登录社区云,与社区用户共同成长
邀请您加入社区
当前单表数据量在1000来w,从kafka上拉数据异步批量插入,每次插入数据量1500条,测试的时候还没问题,结果上线没多久,kafka服务器直接挂了,赶忙看日志,kafka服务器堆积了几十G的数据,再去看生产环境日志,发现到最后单次批量插入用时固定在10多秒,甚至20多秒,kafka直接把消费端踢出了消费组…方法不支持分批插入,也就是有多少直接全部一次性插入,这就可能会导致最后的sql拼接语句特
分页确保注册分页插件;大表分页尽量用游标分页;count 查询可缓存或优化索引。批量更新避免 for 循环逐条更新;优先用或自定义 foreach。性能优化少用select *,明确字段;合理设计索引;避免 N+1 查询,多用 in 查询批量获取。MyBatis-Plus 已经解决了大部分通用问题,但在实际业务中:如果你遇到复杂多表查询,可能需要自己写 SQL,而不是依赖 MP 提供的 CRUD;
文章摘要: MyBatis-Plus分页与性能优化指南介绍了RuoYi-Vue-Plus框架中如何高效实现数据分页。重点讲解了PaginationInterceptor分页插件的配置方法,包括数据库类型设置、单页最大限制等参数。通过代码示例展示了基础分页查询、自定义分页查询以及不查询总数的分页实现方式。最后介绍了分页参数封装类PageQuery的设计,包含分页大小、当前页码等关键属性校验,为开发高
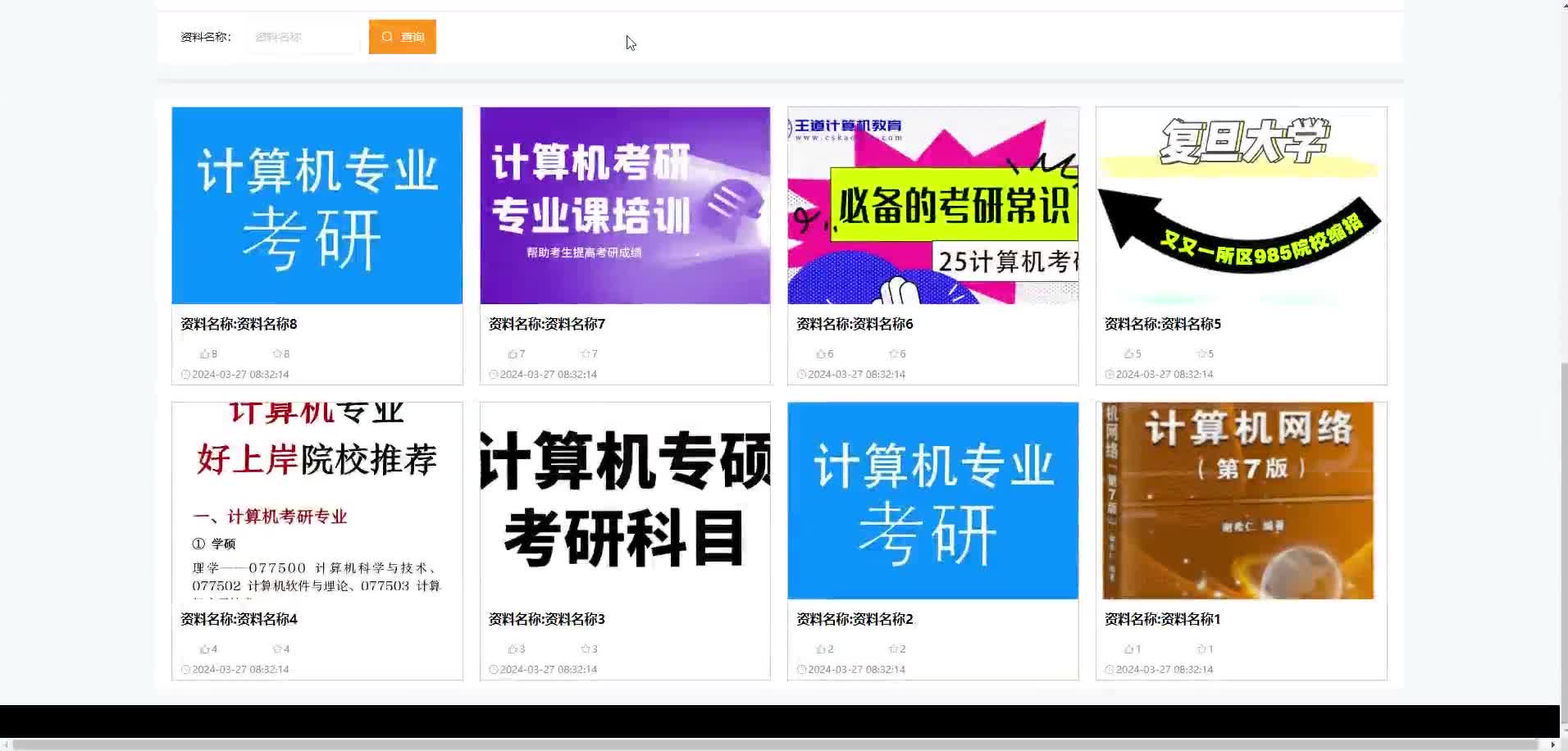
前端:Vue、Vue.js、ElementUI后端:SpringBoot+Mybatis数据库:MySQL、SQLServer开发工具:IDEA、Eclipse、Navicat等✌关于毕设项目技术实现问题讲解也可以给我留言咨询!!!Vue 在程序设计中具有诸多优势。它的简洁语法、组件化开发、强大的指令系统和有效的状态管理,使得程序设计者能够快速构建出高性能、交互性强的应用程序。无论是小型项目还是大
Jdk1.8 + Tomcat8.5 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。Springboot + mybatis + Maven + Vue 等等组成,B/S模式 + Maven管理等等。2. 前端:vue+css+javascript+jQuery+easyUI+hig
Jdk1.8 + Tomcat8.5 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。JAVA + mybatis + Maven + Vue 等等组成,B/S模式 + Maven管理等等。2. 前端:vue+css+javascript+jQuery+easyUI+highchart
Jdk1.8 + Tomcat8.5 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。Springboot毕设项目美术外包平台zbc9vjava+VUE+Mybatis+Maven+Mysql+sprnig)Springboot + mybatis + Maven + Vue 等等组成
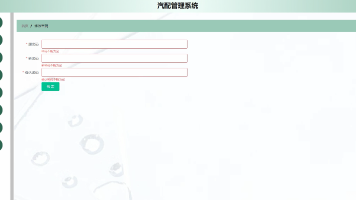
Jdk1.8 + Tomcat8.5 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。Springboot毕设项目汽配管理系统p06mljava+VUE+Mybatis+Maven+Mysql+sprnig)Springboot + mybatis + Maven + Vue 等等组成
Jdk1.8 + Tomcat8.5 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。Springboot毕设项目在线医疗评价系统70123java+VUE+Mybatis+Maven+Mysql+sprnig)JAVA + mybatis + Maven + Vue 等等组成,B/S
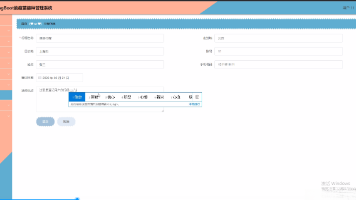
properties文件。
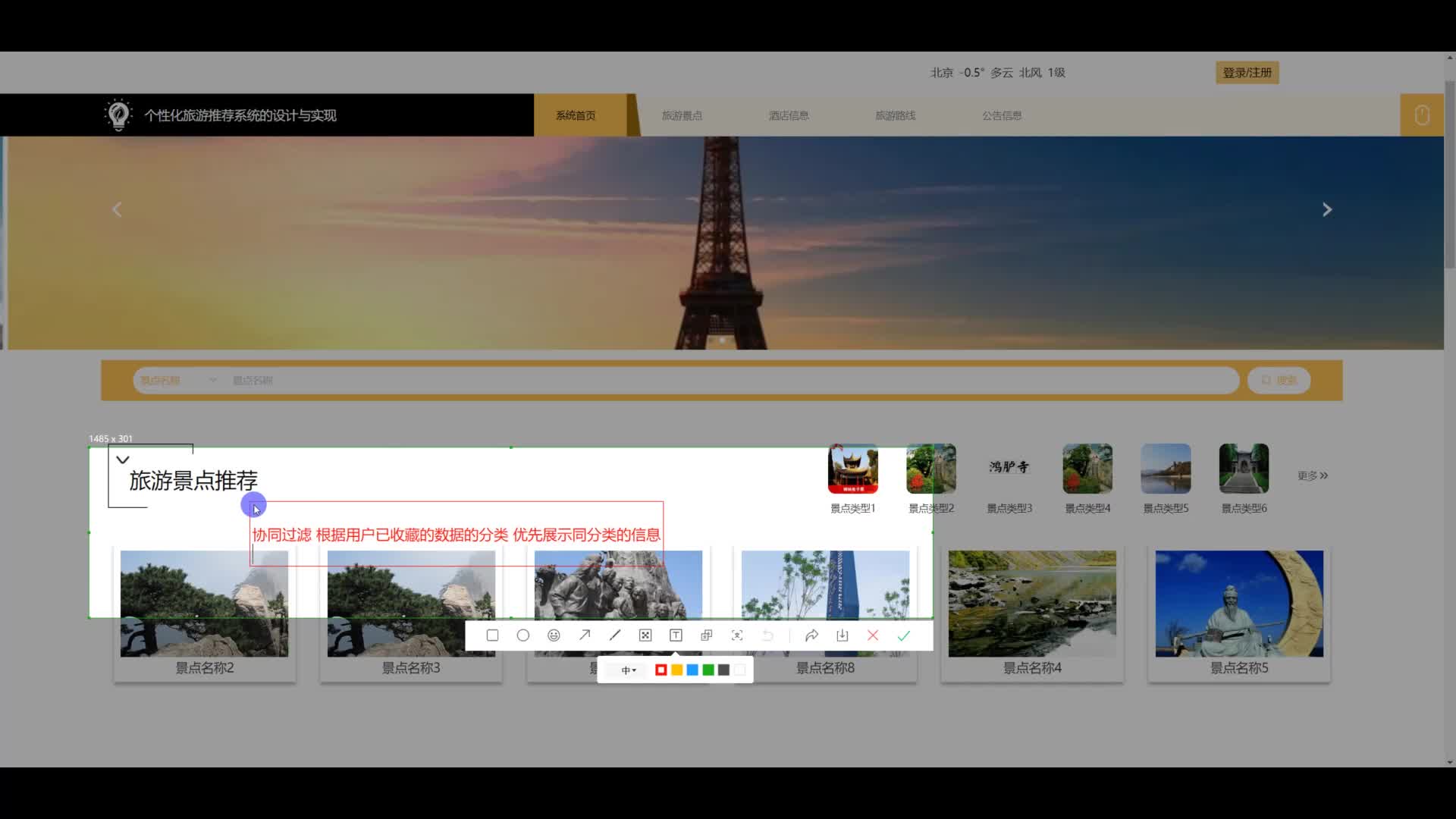
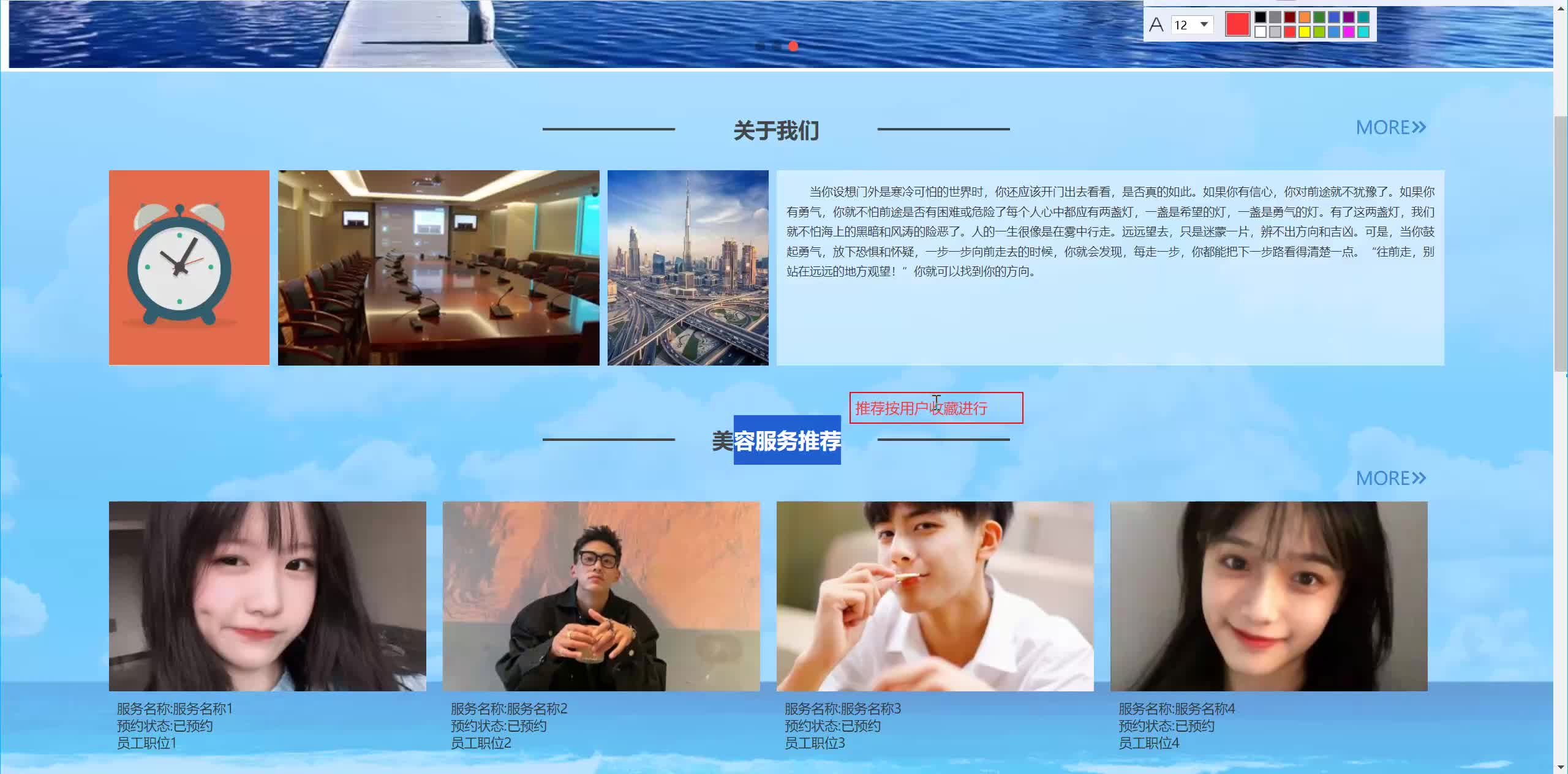
基于SpringBoot+Vue+Redis在线商城管理系统设计与实现
Jdk1.8 + Tomcat8.5 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。Springboot毕设项目校内二手交易平台9q8p4java+VUE+Mybatis+Maven+Mysql+sprnig)Springboot + mybatis + Maven + Vue 等等
本文介绍了Java开发中三大主流框架——Spring、SpringMVC和MyBatis的核心功能与整合应用。Spring框架提供依赖注入(DI)和面向切面编程(AOP)两大核心特性,降低代码耦合度;SpringMVC采用MVC模式构建Web应用,实现请求分发与视图渲染;MyBatis简化数据库操作,支持动态SQL。通过详细示例展示了如何将三大框架整合,构建完整的JavaWeb应用架构。文章强调框
这篇文章主要是为自己留个档,顺便分享一下所看的面试题网址。[MyBatis-Plus 枚举映射方案][MyBatis-Plus 面试题汇总][Maven 面试题详解]
Jdk1.8 + Tomcat8.5 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。Springboot毕设项目考勤打卡系统 k0e7rjava+VUE+Mybatis+Maven+Mysql+sprnig)Springboot + mybatis + Maven + Vue 等等组
springboot vue mysql 项目设计完整源码
Jackson默认不支持Java8的LocalDateTime类型,报错提示需引入jackson-datatype-jsr310模块。解决方案是添加该依赖并配置ObjectMapper:注册JavaTimeModule模块,设置日期格式为"yyyy-MM-dd HH:mm:ss.SSS"。在RedisTemplate配置中,同样需要注册该模块并进行序列化设置,包括Visibil
mybatis
——mybatis
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区





 AI Agent技术社区
AI Agent技术社区