登录社区云,与社区用户共同成长
邀请您加入社区
群里测试组的老K连发三条语音,语气像丢了孩子:“完了完了,大模型接口调用量上周冲到日均500万了,我们那200条手工用例还在SVN里躺着,一条条复制粘贴到Postman跑,已经连续加了三天班了。我们遇到过一个case:问“公司几点上班”,旧模型回答“9点”,新模型回答“上午9:00(弹性工作制,最晚10点)”。更重要的是,线上投诉率下降了70%——因为每次模型更新前,那些“看着差不多”的边界问题都
复杂系统和应用的功能和接口众多,人工测试用例生成方法难以全面覆盖各种场景和需求,同时复杂系统和应用还涉及到大量的数据和算法,人工测试用例生成方法难以准确模拟用户人工测试用例生成方法可能受到测试工程师的经验和知识水平的限制。在整个训练过程中,我们的目标是让模型能够深入理解测试数据的模式,以便在未来遇到新的测试用例时能够做出准确的预测。通过这些详细的特征转换方法,确保测试数据在进入机器学习模型训练 之
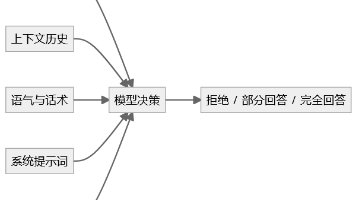
PNAS 这篇论文最值得我们警惕的地方,不是“大模型被人类话术骗了”这个表面结论。大模型的安全边界,会受到语言策略、上下文关系和交互过程影响。这意味着,AI 系统不能只靠几条规则、几个敏感词、一个安全 Prompt 就放心上线。对测试人来说,下一阶段的核心任务不是简单问一句:“模型会不会拒绝?而是要追问:换一种说法还会拒绝吗?多聊几轮还会拒绝吗?用户伪装成专家还会拒绝吗?模型接入工具后还会拒绝吗?
很多同学看到算法岗、AI岗薪资高,第一反应是:“那我是不是必须转算法?其实不一定。大厂研究院、基础模型、算法研究岗位,确实更看重学历、论文、数学基础和算法能力。但企业里更多的 AI 需求,并不是都在做底层模型。大量岗位其实是在做:AI应用开发AI工具平台AI测试平台智能客服系统企业知识库自动化办公流程数据分析智能体研发提效工具测试提效工具业务流程自动化也就是说,普通开发、测试开发、产品、运营岗位,
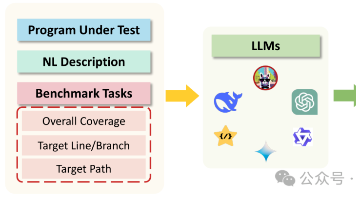
摘要:论文《TESTEVAL: Benchmarking Large Language Models for Test Case Generation》提出首个系统评估LLM生成测试用例能力的基准框架TESTEVAL,覆盖整体代码、目标行/分支及路径三类任务。实验基于210个LeetCode程序(平均环路复杂度13.35),测试17个主流LLM发现:模型虽能生成多样测试用例实现较高整体覆盖率(如G
全球科技巨头争相布局AI基础设施,微软、谷歌、亚马逊等市值领先企业均在AI产业链占据关键位置,表明AI已成为下一代技术竞争的核心。企业正通过AI重塑业务流程,推动岗位结构变革——低效岗位压缩,高效人才需求激增。对测试开发等岗位而言,AI带来显著机遇:测试人员可借助AI优化用例生成、缺陷分析等环节,向质量效率工程师转型。当前AI产业更急需能将技术落地的应用型人才,而非仅关注理论研究。随着资本持续涌入
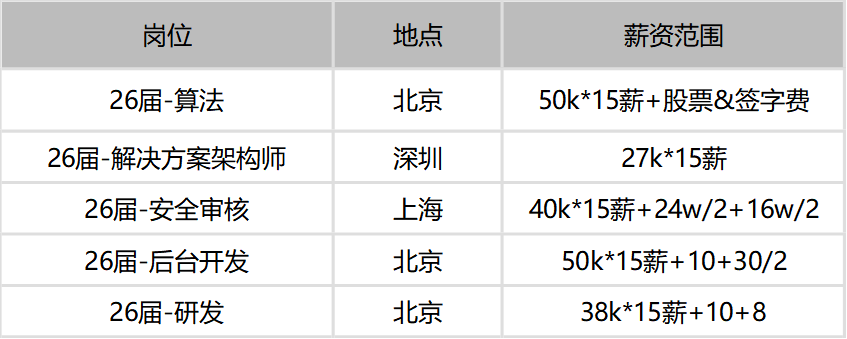
2027届秋招提前批已全面启动,互联网大厂、央国企、外企、金融等行业核心岗位开放投递。提前批具有岗位优质、流程快、多一次机会等优势,AI算法、大模型、后端开发、测试开发等方向需求旺盛。建议同学优先匹配自身项目经历投递,完善简历和面试准备,避免盲目海投。央国企数字化岗位、金融科技等稳定性较强的方向也值得关注。秋招竞争前移,抓住提前批窗口期对最终结果至关重要,需立即行动并针对性优化求职策略。
方式一:@tool 装饰器(最推荐)@tool"""获取指定城市的当前天气。参数:city: 城市名称,例如 '北京', '上海'。"""# 实际场景中替换为 API 调用"北京": "晴天,25°C","上海": "多云,28°C",return weather_data.get(city, f"{city} 暂无数据")函数的 docstring 自动成为工具的 description。这是最
本文探讨了temperature参数对AI模型(deepseek-v4-pro)处理不同复杂度任务的影响。通过测试创意写作、逻辑推理和电商报告三种任务(各运行2次),发现:1)所有任务在temperature=0.3和1.0时成功率均为100%,但电商报告的平均Token(556)显著高于创意写作(190);2)temperature对Token数的影响因任务而异,未呈现稳定规律;3)结构化任务(
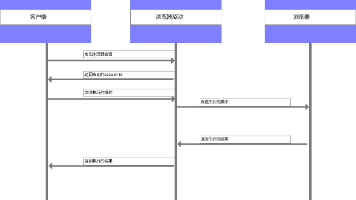
当下的AI技术迅猛渗透到各领域,对软件测试也造成不小的冲击。对测试从业者而言,无需畏惧 AI 的冲击,更应聚焦自身核心能力的提升。以下分享了如何利用AI(通义大模型),将日常需求转化为测试用例,并自动生成到AgileTC测试用例管理平台中。
大模型进入测试领域之后,一个常见问题是:测试人员会不会被 AI 替代?如果只是做重复性的测试内容编写、简单脚本生成、基础报告整理,这些工作确实会被快速自动化。但在可信测试体系里,人的价值反而会更加突出。因为 AI 可以帮助生成内容,但不能天然承担质量责任。人的角色会从“手工执行者”,逐步转向:业务风险识别者测试模型设计者规则体系建设者测试结论复核者质量可信体系负责人。
│ ││ 输入质量决定输出质量(Garbage In = Garbage Out) ││ ││ AI负责"生成" + "穷举" ││ 人负责"判断" + "决策" ││ ││ 多轮迭代 > 一次性输出 ││ 分模块处理 > 全量输入 ││ 结构化Prompt > 随意提问 ││ │。
陈明,科大讯飞股份有限公司 AI工程院高级测试工程师。本次在TID质量竞争大会中,陈明将结合大模型效果评测相关实践,分享从人工评测到自动化评测的工程化探索。议题将重点关注大模型效果评测在真实业务中的痛点、体系化建设思路、典型场景实践,以及评测能力后续演进方向。大模型时代,质量工程正在面对新的问题。过去我们更多关注功能是否正确、流程是否稳定、系统是否可用;现在,当大模型开始参与内容生成、任务执行和业
AI测试培训市场分析:随着AI技术在软件测试领域的应用日益深入,目前市面上的AI测试培训主要分为四类:AI辅助测试(提升传统测试效率)、AI产品测试(评测大模型/RAG/Agent等AI系统)、AI测试开发(构建测试智能体和评测平台)以及认证培训。主流培训机构如霍格沃兹测试开发学社、黑马程序员等分别侧重系统化能力培养、就业转型和专项技能提升。选择课程需重点关注AI内容占比(是否独立模块)、技术更新
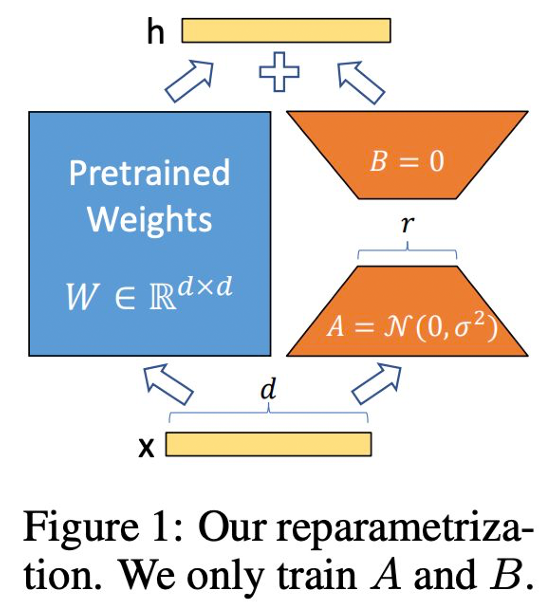
大家的显卡都比较吃紧,LoRA家族越来越壮大,基于LoRA出现了各种各样的改进,最近比较火的一个改进版是dora,听大家反馈口碑也不错。
Selenium是Thought Works公司开发的一套基于web应用的自动化测试工具,直接运行在浏览器中,模拟用户操作。它可以被用于单元测试、集成测试、回归测试、系统测试、冒烟测试、验收测试,并且可以运行在各种浏览器和操作系统上。目前使用selenium的人群大概有两大类吧,一类是软件测试工程师,他们可以通过selenium来实现自动化的测试,以提高回归测试的效率,降低人员的执行成本。
智能体协作的自动化工作流多智能体对抗测试。
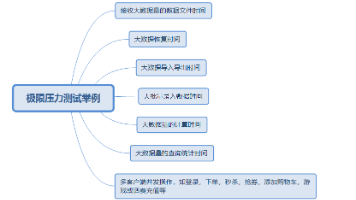
压力测试(Stress Test),也称为强度测试、负载测试,属于性能测试的范畴。压力测试是模拟实际应用的软硬件环境及用户使用过程的系统负荷,长时间或超大负荷地运行被测软件系统,来测试被测系统的性能、可靠性、稳定性等。一定负载的情况下,长时间运行被测软件系统,称为稳定性测试;超大负荷地运行被测软件系统称为极限压力测试。
摘要 Claude在代码重构过程中能有效维护测试用例的同步更新。通过分析代码变更和测试意图,它能够自动调整测试用例中的参数传递、断言结构和异常处理,确保测试与实现保持一致。Claude采用迭代式工作流:运行测试→捕获错误→分析失败原因→生成修复→重复验证,最多尝试5次。典型应用场景包括函数签名变更、返回类型调整等,它能自动更新mock数据、断言条件和新增边缘情况测试,但仍需注意无法理解内部实现细节
ETest具有应用范围广、实时性强、开发效率高、使用简单、易于扩展、国产自主安全可控等特点,支持国产CPU+国产操作系统的部署方案,同时兼容Windows、linux、Mac、VxWorks等操作系统。支持各类控制总线和仪器接口API,包括:RS232/422/485、1553B、ARINC429、ARINC664、ARINC825、1394B、FC-AE-ASM、CAN、TCP、UDP、AD、D
在上一篇中,我们探讨了国产IDE的发展背景与技术能力。今天,我们将聚焦国产IDE的产品生态矩阵,从通用开发、嵌入式、FPGA到专业领域,全景呈现国产IDE的多样化布局,并展望其未来发展趋势。国产 IDE 已在技术自主可控、细分领域应用上取得显著突破,部分产品技术指标达到或超越国际先进水平,中文语义理解、本土化适配等优势突出,覆盖通用开发、嵌入式、FPGA 等多个领域。企业数字化转型加速,对云原生应
这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!为 APP 设计测试用例需要考虑移动设备的特殊性,如不同的操作系统、设备尺寸、硬件特性以及应用程序自身的特定功能。设计APP的测试用例还需要不断地以用户体验为中心,关注细节,并针对不同操作系统的特性和限制进行专门的测试。选择适当的测试类型,如功能测试、兼容性测试、性能测试、安全
Skill 的本质不是文件夹,也不是一段更高级的 Prompt。如何把人类已经验证过的专业知识、操作流程和工具使用方法,沉淀为 AI Agent 可以发现、加载、执行、校验和持续迭代的能力。可以用几句话总结 Skill 与其他概念的关系:Prompt:告诉模型这一次要做什么;Skill:告诉 Agent 这一类任务长期应该怎么做;Tool:提供可以执行的具体动作;Workflow:组织任务步骤和控
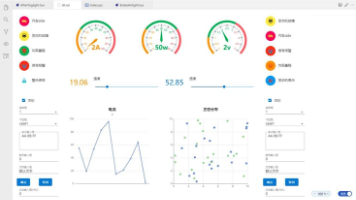
本文探讨了AI智能体在数据分析任务中的可靠性问题,通过5个真实CSV任务测试发现,尽管表面上任务能完成,但可能存在分组统计错误、数值计算编造等问题。文章介绍了一个完整的测试流程,从测试设计到缺陷发现,包括多维评分(规划、工具使用、代码能力、知识)和缺陷检测。测试结果显示,5个任务全部执行成功并通过60%的门禁要求,平均得分68.8%,但存在子任务规划过多、知识维度评分偏低等问题。文章强调了测试数据
在 AI 智能体如火如荼发展的今天,"Skill" 这个概念频繁出现在各类技术文章中。但大多数文章只是浅尝辄止地介绍其概念,很少有文章把它的运行机制、设计哲学和实际落地讲透。本文将从 Agent Skill 的本质出发,由浅入深地带你理解:Skill 与普通 Prompt 究竟有何不同、它的三层渐进式架构如何工作、它与 MCP 和 Tool 的分工边界在哪里,以及最重要的 —— 你如何在实际工作中
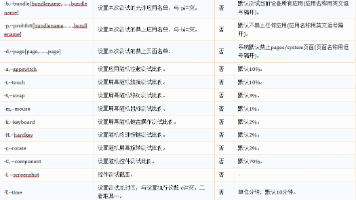
若配置-e、-E则须配置-b来指定应用。
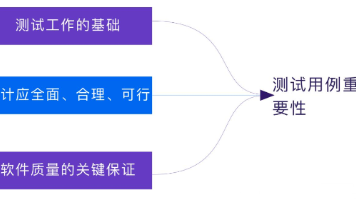
测试用例
——测试用例
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区

 AI Agent技术社区
AI Agent技术社区


 智能体开发者社区
智能体开发者社区


 DeepSeek技术社区
DeepSeek技术社区






 openEuler 社区
openEuler 社区


 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区





 CSDN-OPC开发者社区
CSDN-OPC开发者社区


 HarmonyOS开发者社区
HarmonyOS开发者社区