




- @weixin_42795092
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基于 Transformer 架构,通过海量文本数据预训练而成,具备跨场景语言理解与生成能力。关键特点是参数规模大(从百亿到万亿级)、上下文窗口长(支持万级以上 token 输入)、泛化能力强(无需针对特定任务单独训练)。

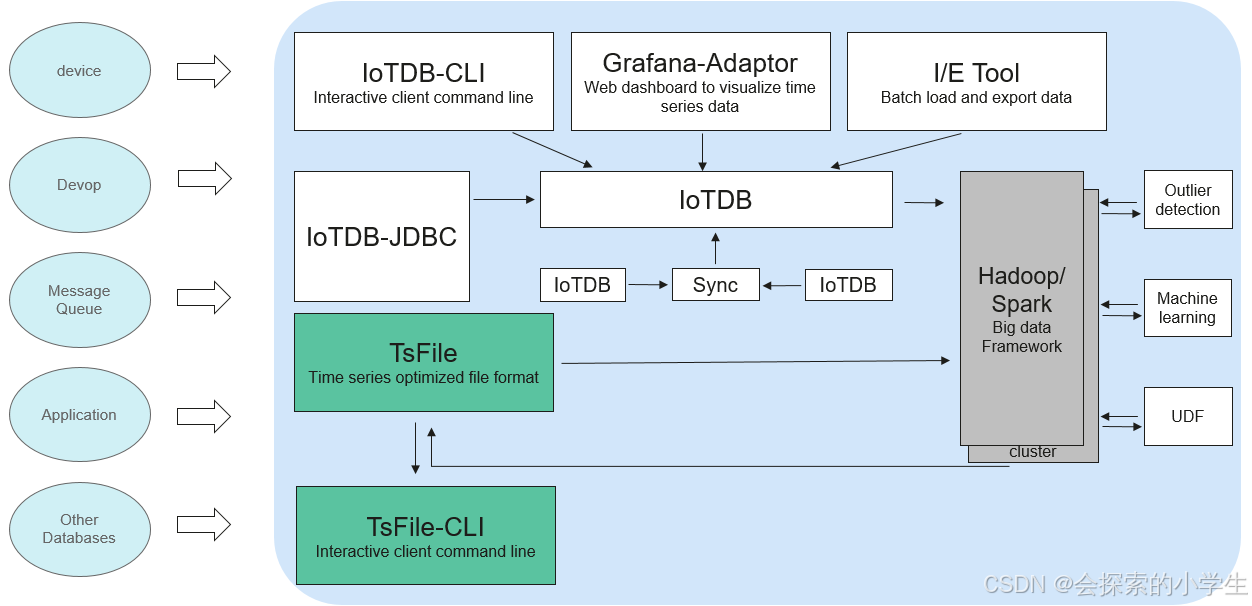
IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。Apache IoTDB采用轻量式架构,具有高性能和丰富的功能。IoTDB从存储上对时间序列进行排序,索引和chunk块存储,大大的提升时序数据的查询性能。通过Raft协议,来确保数据的一致性。针对时序场景,对存储数据进行预计算和存储,提升分析场景的性能。
一、联合查询1.使用 union 连接两个 select 语句进行联合查询select 列 1,列 2... from 表名 where 条件 union select 列 1,列 2... from 表名 where 条件;select vend_id,prod_id,prod_name,prod_price from products where prod_price <= 5 union s

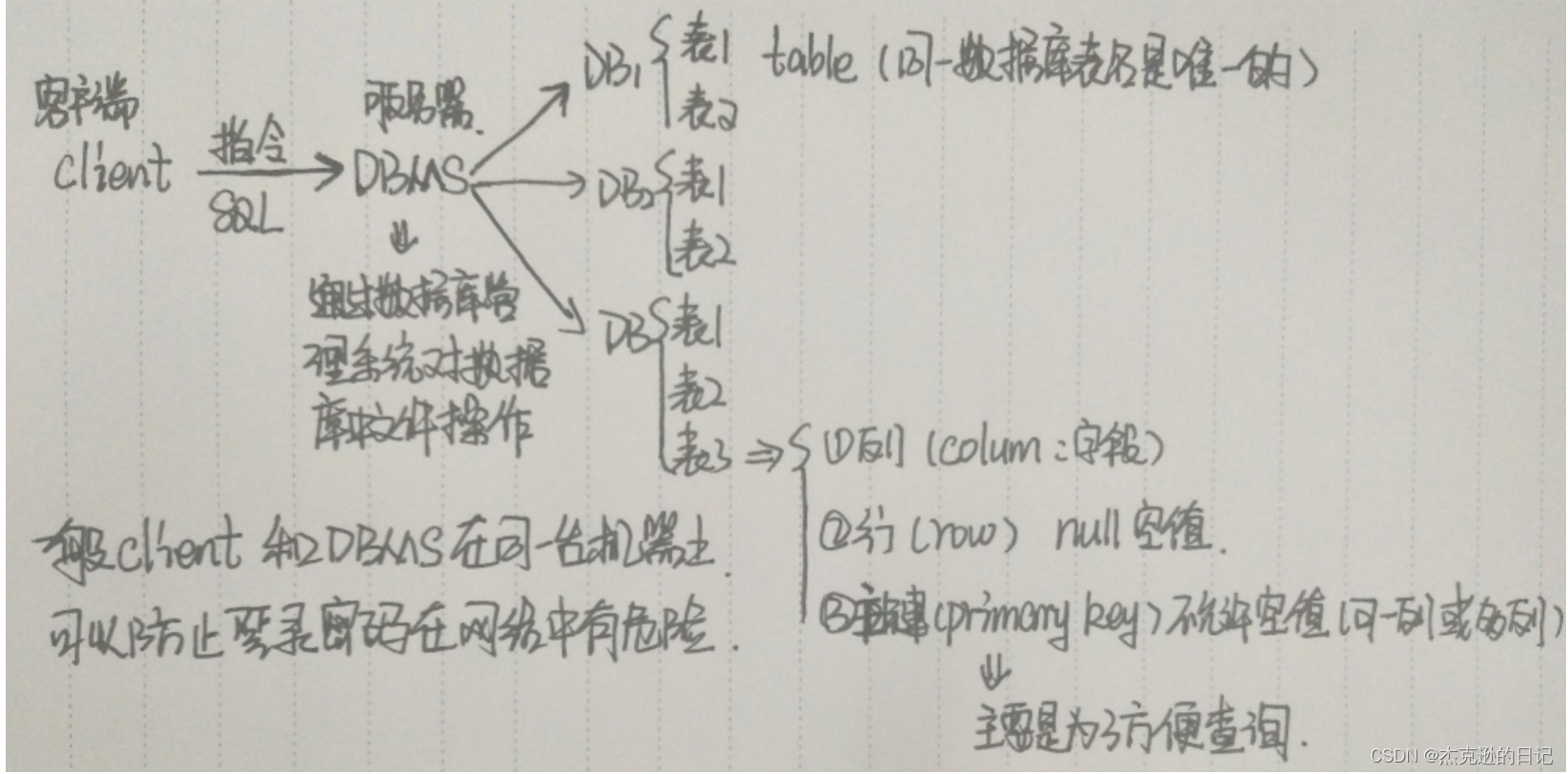
1.DB(DataBase):数据库,存储已经组织好的数据的容器2.DBMS(DataBase Manage System):通过数据库管理系统,对数据库及数据库中的数据进行操作注:我们平时所说的 Oracle、Mysql、MariaDB 指的都是数据库管理系统(DBMS)注:一个数据库中,表的名字是唯一的1.框架(Schema):关于数据库和表布局以及属性信息。2.列(column):表中的一个
DBService是一个高可用性的关系型数据库存储系统,适用于存储小量数据(10GB左右),比如:组件元数据。DBService仅提供给集群内部的组件使用,提供数据存储、查询、删除等功能。DBService是集群的基础组件,Hive、Hue、Oozie、Loader和Redis组件将元数据存储在DBService上,并由DBService提供这些元数据的备份与恢复功能。

GPU利用率70%-90%、显存使用率≤80%、P95/P99延迟、吞吐req/s、OOM报错率、NCCL通信状态。CPU:逻辑串行、复杂任务;:降batch、FP16/INT4量化、梯度累积、清理残留进程、开启显存优化。:多机多卡、NCCL通信、极致算力/显存/网络带宽,追求高利用率。:batch过大、模型过大、显存泄漏、多进程抢占、未优化精度。:低延迟、高吞吐、动态批处理、显存优化,追求服务稳

一、代码开发类(程序员、后端、前端首选) 1. GitHub Copilot 作用:IDE 实时代码补全、函数生成、注释、bug 修复、生成单元测试适用:Java/Python/Go/JS/SQL,VS Code、IDEA 全主流编辑器场景:日常编码、接口开发、快速写脚本 2. CodeGeeX(国产免费) 作用:代码生成、代码解释、代码翻译、漏洞修复场景:国内开发、国产化项目、离线内网开发 3.

问:这些显存调优方法你平时怎么落地操作?量化:优先离线把模型转成 INT4-AWQ 权重,vLLM/TRT-LLM 启动时指定量化参数,直接降低基础显存占用;H100/H200 会开启 FP8。KV Cache:严格配置限制上下文,设置在 0.7~0.85 预留空间,多卡场景用张量并行自动分片 KV。超大模型:34B/70B 采用 TP/PP 多卡并行拆分权重,突破单卡显存上限。泄漏与碎片:日常用

问:这些显存调优方法你平时怎么落地操作?量化:优先离线把模型转成 INT4-AWQ 权重,vLLM/TRT-LLM 启动时指定量化参数,直接降低基础显存占用;H100/H200 会开启 FP8。KV Cache:严格配置限制上下文,设置在 0.7~0.85 预留空间,多卡场景用张量并行自动分片 KV。超大模型:34B/70B 采用 TP/PP 多卡并行拆分权重,突破单卡显存上限。泄漏与碎片:日常用
GPU(图形处理单元)算力优化是提升计算性能的重要任务,在深度学习、科学计算等领域有重要意义。下面从硬件层面、软件层面和算法层面为你介绍一些优化方法:以下是一个使用 PyTorch 在 GPU 上进行简单矩阵乘法的示例,展示了如何利用 GPU 加速计算:gpu-computation-optimizationGPU 矩阵乘法计算示例V1生成 gpu_matrix_multiplication.py