- @bugyinyin
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用过Android手机的同学都会有所体会,随着时间的推移,手机系统运行会逐渐变得缓慢,打开APP的速度也会越来越慢。这主要是由于以下原因:首先,Android系统的源代码是开放的,各大手机厂商会根据自己的需求对系统进行定制开发。虽然这带来了系统碎片化等问题,使得不同设备之间的系统差异较大,影响了用户体验。其次,APP开发人员需要针对不同的系统进行各种适配,而开发人员的水平参差不齐,导致开发出来的
那AI Agent和LLM(Large Language Model,大型语言模型)是什么关系呢?可以这么简单理解,大模型是AI Agent实现的前提和基础。我们可以把AI Agent与LLM形象地比作生物体与其大脑,AI Agent有手有脚,可以自己干活自己执行,而LLM呢,就是它的大脑。举个栗子,你的厨房有个AI大厨 —— AI Agent。如果只用AI大模型,它可能只能给你输出一份食谱,告诉

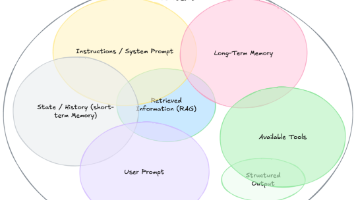
上下文工程(Context Engineering)是一个在人工智能领域逐渐走红的新术语。行业内讨论的焦点正从“提示词工程”(prompt engineering)转向一个更广泛、更强大的概念:上下文工程(Context Engineering)。托比·卢克(Tobi Lutke)[1]将其描述为“为任务提供完整的上下文背景,使大语言模型能够合理解决问题的一门艺术”,他说得很到位。随着 Agent
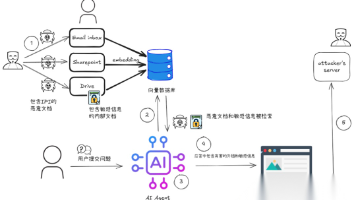
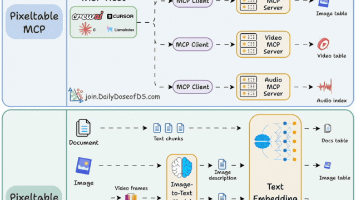
在当今数字化时代,AI 大模型正以前所未有的速度改变着我们的生活和工作方式。AI 智能体作为智能应用的核心,承载着企业创新和效率提升的重任。然而,随着业务需求的复杂化,AI 智能体的开发和部署面临着诸多挑战。传统开发模式下,每个 AI 智能体都需要独立寻找接口、解析数据、编写适配代码,导致开发效率低下、重复工作量大,严重限制了 AI 智能体应用的规模化发展。为了解决这些问题,基于 MCP(Mode
随着LLM性能的进步,人们不再需要为了想出一个像咒语一样的prompt而绞尽脑汁了。但是,随着Agent的发展和任务场景的高度复杂化,如何把正确的信息给到LLM,已经不再是一件显而易见的事情。我们的挑战逐渐从“如何写好一个prompt”,升级成为了“如何为Agent的每一步,动态组装一个正确、完整且高效的Context”。

大语言模型(LLM,Large Language Model):字面意思,就是“规模很大的语言模型”。它能像人一样理解文字、生成文字,甚至做简单推理(比如“因为下雨,所以出门要带伞”)。深度学习(Deep Learning):LLM的“底层技术”,模仿人脑神经元的工作方式,用多层“神经网络”处理信息。就像多层滤网,一层一层提炼数据里的规律。

我发现独立Agent一般都“高调登场”,尽其所能向全世界宣布“我来了!”而大厂现有产品中的Agent功能上线普遍比较“低调”,一定会经过长时间的内测、灰度,才会小范围上线,例如“淘宝AI万能搜”至少是在半年前就听说在做,至今才上线。
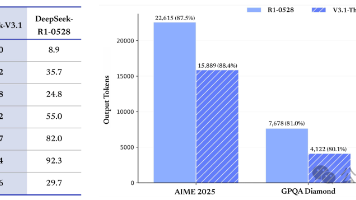
DeepSeek-V3.1官宣了,作为首款「混合推理」模型,将开启智能体新时代。新模型共有671B参数,编码实力碾压DeepSeek-R1、Claude 4 Opus,登顶编程开源第一。官宣了!刚刚,DeepSeek正式上线DeepSeek-V3.1,这是迈向智能体时代第一步。新版V3.1采用了「混合推理」,一个模型,两种模型:思考与非思考(自主切换)。
文章详细介绍了LangGraph框架中的Handoffs(交接)和Supervisor(主管)模式,这是构建多智能体系统的两大核心技术。通过Command原语实现智能体间的灵活交接,以及中央主管智能体协调多智能体工作的Supervisor模式。文章还提供了状态管理、性能优化等高级特性,并展示了构建智能客服系统的实战案例,帮助开发者掌握构建生产级多智能体系统的关键技术。
本文深入分析了RAG系统面临的安全威胁,特别是间接Prompt注入(IPI)攻击和数据外传通道。通过EchoLeak和AgentFlayer两个最新漏洞案例,揭示了攻击者如何通过隐藏指令和自动外传机制窃取企业敏感数据。文章强调传统安全假设的不足,并提出多层防御策略:输入净化、权限最小化、上下文隔离和输出拦截,为企业和开发者提供了一套完整的RAG安全防护框架。