登录社区云,与社区用户共同成长
邀请您加入社区
优化C++程序性能,本质上是让程序的行为模式更加适应硬件的这些特性,例如,通过提升局部性原理的运用,使得需要的数据尽可能地从高速缓存中获取,而非从缓慢的主内存中获取。相比“数组的结构体”(AoS),在需要顺序处理特定字段时,“结构体的数组”(SoA)布局通常能提供更好的缓存性能,因为它将同一类型的数据连续存放,更符合CPU缓存的预取机制。使用编译器优化标志(如GCC/Clang的 `-O2` 或
Python基于PaddleHub的新闻长文本分类系统 智能新闻分类平台FastAPI后端+Vue/QT前端 毕业设计(建议收藏)✅
,移动操作通过“窃取”临时对象(右值)的资源,避免了深拷贝的巨大开销。在实现自定义类时,正确实现移动构造函数和移动赋值运算符,并在函数中通过值返回局部对象(编译器会应用返回值优化RVO或移动),可以显著提升涉及大量数据传递的场景的性能。同样,在面向对象设计中,将频繁一起访问的数据成员放在一个类中(紧凑型结构),而非分散在不同对象中通过指针访问,也能有效提升缓存利用率。一个O(n2)的算法即使经过再
关注C++标准的演进(如C++17、C++20引入的新特性),积极参与开源项目,阅读优秀的源代码,都是提升自身水平的有效途径。STL提供了丰富而强大的组件,包括容器(如`vector`, `list`, `map`)、算法(如`sort`, `find`)和迭代器。学会组合使用STL的算法和容器,可以用更少、更清晰的代码实现复杂的功能,这不仅是能力的体现,也是编程艺术的升华。理解栈和堆的区别,并熟
此框架通过理论到实践的递进结构,结合具体代码和性能考量点,突出C++高级特性与优化策略的结合应用。本文将从内存管理、泛型编程、并行计算三大维度,结合实例阐述如何以编译器为笔,以代码为墨,写出既快速又优雅的代码。- 适用于数学常量与类型选择(如`std::conditional`)优化方案:通过右值引用与`std::move`实现资源转移。### 第四部分:STL算法优化:正确使用迭代器与执行策略。
📌 百度本次开源的模型是在PaddleOCR-VL基础上的升级版 PaddleOCR-VL-1.5,仍然保持 0.9B 的轻量级两阶段任务建模,核心改进点:🌟 布局检测模型架构升级:采用 PP-DocLayoutV3 布局检测模型实现像素级文档元素定位。🌟 训练策略与数据增强:引入强化学习后训练(GRPO),解决标注风格不一致问题。🌟 推理效率优化:采用异步多线程流水线架构。📌 实验效果
【摘要】用户在使用PaddleNLP时遇到ImportError,提示无法从aistudio_sdk.hub导入download函数。此问题源于aistudio_sdk版本升级(≥0.3.0)移除了该函数,与当前PaddleNLP版本不兼容。推荐解决方案为降级aistudio_sdk至0.2.6版本(pip install aistudio-sdk==0.2.6)。其他方案包括:创建虚拟环境隔离依
Lemos智能图谱知识库与免费且可本地部署的知识库(如部分开源Wiki、笔记软件)的核心区别在于其底层架构从“静态文档库”升级为“AI驱动的动态知识网络”,这带来了在知识组织、处理、应用及协作层面的系统性优势。
本文详细介绍了基于PaddlePaddle框架的语义分割和实例分割模型训练全流程。主要内容包括:1) 使用LabelMe工具进行数据标注的具体操作步骤;2) PaddleSeg环境的安装配置方法;3) 数据格式转换与数据集准备流程;4) 模型训练、评估和推理的具体实现步骤。文章分别针对语义分割(PP-LiteSeg-B模型)和实例分割(Mask-RT-DETR-L模型)两种任务,提供了完整的命令行
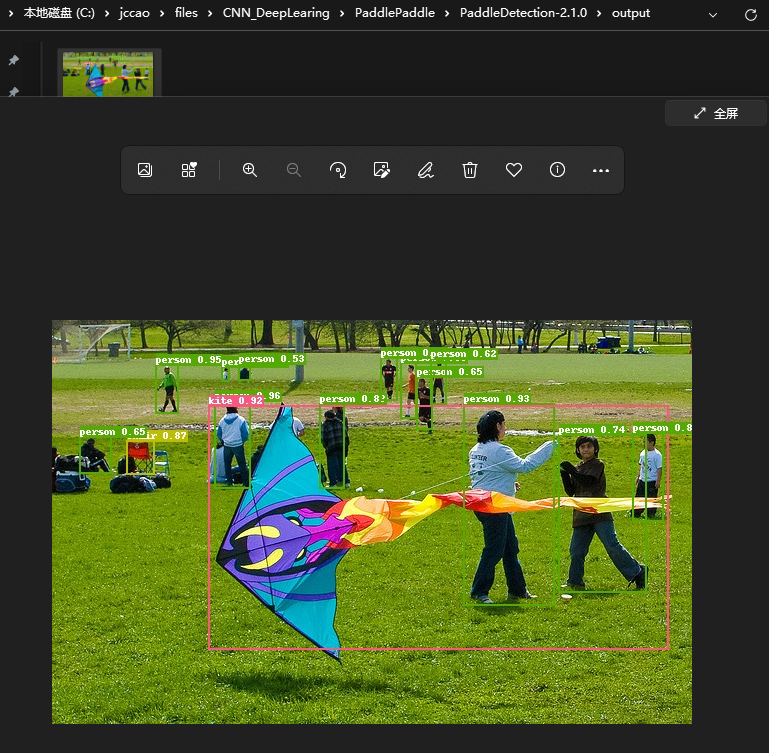
版本要求:PaddlePaddle 2.2cuDNN v8.1.1CUDA 11.2.2PaddleDetection 版本PaddlePaddle版本备注release/2.1>= 2.1.0默认使用动态图模式一、安装PaddlePaddlePaddlePaddle我已经安装过了,版本为2.2,安装教程:https://blog.csdn.net/qq_44447544/article/d
深度学习-PaddleOCR环境安装PaddleOCR环境安装官方文档:https://gitee.com/paddlepaddle/PaddleOCR/blob/develop/doc/doc_ch/installation.md说明:这里安装的也是可以的,但是安装的是老版本。快速安装按照文档,我们需要如下环境docker和nvidia-docker前面已经安装了,下面看一下我们的cuda和cu
经过了上一篇,我们已经体验过了Paddle3D的模型训练。这一篇来介绍一下数据集格式,方便我们自定义数据集进行训练。算法改为使用Pointpillars,通过本个项目,可以体现出P3D简单、高效的特点。通过本文你将学会1.一些传感器的基本知识2.如何组织KITTI格式的数据集3.使用Paddle3D的其他算法进行模型训练与导出
使用YOLO作为PaddleOCR的文本检测模块。
它定位为一个提供多种AI功能的独立学术研究写作和研发与项目写作平台,深度集成了Lemomate-AI和Lemos智能图谱知识库。1、 AI能力广度:产品功能极广(AI搜索、问答、Agent、多模态、数据分析、数据专业绘图、润色、翻译、解释等);5、AI智能图谱知识库Lemos:可以检索和调用你的私人专属知识库Lemos,用于论文、汇报材料和项目材料等等撰写;6、数据完全合理和保护:数据和你的创新i
PaddleOCR-VL多模态文档解析模型的本地部署与使用。相比传统OCR工具,PaddleOCR-VL不仅能识别文字,还具备理解表格、公式、图表等复杂文档结构的能力。文章提供了整合包下载方式,详细演示了从安装配置到识别印刷体、手写体和数学公式的全过程。该模型支持100+语言识别,参数规模适中(0.9亿),既适合本地部署又可结合cpolar实现远程访问,解决了传统OCR在隐私保护、批量处理和复杂文
本文介绍了将PaddlePaddle模型转换为ONNX格式的方法。指出新版本Paddle2ONNX(2.1.0)使用inference.json文件而非旧版的model.pdmodel文件。文章详细说明了转换命令格式,并提供了三个具体转换示例(文本检测、识别和方向分类模型)。同时给出了官方模型下载链接和转换后的效果展示。注意事项部分强调版本兼容性:PaddlePaddle需≥3.0.0且≤3.1.
本项目基于PaddlePaddle框架开发了一个中文新闻标题分类系统,采用BiLSTM模型实现端到端文本分类。系统亮点包括:字粒度编码降低未登录词影响,引入Dropout等正则化技术防止过拟合,支持财经、房产等10类新闻分类,测试准确率达90.59%。项目提供完整的训练评估流程、混淆矩阵可视化以及Tkinter图形化预测界面,模块化设计便于扩展。实验表明,针对短文本特性,BiLSTM能有效捕捉标题
本文记录了在内网环境中安装PaddleOCR时遇到的问题及解决方案。首先需要配置阿里云私有pip源并绑定IP白名单,根据兼容性列表安装指定版本的paddleocr(3.2.0)和paddlepaddle-gpu(3.2.2)。安装后出现libavcodec.so.61缺失错误,发现系统默认安装的ffmpeg6版本不兼容。由于官方源未提供ffmpeg7,需手动下载源码编译安装,过程中可能需补充其他依
如果你在做任何涉及文档的 AI 工作流,MinerU 值得试一下。它解决的不是"能不能提取文字"的问题,而是"能不能让 AI 真正读懂文档"的问题。这个区别,在实际项目里会差一个量级的效果。MinerURAGPDF解析AI工作流LangChainOpenClawAgentCSDN。
函数三:统计某个文本在列表中出现的次数,输出参数有两个,第一是我们需要查的文本,第二个是我们查找的列表。定义控制警报器的命令,后续用来发送指令。说白了,这个函数的作用就是每隔30分钟自动重启一次摄像头(time.sleep(1800)),防止摄像头长时间运行出现卡死,掉帧,无响应等问题,定期重启可以释放内存资源,重置摄像头状态,避免程序崩溃,。函数四:计算OCR识别框的面积,输入就是OCR识别的四
数据处理与投票机制,list_zong1,3次识别的原始结果(被装饰器控制),过滤掉只出现1次的结果(可能是误识别),set_bing替换掉易错的字符,然后取历史结果中出现最多的编码。摄像头2:3帧识别一次,一秒15帧,所以是5次每秒,摄像头3和摄像头2一样,这是。违规处理,触发报警,显示界面上的警告图标,触发报警器闪光,5000ms=5s,5秒后自动隐藏警告,关闭报警器。触发OCR识别,这里摄像
当时有人说“死了么”名儿晦气,建议叫“还活着”更吉利,但作者好像表态了:名字不改,就这么用。其实我觉得,守护老人最好的法子可能是在家安监控,时不时看看更放心。但要是不在家,比如老人出门溜达,用这APP报平安倒也不错!这软件得每天打卡报平安,要是超过24小时没动静,系统就会给你设的紧急联系人发短信、打电话,提醒对方你可能出状况了。你还能自己设提醒时间,是1天、2天还是3天没报平安才触发提醒。可设提醒
本地部署gpu版本paddleocr
PaddlePaddle是一个功能全面的深度学习框架由百度公司主导开发并开源。它最初源于2013年百度深度学习实验室创建的Paddle项目旨在支持大规模数据的多GPU和多机器并行训练。2016年9月百度正式将PaddlePaddle开源这标志着国内第一个机器学习开源平台的诞生。PaddlePaddle的名字来源于Parallel Distributed Deep Learning并行分布式深度学习
paddle
——paddle
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区






 CANN开发者社区
CANN开发者社区
 EazyDevelop社区
EazyDevelop社区

 DAMO开发者矩阵
DAMO开发者矩阵




 AtomGit AI 社区
AtomGit AI 社区


 AtomGit开源社区
AtomGit开源社区


 openEuler 社区
openEuler 社区
 腾讯云开发者社区
腾讯云开发者社区



