- @weixin_64110589
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
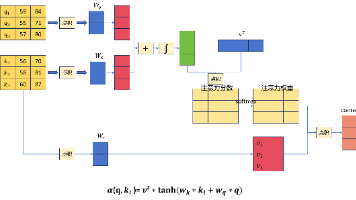
本文通过购物选择合适尺码的案例,类比介绍了注意力机制的工作原理及三种实现方式。首先以腰围尺寸匹配为例,说明线性回归、注意力权重分配和Softmax注意力三种方法的应用。接着引入多维度(腰围和胸围)的注意力计算,解释如何通过距离衡量相似度来分配注意力权重。文章详细对比了三种注意力实现方案:加性注意力通过非线性层计算相似度,适用于不同维度但计算量大;点积注意力计算高效但要求维度相同;缩放点积注意力针对
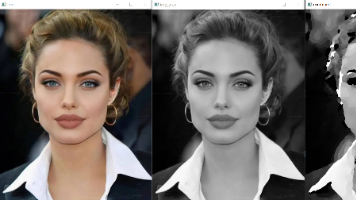
本文介绍了图像处理中的高通滤波技术及其应用,包括索贝尔算子、沙尔算子和拉普拉斯算子等边缘检测方法。通过Python代码演示了这些算子的实现过程,对比了不同算子的特点和适用场景。此外,还展示了图像特效处理方法,如浮雕效果、油画效果、彩色映射和镜像效果等。这些技术可用于图像增强、边缘检测和艺术效果处理,为计算机视觉任务提供了基础支持。
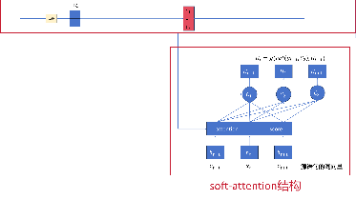
Soft-attention是一种可微的注意力机制,通过动态计算上下文向量来解决传统Encoder-Decoder结构的固定长度向量限制问题。它通过加权平均Encoder的隐藏状态,让Decoder选择性地关注输入序列的不同部分,提升了长序列处理能力和模型可解释性。虽然计算复杂度较高(O(N²)),但soft-attention在机器翻译、图像描述等任务中表现优异,成为处理序列数据的有效方法。其核
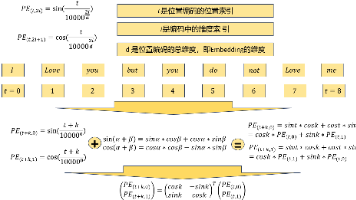
位置编码为Transformer模型提供序列顺序信息,弥补其自注意力机制缺乏位置感知的缺陷。绝对位置编码通过正弦/余弦函数生成位置向量,具有唯一性、连续性和可扩展性优势。这种编码不仅能表示绝对位置,还能通过三角函数特性隐含相对位置信息,使模型有效处理序列任务。
本文介绍了使用vLLM框架部署通义千问2.5-7B-Instruct大模型的完整流程。首先通过conda创建虚拟环境并安装PyTorch、vLLM等依赖包;然后从魔塔社区下载模型,利用vLLM的PagedAttention技术进行推理加速,实现模型加载和文本生成;最后部署OpenAI兼容API服务器,通过标准接口调用模型。文章包含环境配置、模型推理优化和API服务搭建三个核心环节,提供了完整的代码
GloVe是一种基于全局共现统计的词向量模型,相比Word2Vec能更好地捕捉词语间的语义关系。其核心是构建共现矩阵,通过统计单词在上下文窗口内的共现频率来训练词向量。本文展示了使用GloVe处理《三国演义》文本的完整流程:包括jieba分词、数据清洗、构建共现矩阵(窗口大小为10)、训练20维词向量(学习率0.05,10个epochs),以及查询词向量和语义相似词等应用。实验表明,GloVe能有

FastAPI提供多种数据验证方式确保API安全性和可靠性。通过Pydantic模型可对请求体进行类型检查和字段验证,支持默认值、必填项等设置。Query方式用于URL查询参数验证,支持长度、范围、别名等规则。Path方式验证路径参数,支持数值范围、正则表达式等条件。Field方式为模型字段添加更详细的验证规则和元数据,支持自定义验证器、枚举类型等。这些验证机制能自动生成文档并返回详细错误信息,结
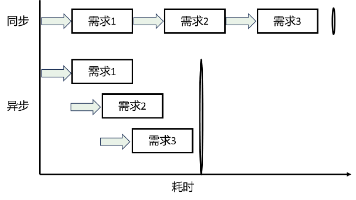
本文介绍了FastAPI中表单处理、异步编程和文件上传的实现方法。表单处理部分展示了三种方式:直接使用Form()声明字段、结合Pydantic模型和Annotated注解、以及在模型字段中直接使用Form()。异步编程部分对比了async/await和非异步函数的性能差异,演示了异步处理并发I/O操作的优势。文件上传部分涵盖了小文件和大文件的不同处理方式,包括内存存储、磁盘存储、多文件上传和文件
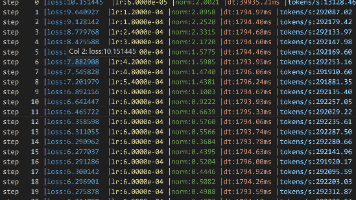
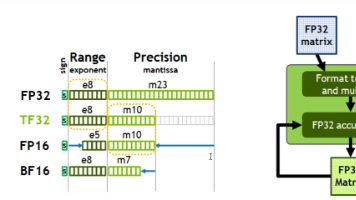
本文介绍了GPT-2模型的训练加速与优化技巧。在加速方面,主要采用四种方法:1)利用NVIDIA TensorCore进行混合精度计算加速;2)使用PyTorch的混合精度训练减少显存占用;3)应用torch.compile进行模型编译优化;4)采用FlashAttention加速长序列处理。 在训练技巧方面,重点包括:1)梯度裁剪防止梯度爆炸;2)采用余弦退火学习率调度策略;3)参数分组正则化;
本文实现了一个基于Transformer的GPT模型,并详细介绍了模型训练、预测及优化策略。主要内容包括:1)模型架构采用多层Transformer结构,实现自注意力机制和前馈网络;2)使用DDP分布式训练加速,支持梯度累积和混合精度计算;3)采用余弦衰减学习率调度器,结合线性预热策略;4)实现数据加载器,支持中文分词处理;5)提供完整的训练流程,包括梯度裁剪、权重衰减等优化技术;6)实现文本生成