登录社区云,与社区用户共同成长
邀请您加入社区
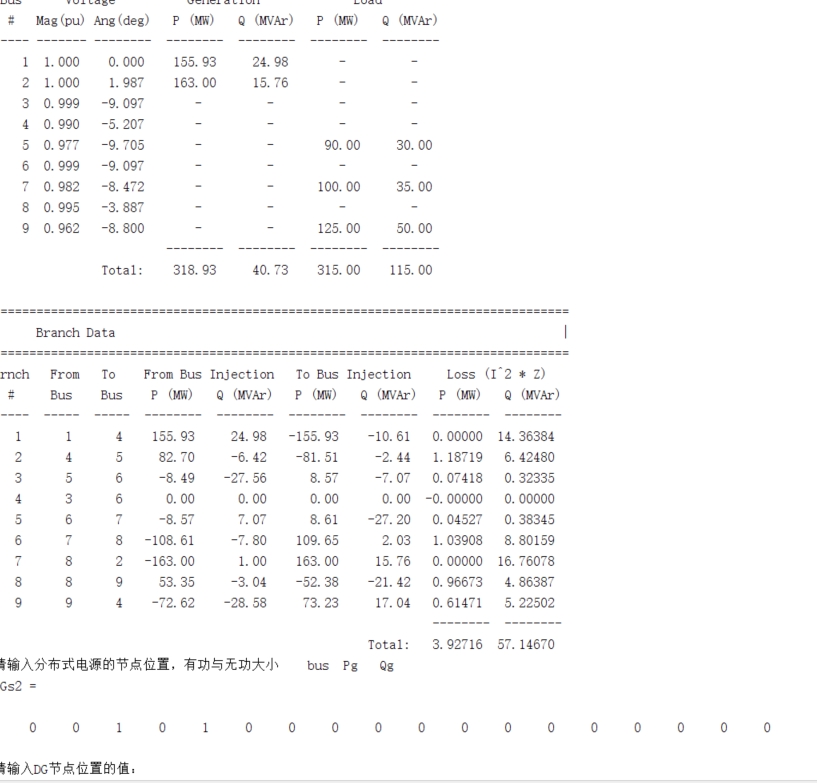
分布式电源接入对配电网的影响(matlab程序)分布式电源的接入使得配电系统从放射状无源网络变为分布有中小型电源的有源网络。带来了使单向流动的电流方向具有了不确定性等等问题,使得配电系统的控制和管理变得更加复杂。但同时,分布式电源又具有提高电网可靠性,绿色节能等优点,所以为更好的利用分布式电源为人类造福,我们必须对其进行研究与分析。本文利用仿真软件Matlab编写计算潮流程序模拟分布式电源接入配电
Redis Cluster是Redis官方提供的分布式解决方案,通过哈希槽分片实现水平扩展,结合主从复制和自动故障转移保障高可用。核心架构包含3个主节点和3个从节点,采用无中心化设计,节点间通过Gossip协议通信。关键机制包括哈希槽分片(16384个槽位)、主从复制、故障自动转移(基于投票机制)等。集群通过CRC16算法计算键的槽位,客户端根据MOVED指令重定向请求。这种设计支持动态扩缩容,仅
摘要:本文介绍了如何在NoSQL数据库中使用Hibernate OGM进行对象映射和持久化操作。通过MongoDB示例,详细展示了项目配置、实体定义、DAO层实现以及服务层开发的全过程。内容包括添加必要依赖、配置Hibernate OGM连接参数、定义Person实体类、创建Repository接口、实现CRUD服务方法等关键步骤,为开发者提供了完整的NoSQL数据库集成方案。
MongoDB 简介与环境搭建摘要 MongoDB是一种NoSQL文档数据库,相比传统关系型数据库具有灵活Schema、高性能和易扩展等优势。本文介绍了MongoDB的核心特性,包括文档存储、动态Schema、副本集和分片机制等,并通过对比表格展示了它与关系型数据库的主要区别。详细讲解了Windows、macOS和Linux系统下的安装步骤,以及基本配置方法。文章还包含MongoDB工作原理流程图
本文介绍了MongoDB的核心CRUD操作(增删改查),包含插入文档(insertOne/insertMany)、条件查询(find/findOne)、更新数据(updateOne/updateMany)和删除文档(deleteOne/deleteMany)的基本语法和常用操作符。特别强调了投影查询、批量操作技巧和安全删除注意事项,并提供了10道面试题和重点回顾表格。通过学习这些基础操作,读者可以
本文介绍了优化MongoDB写操作性能的10种策略:1)使用批量操作减少开销;2)调整写入关注级别平衡性能与安全;3)合理创建索引;4)控制并发写入数量;5)优化更新操作;6)使用分片分散负载;7)配置副本集实现读写分离;8)调整存储引擎参数;9)定期维护索引和碎片整理;10)设计高效数据模型。这些方法可显著提升高吞吐量应用中的写入性能,需根据具体业务需求和资源情况灵活选用。
Redis 官方提供三种高可用方案,能力逐级增强,适用场景从单机备份到分布式海量缓存逐步升级。表格。
NoSQL 也称为“not only SQL”或“non-SQL”,它是一种数据库设计方法,可以在关系数据库中的传统结构之外存储和查询数据,NoSQL 数据库并非采用关系数据库的典型表结构,而是将数据存储在一个数据结构中,例如 JSON 文档。由于这种非关系数据库设计不需要使用架构,因此,它提供快速可扩展性以管理通常为非结构化的大型数据集。简单来说,NoSQL数据库通过放弃关系型数据库的某些严格限
MongoDB核心知识体系摘要(150字) MongoDB作为文档型NoSQL数据库,采用「数据库→集合→文档」三级无模式结构,支持灵活嵌套和动态字段。核心特性包括BSON二进制存储、多级索引体系(基础/文本/地理/TTL/部分索引)、WiredTiger引擎的MVCC并发控制。架构层面提供副本集(主从选举+Oplog同步)和分片集群(哈希/范围分片)两种扩展方案,支持多文档ACID事务(4.2+
YCSB(Yahoo!Cloud Serving Benchmark)是 Yahoo 研究院开源的,支持 Redis、MongoDB、HBase、Cassandra 等。YCSB的工具原理主要包括工具模型、负载生成器和操作执行。
MongoDB是一种文档型NoSQL数据库,以JSON格式存储数据,具有结构灵活、无需预定义字段的特点。本文介绍MongoDB基础概念(类比MySQL)、CRUD操作,分析其核心优势(高写入性能、支持嵌套数据)和适用场景(日志、物联网、动态字段业务)。同时指出不适用场景(强事务、多表关联),并提供选型建议:结构固定/强关联业务选MySQL,多变结构/海量数据选MongoDB。最后给出开发注意事项,
我几乎每天都被问到这个问题。在 LangChain,我们开发工具,帮助开发者构建大型语言模型 (LLM) 应用。这些应用就像会思考的引擎,能与外部信息和计算资源互动。人们常把这类系统叫做 “代理”。对于 AI 代理 (AI Agent),每个人的理解都有些不同。我的理解可能更技术化:AI 代理是一个系统,它用 LLM 来决定应用程序的控制流程 (Control Flow)。即使这样,我也觉得我的定
随着大型语言模型(LLM, Large Language Models)在自然语言处理(NLP)领域的不断进步,越来越多的开发者对这一领域产生了浓厚的兴趣。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。作为一名从业五年的资深大模型算法工程师,我经常会收到
—每秒百万级写入的底层支撑技术。
云原生优势:AWS DynamoDB/MongoDB Atlas支持自动扩展、全球多活。适用场景:半结构化数据、动态Schema、高并发写入。适用场景:小型项目、临时数据交换、跨平台兼容需求。局限:不支持复杂数据结构,单文件建议不超过1GB。适用场景:结构化数据、事务支持、复杂查询需求。优化建议:批量插入、索引优化、连接池管理。优势:格式简单、体积小、兼容Excel。适用场景:嵌套数据结构、API
良好的类设计意味着高内聚和低耦合,即类的职责单一,且与其他类的依赖关系最小化。理解虚函数表(vtable)的工作原理、纯虚函数与抽象基类的定义,以及何时使用`override`和`final`关键字,是掌握运行时多态的核心。C++标准模板库(STL)是泛型编程最成功的应用范例,它提供了丰富且高效的容器(如vector、map、set)、算法(如sort、find)和迭代器。了解虚函数表指针(vpt
通过不断探索,科学家和艺术家们正在推动这一领域向着更加包容和普惠的方向发展。该领域的实践不仅促进了技术进步,还为理解世界提供了新的视角。通过不断探索,科学家和艺术家们正在推动这一领域向着更加包容和普惠的方向发展。该领域的实践不仅促进了技术进步,还为理解世界提供了新的视角。通过不断探索,科学家和艺术家们正在推动这一领域向着更加包容和普惠的方向发展。该领域的实践不仅促进了技术进步,还为理解世界提供了新
MySQL与MongoDB都是开源的常用数据库,但是MySQL是传统的关系型数据库,MongoDB则是非关系型数据库,也叫文档型数据库,是一种NoSQL的数据库。它们各有各的优点,关键是看用在什么地方。
厦门大学数据库实验室,http://dblab.xmu.edu.cn/
点关注公众号,回复“1024”获取2TB学习资源!前面介绍了WT 存储引擎、复制集、分片技术、集群部署与管理维护、备份与恢复、状态检测与性能追踪等相关的知识点。今天我将详细的为大家介绍一款 MongoDB 客户端管理工具相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!更多关于 MongoDB 数据库的学习文章,请参阅:NoSQL 数据库之 MongoDB,本系列持续更..
一、NoSQL简介1、简介NoSQL最常见的解释是“non-relational”, “Not Only SQL”也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。NoSQL是一项全新的数据库革命性运动,其拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。NoSQL有如下优点:
本课程基于Abaqus,应用两种加载方式一-FluidCavity与Pressure分别介绍了气动驱动软体机器人仿真分析流程。该软体机器人涉及两种材料,主变形部分选用超弹性材料,应用Yeoh本构定义材料属性;限制层部分定义为线弹性材料。此外,对结果的后处理进行了简要介绍。想学轮胎充气、气囊充气、各种充气分析都能用最近学习了一个超有意思的课程,基于Abaqus平台,深入探讨了气动驱动软体机器人的仿真
gbase 8a学习系统数据库运维知识
ArangoDB数据库入门作者:chszs,转载需注明。博客主页:http://blog.csdn.net/chszs一、ArangoDB介绍ArangoDB是一个开源NoSQL数据库,官网:https://www.ArangoDB.org/ArangoDB支持灵活的数据模型,比如文档Document、图Graph以及键值对Key-Value存储。ArangoDB同时也是一个高性能的数据库,它使用
所以我判断 Navicat 对 Mongo 的支持不太好,大家在使用过程中自行判断该问题,尽量别使用 Navicat 了,很多朋友都比较喜欢这款工具,但是它是收费工具。今天遇到了一个情况,在 Mongo 中进行查询时,使用 Navicat 连上去做 count 操作几分钟都没有返回结果。正常来说 count 速度会秒内返回,于是我想用 explain 看一下执行计划,是什么影响到结果返回。于是我从
在电动工具、储能电源、小家电设备、大功率移动设备等场景中,多串锂电池组凭借高电压、大功率输出成为核心动力源。快充需求持续升级,如何在缩短充电时长的同时保障电芯寿命与使用安全,成为技术研发的核心命题。本文从原理、方案、应用与安全四大维度,全面解读多串锂电池快充技术。
NoSQL是指对于不同于传统关系数据库的数据库管理系统的统称。非关系数据库以键-值存储、列存储、文档存储、图形数据库等形式来组织和存储数据。NoSQL(Not Only SQL)是一种非关系型数据库,它与关系型数据库(如MySQL、PostgreSQL等)相对。NoSQL数据库的设计旨在解决大规模数据集的存储和检索问题,尤其是在分布式环境中。非关系型结构:NoSQL数据库不依赖于固定的表格模式,因
1.背景介绍1.背景介绍NoSQL数据库是一种非关系型数据库,它的设计目标是为了解决传统关系型数据库(RDBMS)在处理大量不规则数据和高并发访问方面的不足。NoSQL数据库可以分为四种类型:键值存储(Key-Value Store)、列式存储(Column-Family Store)、文档存储(Document Store)和图形数据库(Graph Database)。在选择NoSQ...
nosql
——nosql
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区

 AI编程社区
AI编程社区









 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI Agent技术社区
AI Agent技术社区




 DAMO开发者矩阵
DAMO开发者矩阵









