登录社区云,与社区用户共同成长
邀请您加入社区
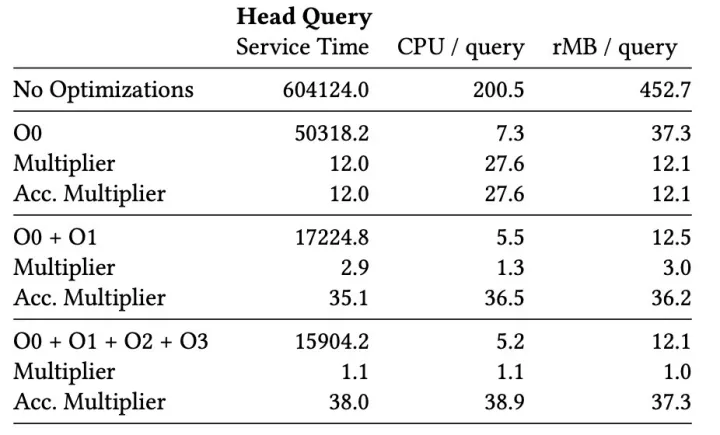
一次看似像 Easysearch BKD merge 逻辑 bug 的问题,最终通过代码级探针、JVM 对照实验和 Elasticsearch 复现,被收敛为旧版 Oracle GraalVM 21 构建相关的 JVMCI/Graal JIT 运行时问题,而不是 Easysearch 本身逻辑缺陷。
业务里有一类字段很「烦人」:PV、下载量、在线状态、实时计数——,但几乎不需要全文检索。_update_update_source_sourcelong——写入索引后,通过 REST API 按_id或 Query 批量改值;查询、排序、聚合读 mmap 里的最新值,_source。这就是es_update插件的由来。但在真正上线、。
你把目标拆解成了“方法级”的东西:addNode 是啥,freezeTail 是啥,reverse 是啥。你不会无缘无故放弃目标,你只会因为看到了一个更底层的、更根本的、更值钱的目标而“升级”它。FST 已经不是你最终的目标了,它变成了一个训练场,用来磨练你的拆解能力。· 你发现了一个更底层的东西——“怎么学”比“学会了什么”更值钱。而且往往不是目标“自己”变的,是你“发现”目标变了。把目标从“看
Unity游戏开发中对于文件操作是一个不可或缺的部分,尤其是需要存取玩家数据、配置信息或进行资源管理时,C#的文件操作成为了开发者的重要工具。JSON是目前在Web和游戏开发中非常流行的一种格式,Unity支持简单的JSON序列化与反序列化。为了简化这个过程,可以使用序列化(将数据结构转换成一连串的字节)与反序列化(将这串字节恢复成原来的数据结构)。在读写文件之前,经常需要检查文件或目录是否存在,
Lambda表达式是Java 8引入的一项重要特性,它允许将函数作为方法参数传递,极大地提升了代码的简洁性与可读性。其核心优势在于能够用更少的代码实现相同的功能,尤其适用于函数式编程场景,如集合操作、事件处理和多线程编程。通过Lambda,开发者可以避免编写冗长的匿名内部类,使代码更加紧凑和清晰。
// 当前元素// 移动到下一个元素,返回是否还有// 重置(很少用)📌 你不需要手动实现这些(除非自定义集合),但要理解其工作原理。
小杨会依次参加 m 场战斗,每场战斗小杨只能且必须选择一种武器使用,假设小杨使用了第 � 种武器参加了第 � 场战斗,战斗前该武器的熟练度为 c'_i,则战斗后小杨对该武器的熟练度会变为 c'_i + a_j。需要注意的是,a_j 可能是正数,0 或负数,这意味着小杨参加战斗后对武器的熟练度可能会提高,也可能会不变,还有可能降低。小杨想请你编写程序帮他计算出如何选择武器才能使得 m 场战斗后,自己
duce 的基本原理和设计思想。MapReduce是一个可用于大规模数据处理的分布式计算框架,它借助函数式编程及分而治之的设计思想,使编程人员在即使不会分布式编程的情况下,也能够轻松地编写分布式应用程序并运行在分布式系统之上。Hadoop 中的 MapReduce是一个易于使用的软件框架,基于此框架编写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠的方式并行处理TB或PB级
简介: Apache Mahout 专家 Grant Ingersoll 引领您快速了解最新版本 Mahout 中的机器学习库,并通过示例说明如何部署和扩展 Mahout 的某些最常用的算法。在软件的世界中,两年就像是无比漫长的时光。在过去两年中,我们看到了社交媒体的风生水起、大规模集群计算的商业化(归功于 Amazon 和 RackSpace 这样的参与者),也看到了数据的迅猛增长以
代码本身不依赖任何商业中间件,纯 .NET 4.5 + SuperSocket + SQL Server Express,却实现了“订单-出库-搬运-加工-检测-装配-回库”的完整闭环。一套面向离散制造的 WPF-MES 产线执行系统,在 101 个源码文件、4 万余行代码的体量下,用“软 PLC + 数据库 + Socket” 的三层架构,把 AGV、立库、加工、检测、装配五大区域串成一条“黑灯
你是否遇到过这样的困扰:游戏数值需要频繁调整,每次都要重新编译代码?策划想要修改角色属性,程序员不得不反复修改代码?今天就来介绍Unity中的"数据驱动"神器——ScriptableObject,它将彻底改变你的开发流程!
如果我是现在在迪拜、阿布扎比或者沙迦做生意的老板,我看官网这件事,先看一条:能不能快点上线,能不能别把团队拖进无休止沟通里。BBWEYY适合的就是这种场景。BBWEYY秒建网站,企业专用。BBWEYY 的一个很强的点,在于它走的不是单纯模板路线,也不是单纯 AI 路线,而是AI+SAAS模式。这套模式的价值,是把前期效率和后期稳定性放在一起。前面用 AI 提速,后面靠 SaaS 去承接、管理和持续
摘要 本文通过Nginx日志管理案例,系统阐述ELK Stack(Filebeat+Logstash+Elasticsearch+Kibana)的实战部署方案。重点解析四层架构设计(采集→处理→存储→展示),详细说明Filebeat多源日志采集配置、Logstash Pipeline的JSON格式解析与Grok正则处理技巧,以及基于索引生命周期管理(ILM)的热温冷分层存储策略。最后展示Kiban
本文讲解了.cs文件的查看与运行方法:.cs是C#纯文本源码文件,需编译运行。查看时推荐使用OpenFiles查看器(支持语法高亮和AI对话),无需安装环境即可阅读和提问。运行则需.NET SDK,可通过dotnet命令或Docker方式编译执行。文章还对比了不同查看工具的优缺点,并提供了常见问题解答,帮助开发者高效处理.cs文件。
为例,该系统不仅实现了合同的全生命周期管理,包括合同起草、审批、签署、执行、归档等各个环节,还融入了先进的自然语言处理技术和机器学习算法,使合同管理更加智能化、自动化。通过系统的实施,企业实现了合同全生命周期的电子化管理,合同审批时间缩短了80%,合同履行率提升了30%。在当今瞬息万变的商业环境中,企业如同航行在波涛汹涌的大海上的船只,既要应对外部环境的剧烈变动,又要应对内部管理的复杂挑战。然而,
倒排索引(Inverted Index)是 Lucene 和 Elasticsearch 的灵魂,是全文检索能做到秒级响应的核心数据结构。几乎所有搜索引擎、大数据检索组件,底层都依赖倒排索引。但绝大多数开发者只知其名,不知其实现。本文从原理 → 结构 → 构建流程 → 代码实现 → 检索流程,用最通俗的方式带你从零实现 Lucene 倒排索引,彻底搞懂 ES 为什么快。文档ID → 单词列表需要遍
做个网站加上客服功能,现在市面上找一圈全是坑——Intercom每月几百起步、Zendesk更贵、国产那几个平台看着便宜但功能全砍在免费版里,想要多渠道接入想要数据报表想要AI客服,对不起请升级企业版。更让人不放心的是,所有对话记录都存在人家服务器上,哪天平台涨价或者倒闭,你连讨价还价的资格都没有。
2025年Apache Lucene迎来爆发式增长:全年完成1,756次提交和8个版本发布,社区新增98位贡献者。性能优化成效显著,查询速度提升60%达到170qps,主要受益于自动向量化、SIMD优化及批量打分等创新。向量搜索领域实现三大突破:ACORN算法提升过滤搜索效率、多段搜索优化并发一致性、批量打分接口显著降低计算开销。运维层面改进包括堆外内存监控和HNSW索引优化。尽管修复一个复杂bu
Lucene的常用检索类1、IndexSercher:检索操作的核心组件,用于对IndexWriter创建的索引执行,只读的检索操作,工作模式为接受Query对象而返回ScoreDoc对象。2、Term:检索的基本单元,标示检索的字段名称和检索对象的值,如Term("title", "lucene")。即表示在title字段中搜索关键词lucene。3、Query:表示查询的抽象类,由
一、POI对Word处理1、读取Word1、读取Excel3、下载地址:http://www.apache.org/dyn/closer.cgi/poi/dev/代码实现:package com.qianyan.test;import java.io.File;import java.io.FileInputStream;import org.apache.poi.h
mahout使用:步骤一:tar -xvf mahout-0.3.tar.gz需要指定hadoop的路径和配置文件的路径export HADOOP_HOME=/home/hadoopuser/hadoop-0.19.2 export HADOOP_CONF_DIR=/home/hadoopuser/hadoop-0.19.2/conf步骤二:通过这个命令可以查看mahout提供了哪些算...
问题原因:IndexWriter原因是在上一次使用该对象进行索引写入的时候,并没有完全关闭资源—表现为写索引的目录下有名称类似“lock”(一般在最后一行)的文件,即witer对象处在锁状态,可能是为了避免同时写入导致数据出错。解决办法:在写索引的方法中,使用finally语句块将IndexWriter关闭。indexWriter.close();
由于刚开始理解错误,以为搜索索引可以作为数据挖掘的输入信息,后面才发现错了,由solr/nutch/lucene形成的只是搜索索引,只要由用户提供查询关键字,然后就可以查到该关键字来自哪一篇文档,并不是一篇文档的文字列表信息,而挖掘是需要有整篇文档的文字列表(档中所有单词的集合)
<br />Lock obtain timed out: SimpleFSLock@E://javasource//LuceneTest//index//write.lock异常的原因:<br /> <br />1、 lucene在写入索引时, 用在索引目录下建write.lock文件来标识锁定. 而只有在执行close()方法后, 才会删除这个锁文件. 只要这个文件存在, 其他的写索引的程序都会
<br />小小的原因,中间看了些东西,但没有时间整理。今天整理如下:小结(1)中对Google的云平台三大技术发表了一些粗浅的认识。这篇文章里,我们回来认识下Hadoop :<br />Hadoop原来是Apache Lucene下的一个子项目,它最初是从Nutch项目中分离出来的专门负责分布式存储以及分布式运算的项目。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Lucene 是一个高效的,基于Java 的全文检索库。所以在了解Lucene之前要费一番工夫了解一下全文检索。那么什么叫做全文检索呢?这要从我们生活中的数据说起。我们生活中的数据总体分为两种:结构化数据 和非结构化数据 。结构化数据: 指具有固定格式或有限长度的数据,如数据库,元数据等。非结构化数据: 指不定长或无固定格式的数据,如邮件,word文档等。
在去年的时候,就想把lucene,solr,nutch和hadoop这几个东东给详细的介绍下,但由于时间的关系,我还是只写了两篇文章,分别介绍了一下lucene和solr,后来就没有在写了,但我心里还是期待的,虽然到现在我没有真正搞过nutch和hadoop实战项目,但公司马上就要做hadoop大数据的监控了,我一直都说,要做一个有准备的人,因此我从去年到现在从未停止过对hadoop相关技术的学习
Unity 与 G29 的结合提供了极大的开发可能性,从赛车游戏到模拟器应用,都能通过高精度输入与力反馈技术实现卓越的用户体验。通过扩展动态赛道生成、AI 驾驶、物理模拟和跨平台支持,可以开发出更丰富、更真实的游戏体验。力反馈(Force Feedback)是 G29 的核心特性之一,用于模拟方向盘在驾驶中的物理阻力。在长时间驾驶中(尤其是竞速模式),方向盘的反馈强度可以根据玩家的驾驶表现动态调整
这就是iptables的目的。默认的配置文件solr.in.sh的选项ENABLE_REMOTE_JMX_OPTS字段值被设置为”true”,这会启用JMX监视服务并会在公网中监听一个18983的RMI端口,没有任何认证,也就是说在无需身份验证情况下,攻击者结合使用JMX RMI就会造成远程代码攻击。可以通过“打开”或“关闭”(即过滤)为特定类型的流量指定的端口来允许或阻止流向特定应用程序的流量。
IndexWriter在初始化索引的时候会为这个索引加锁,等到初始化完成之后会调用其close()方法关闭IndexWriter,在close()这个方法的内部其实也是调用了unlock()来释放锁,当程序结束后IndexWriter没有正常关闭的时候就会报。document4.add(new TextField("fgname","中华人民共和国劳动法", Field.Store.YES));/
同时我们也利用线上数据进行了测试,线上数据测试过程中也伴随着大量的写入操作,由于写入操作在大规模分布式查询中容易由于 IO 抖动造成长尾,这种长尾对优化后的系统影响尤其大,因此,我们也顺便优化了 IO,避免这种长尾抖动。非常不幸的是,日志数据的时间戳恰恰是这种高基维数据,而且对日志的搜索,通常都需要指定时间戳范围。在搜索系统中,每一条日志都会被指定一个唯一的编号,比如有 1000 条数据,就会给每
安装 Solr5.2.1Solr下载:http://archive.apache.org/dist/lucene/solr/5.2.1/solr-5.2.1.tgz把solr-5.2.1.tgz 上传 /root/software tar -zxvf solr-5.2.1.tgz -C /usr/local/[root@hd01 software]# cd /usr/local/[root@hd0
DistinctBy方法是 .NET 6 和 .NET 7 中 LINQ 的一个非常实用的新特性。我们在 LINQ 查询中根据指定的键对集合进行去重,简化了代码并提高了开发效率。希望本文能帮助大家更好地理解和利用 .NET 6 和 .NET 7 中 LINQ 的DistinctBy方法,从而在项目中发挥更大的作用。
只要学习 Elasticsearch,就一定会听到Lucene这个词。Lucene 是什么?和 ES 到底是什么关系?Elasticsearch 的底层就是 Lucene。没有 Lucene,就没有 Elasticsearch。本文用最通俗、最详细、最系统的方式,带你彻底搞懂 Lucene 及其与 Elasticsearch 的关系,包含定义、功能、架构、流程图、区别与联系。Lucene是 Apa
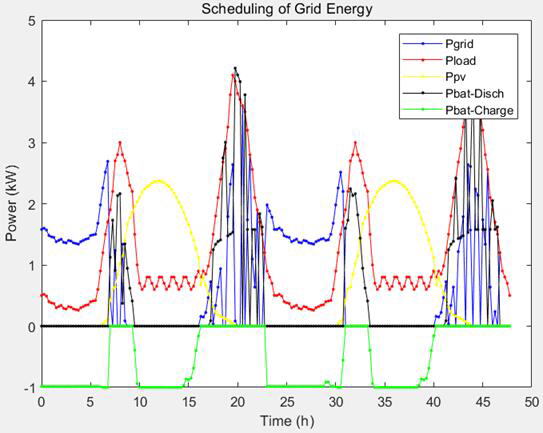
本系统实现了一个面向微电网场景的储能电池容量优化配置模型,采用混合整数线性规划(MILP)方法,在满足系统运行约束的前提下,以最小化运行成本为目标,联合优化储能容量、充放电策略以及与主网之间的购售电行为。该模型充分考虑了实际工程中的关键非线性因素(如逆变器效率分段特性、电池充放电效率、容量边界等),并通过线性化建模技巧将其纳入MILP框架,兼顾了求解精度与计算效率。
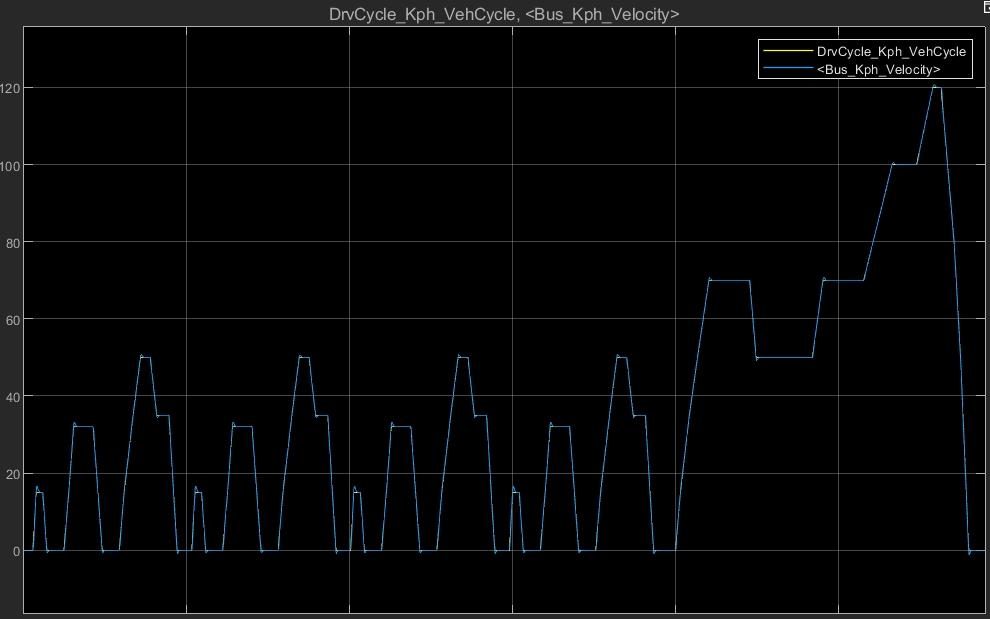
先看整体架构,模型结构清爽得就像五线谱:电池包(Battery Pack)供电给电机控制器(Motor Controller),驱动电机(Traction Motor)带着减速器(Final Drive)给整车(Vehicle Dynamics)上劲。带学生做驱动系统设计时,让他们在现有模型上魔改——有个小组把永磁同步电机换成异步电机模型,通过对比两种电机在WLTC工况下的效率分布,作业直接达到了
Lucene.netLucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,是一个高性能、可伸缩的文本搜索引擎库。它的功能就是负责将文本数据按照某种分词算法进行切词,分词后的结果存储在索引库中,从索引库检索数据的速度非常快。Lucene.net需要有索引库,并且只能进行站内..
Apache Atlas 编译开发环境部署
一:http://blog.csdn.net/weizengxun/article/details/8068749二:http://www.cnblogs.com/think_fish/archive/2011/06/17/2083861.html三:https://www.cnblogs.com/magicchaiy/archive/2013/06/07/LuceneNet%E7%9B%
lucene
——lucene
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区



 2048 AI社区
2048 AI社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI Agent技术社区
AI Agent技术社区


 AI硬件创业社区
AI硬件创业社区

 DAMO开发者矩阵
DAMO开发者矩阵




 AtomGit开源社区
AtomGit开源社区

 智能体开发者社区
智能体开发者社区



 脑启社区
脑启社区




 openEuler 社区
openEuler 社区


 腾讯云开发者社区
腾讯云开发者社区


















 昇腾开源生态专区
昇腾开源生态专区



