




- @civiljiao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DeepSeek R1 是一款开源的AI模型,支持在本地上硬件离线运行。:在命令行中执行nvidia-smi指令,确认 CUDA 驱动版本是否满足最低要求(≥11.8)。:若版本低于 11.8,需更新 NVIDIA 驱动或安装适配的 CUDA Toolkit。:显存需求 ≈ 模型参数量(B) × 参数精度(bytes) × 1.2(额外开销系数)例如:14B 模型在 4-bit 量化(0.5 by
EasyDL平台旨在为企业和开发者提供一个无需深厚算法背景的AI开发解决方案。零算法基础:用户无需掌握复杂的CNN、RNN等深度学习原理,通过图形化界面即可完成从数据准备到模型部署的全流程操作。高效开发:从数据标注、模型训练到上线部署,用户可以在5-10分钟内快速实现AI应用。这样一来,即便是初学者也能通过简单操作完成较为复杂的任务。灵活部署:平台支持多种部署方式——公有云API、设备端SDK、私
如果显示的是WARNING:No swap limit support或者什么都没显示,就说明是nvidia驱动程序没有被docker daemon使用,这个时候有点麻烦,可能是因为/etc/docker/daemon.json配置文件没配置对,也可能是docker没安装好。如果显示"nvidia:yes"或者有其他正常显示,就说明docker daemon正在使用nvidia驱动程序,这个时候使

One API 是一个开源的 AI 大模型 API 管理与分发系统,致力于解决多模型接入过程中面临的繁杂协议、密钥管理、流量分配等问题。它通过标准化接口(基于 OpenAI 格式)实现了不同大模型的无缝衔接。无论是 OpenAI、Google Gemini,还是国内的文心一言、讯飞星火等平台,开发者只需简单配置即可实现切换,旧代码无需大幅重构。

2 分层强化学习算法1 分层强化学习简介分层强化算是强化学习领域比较流行的研究方向。当环境较为复杂或者任务较为困难时,智能体的状态和动作空间过大,会导致强化学习难以取得理想的效果。应对这种状况,分层强化学习应运而生,主要解决稀疏reward以及状态动作空间过大导致难以训练的问题。人类在解决一个复杂问题时,往往会将其分解为若干个容易解决的子问题,分而治之,分层的思想正是来源于此。
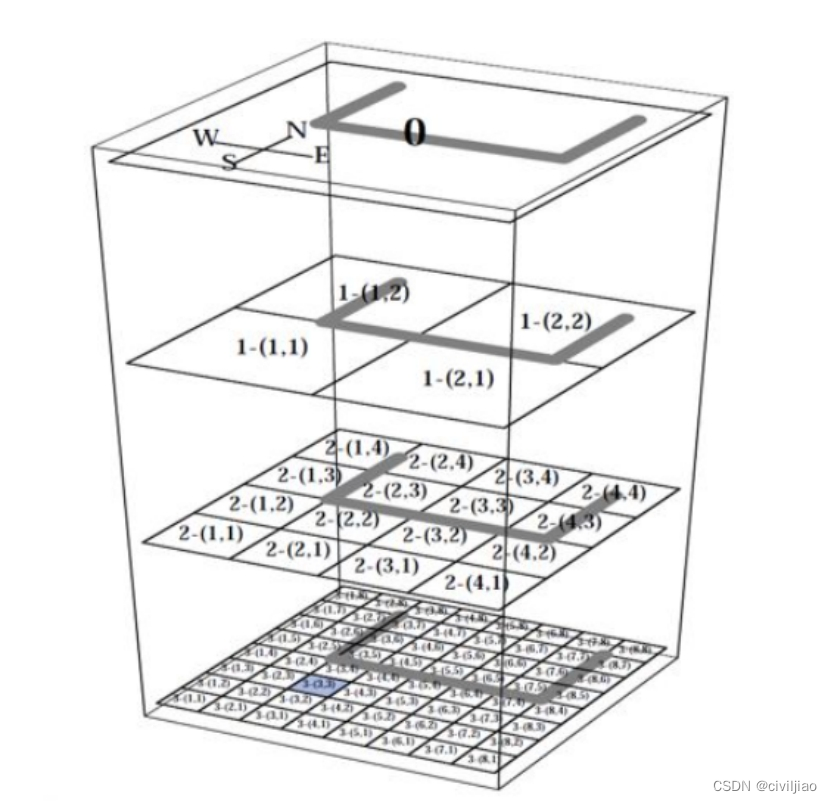
难点:长迟滞导致当前的决策影响后几分钟的数据变化,但是这个时间也就是“停留时间”在反应的前中后期也不一样。另外反应过程中反应程度你是不可控的,导致几分钟后的数据是因为当前的这个决策所影响的判断较难下定量的结论。奖励:上述的奖励设定感觉还是短迟滞反应的奖励设定,长迟滞反应的奖励你该怎么设定,这个还需要考虑,如果想做一个较通用化的软件来训练RL的模型,也逃避不了奖励的设定、态势的选取。如果奖励考虑优化
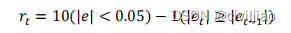
如果显示的是WARNING:No swap limit support或者什么都没显示,就说明是nvidia驱动程序没有被docker daemon使用,这个时候有点麻烦,可能是因为/etc/docker/daemon.json配置文件没配置对,也可能是docker没安装好。如果显示"nvidia:yes"或者有其他正常显示,就说明docker daemon正在使用nvidia驱动程序,这个时候使
OpenManus 是一个先进的 AI 代理框架,旨在通过模块化设计实现大模型(如 GPT-4o、Claude-3.5)和智能体的深度协作。它的目标是自动化复杂任务,如金融报告生成和软件开发全流程。
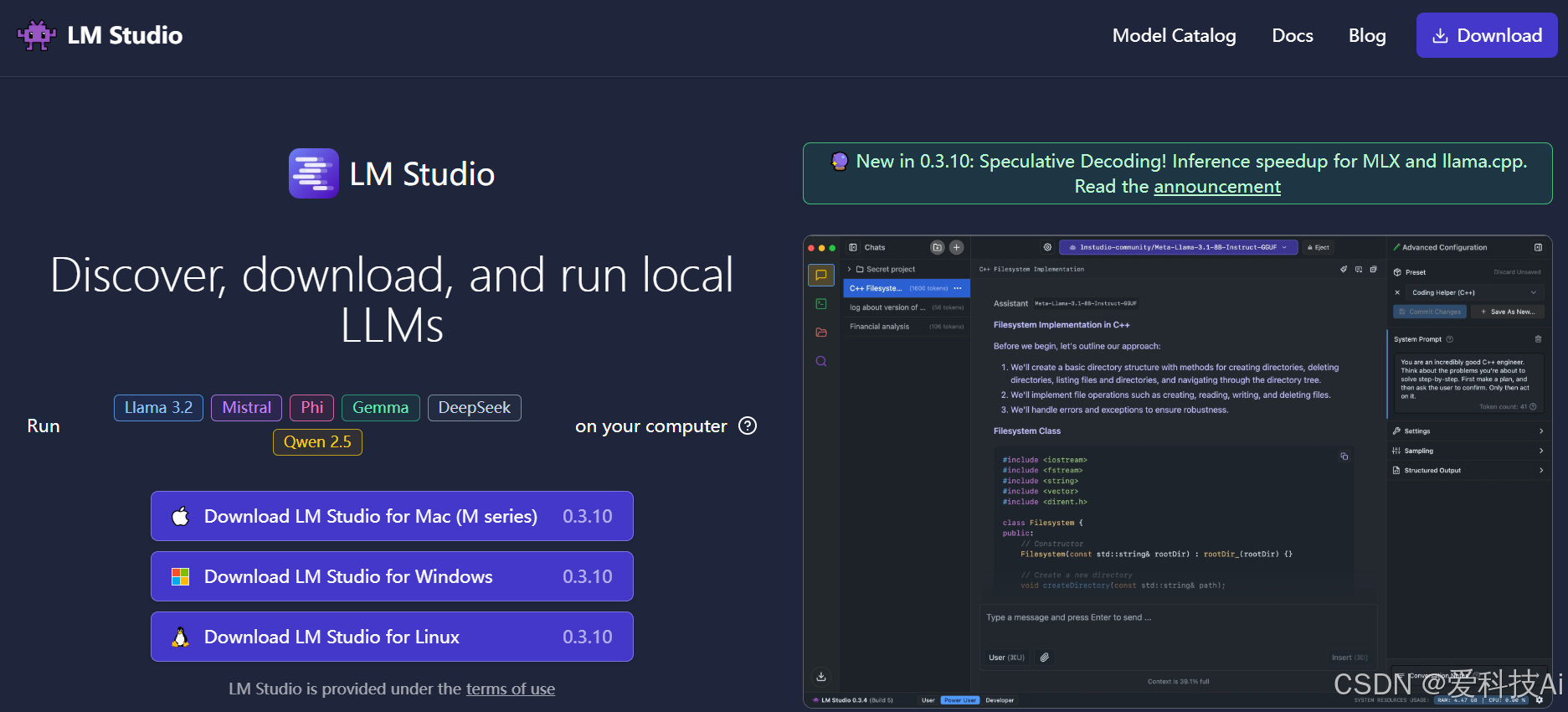
基于Web的轻量化界面,支持与Ollama、LM Studio等后端工具集成,提供类ChatGPT的交互体验。:专注于本地化大模型实验与推理的桌面工具,支持多模型并行、Hugging Face集成及离线运行。:通过Docker或Python安装,需配置后端服务(如Ollama)。:输入卡顿、交互体验待优化,缺乏高级功能(如RAG、多模型管理)。:开源本地GPT客户端,主打轻量化与易用性,但功能较为

本文探讨了如何在16GB显存+32GB内存的平民硬件上高效部署大型语言模型。通过混合专家(MoE)架构的稀疏激活特性和Ktransformer技术的智能资源调度,成功突破了传统稠密模型的硬件限制。文章提供了经过实测的模型选型清单(包括Qwen3-30B-A3B等),详细解析了安全部署参数配置,并强调必须手动设置显存/内存占用上限(显存≤12GB,内存≤18GB)以确保系统稳定。
