数据分析,大模型入门到精通,收藏这篇就足够了!
如果想找一份AI Agent开发工作,Python + LangChain + RAG 已成为市场主流的技术组合。
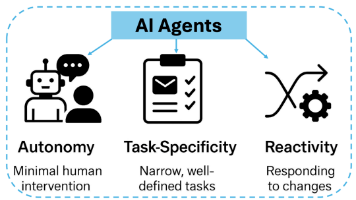
AI Agents:智能体的神奇进化与多元应用,大模型入门到精通,收藏这篇就足够了!
近年来,随着大语言模型的出现,AI Agents 进一步发展出自然语言理解、任务分解、工具调用与长期记忆等高级能力,使其能够在复杂、不确定的场景中展现出近似人类的认知与协作特性。
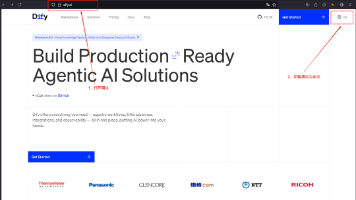
从0开始搭建AI知识库,亲手让知识“活”起来,大模型入门到精通,收藏这篇就足够了!
今天,我们就来动手实践——带你用 Dify 这款开源的低代码 AI 应用开发平台,从零开始体验搭建一个属于你自己的 RAG 知识库。
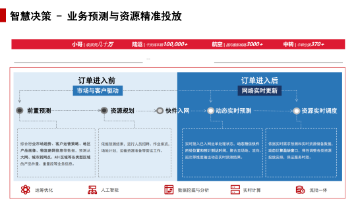
行业落地分享:AI智能体在顺丰运营环节的应用
在当今瞬息万变的物流行业,效率与精准度是核心竞争力。传统的管理模式已无法满足日益增长的业务需求,而AI智能体正成为推动物流业革新的关键力量。
一文搞懂如何构建大语言模型?构建大规模数据集
大语言模型通过在海量无标注文本数据上进行训练,实现 “量变引起质变”, 让模型学习人类语言的内在规律和世界知识。
