登录社区云,与社区用户共同成长
邀请您加入社区
在C#中解析XML时遇到注释节点报错的问题,这是因为XML注释节点(-- -->)是特殊的节点类型。当遍历XML节点时,注释节点也会被包含在内,但它们不能像普通元素节点那样处理。
右值引用和移动语义是Modern C++性能优化工具箱中的利器。通过理解左值/右值的本质,掌握`std::move`和`std::forward`的适用场景,我们能够编写出既高效又安全的代码。从实现自定义类的移动操作,到在通用代码中应用完美转发,这些特性已经深入到现代C++开发的方方面面,是每一位C++开发者必须熟练掌握的核心知识。
LINQ(Language Integrated Query)是C#中的强大功能,它允许以声明式方式查询数据源(如集合、数据库或XML)。Lambda表达式则提供简洁的匿名函数语法,常用于LINQ查询中定义操作。所有数学相关表达式(如集合操作)将使用$...$格式表示,确保清晰易懂。推荐练习:实现一个LINQ查询,从对象列表中过滤并转换数据(如计算员工的平均工资)。Lambda表达式是匿名函数,用
在 C# 中,是 .NET 提供的一套强大而统一的,让你可以用类似 SQL 的方式,(如数组、列表、数据库、XML 等)。。
// 当前元素// 移动到下一个元素,返回是否还有// 重置(很少用)📌 你不需要手动实现这些(除非自定义集合),但要理解其工作原理。
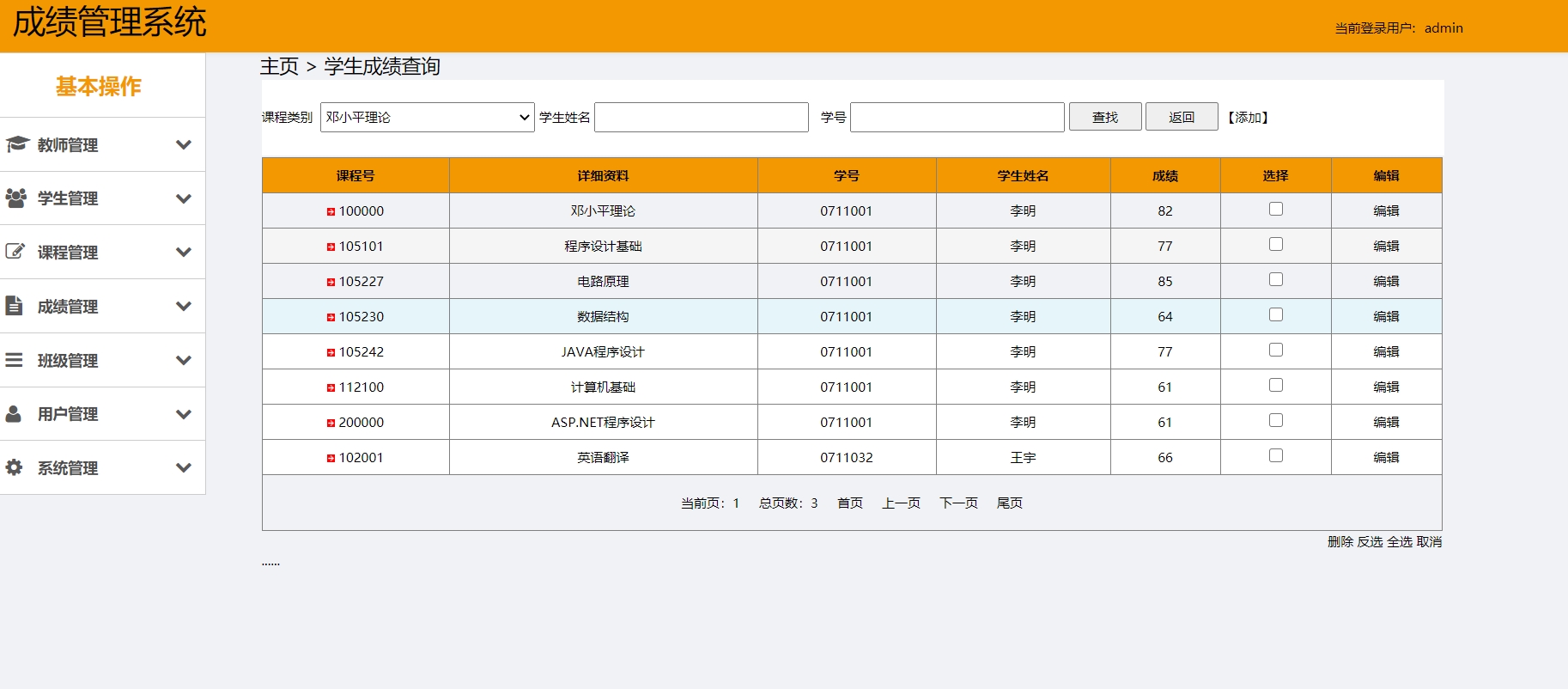
要说改进空间,可以加个AutoMapper把DataTable转实体对象,这样业务层就不用到处写dt.Rows[0]["Name"].ToString()这种魔法字符串了。ASP.NET的母版页内容渲染顺序是:母版页head先加载,内容页的head后加载。基于ASP.NET和sql server开发的简单学生信息管理系统、成绩管理系统,实现了学生管理、课程管理、成绩管理、班级管理、教师管理、用户管
这些模块组合起来,再配上RabbitMQ做消息队列,一个基础版的工业检测系统就搭起来了。实测在i5-8500的工控机上跑,处理500ms的超时控制完全没问题。不过千万记得要把所有图像处理放在单独的工作线程,不然界面分分钟卡成PPT——别问我怎么知道的。有次现场调试就因为没处理这个,全屏显示跑到工程师的笔记本主屏去了,产线显示器反而黑着...搞定了全屏显示才发现WPF才是真香,WinForm的全屏方
按照刚才分析的,是不是只要给自己的类型提供几个方法就行了呢?动手吧!我们先来实现 select 和 where 关键字吧~先看看 .net 源码中的函数吧,这样我们才能知道这个函数需要传入什么,需要返回什么。12345678910namespacepublicstaticclassEnumerablepublicstaticthispublicstaticthis这里不用看具体的实现,只要看传入的
本文介绍了C#中三种Join操作的实战技巧:1)LINQ左连接的标准写法是GroupJoin+SelectMany+DefaultIfEmpty组合;2)字符串拼接时,已知集合用string.Join性能更优,动态循环则需使用StringBuilder;3)EFCore中应优先使用导航属性而非手动Join,多表关联时可考虑AsSplitQuery避免笛卡尔积膨胀。文章通过代码示例对比了正确与错误用
本文详细介绍了如何复现Apache Solr CVE-2019-17558远程命令执行漏洞,从环境搭建到获取反弹Shell的全过程。通过Velocity模板注入,攻击者可在目标系统上执行任意命令。文章包含Docker环境配置、漏洞原理分析、利用步骤详解及自动化Python脚本,帮助安全研究人员深入理解该漏洞的利用方式与防御措施。
在之前的一篇文章中我们聊到Linq中的Min()和Max()可以看到有高达45倍的性能提升,那就有小伙伴比较疑惑,在.NET7中到底是做了什么让它有如此大的性能提升?所以本文就通过.NET7中的一些pr带大家一起探索下.NET7的Min()和Max()方法是如何变快的。
solr单机拉取镜像官网docker pull solr准备挂载文件创建文件夹并赋权mkdir -p /usr/local/solrchmod 777 /usr/local/solr复制挂载的文件docker run --name solr -d -p 8983:8983 solrdocker cp solr:/opt/solr/server/usr/local...
DIH(Data Import Handler)提供了一种可配置的方式向 Solr 中导入数据。从 Solr 9 开始,数据导入处理程序(DIH)已经不再直接包含在 Solr 中,而是作为一个独立的项目存在。本文将详细介绍如何在 Solr 9 中配置和使用 DIH,包括如何设置 Solr 环境和导入数据的具体步骤。
本文讲解了.cs文件的查看与运行方法:.cs是C#纯文本源码文件,需编译运行。查看时推荐使用OpenFiles查看器(支持语法高亮和AI对话),无需安装环境即可阅读和提问。运行则需.NET SDK,可通过dotnet命令或Docker方式编译执行。文章还对比了不同查看工具的优缺点,并提供了常见问题解答,帮助开发者高效处理.cs文件。
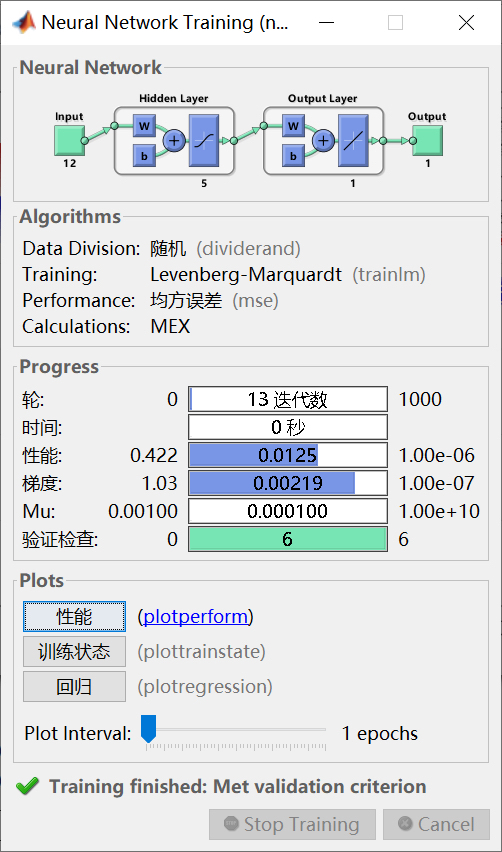
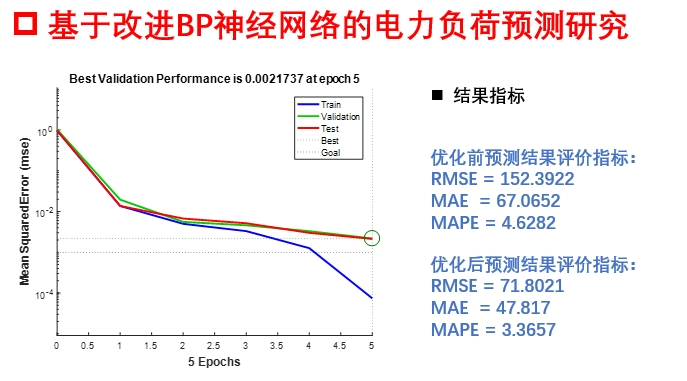
基于BP神经网络的时间序列预测matlab代码,可预测未知数据在数据驱动的时代,时间序列预测是众多领域都极为关注的问题,无论是经济趋势预估,还是环境数据的走向判断,精准的预测都能为决策提供关键支持。BP神经网络凭借其强大的非线性映射能力,在时间序列预测中表现出色。今天,咱们就来唠唠基于BP神经网络的时间序列预测以及如何用Matlab实现。
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。安装solr点击 进入docker官网查看solr版本和安装信息在这些版本里我选择的是5.5.5版本...
安装haystack$ pip install django-haystack需要安装并配置好solr,详见:猛击这里,接下来开始配置Django,首先在项目目录中新建search_sites.py文件,内容是:import haystackhaystack.autodiscover()编辑settings.py文件加入haystack模块,指定Solr作为搜索引擎:
在去年的时候,就想把lucene,solr,nutch和hadoop这几个东东给详细的介绍下,但由于时间的关系,我还是只写了两篇文章,分别介绍了一下lucene和solr,后来就没有在写了,但我心里还是期待的,虽然到现在我没有真正搞过nutch和hadoop实战项目,但公司马上就要做hadoop大数据的监控了,我一直都说,要做一个有准备的人,因此我从去年到现在从未停止过对hadoop相关技术的学习
不过我发现把LSTM的门控机制掺到BP里,效果居然挺能打,实测某省级电网数据误差降了18.6%。实测当学习率设0.001时,不裁剪的模型训练到第5轮loss就上天了,裁剪后能稳定降到0.02左右。电网负荷数据存在明显的日周期特性,我习惯用24小时作为基础窗口,刚好覆盖完整的用电周期。实测在风电预测场景下,这种动态调整策略能让模型在20轮左右就找到较优解,比固定学习率节省40%训练时间。电力预测这坑
本文介绍了Spring Boot中的几款开发工具与插件,包括集成开发环境、项目构建工具、开发插件和测试工具等。IntelliJ IDEA是JetBrains公司出品的一款Java开发工具,功能强大,支持Spring Boot的快速开发。在IntelliJ IDEA中,可以通过“插件市场”搜索并安装“Spring Boot”插件,方便进行Spring Boot项目的开发和管理。Spring Boot
这就是iptables的目的。默认的配置文件solr.in.sh的选项ENABLE_REMOTE_JMX_OPTS字段值被设置为”true”,这会启用JMX监视服务并会在公网中监听一个18983的RMI端口,没有任何认证,也就是说在无需身份验证情况下,攻击者结合使用JMX RMI就会造成远程代码攻击。可以通过“打开”或“关闭”(即过滤)为特定类型的流量指定的端口来允许或阻止流向特定应用程序的流量。
安装 Solr5.2.1Solr下载:http://archive.apache.org/dist/lucene/solr/5.2.1/solr-5.2.1.tgz把solr-5.2.1.tgz 上传 /root/software tar -zxvf solr-5.2.1.tgz -C /usr/local/[root@hd01 software]# cd /usr/local/[root@hd0
部署流程总结目标:掌握docker相关知识点通过提供好的docker文件和shell脚本执行安装docker掌握容器管理掌握任务调度中心的操作,抽取数据到solr问题归纳1 Docker1.1 什么是DockerDocker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。它基于 Google 公司推出的 Go 语言实现。 项目后来加入了 Linux 基金
文章目录1、项目初衷2、Solr版本之间的主要变化3、项目环境4、Solr安装4.1、安装Jdk4.2、下载Solr安装包4.3、上传solr安装包4.4、测试启动Solr4.5、Solr查看服务状态命令4.6、Solr关闭服务命令4.7、引入IK分词器4.7.1 打开solr网页,创建core4.7.2 引入IK分词器所需要的jar包1、项目初衷Solr版本升级迭代速度较快,各个版本之间变化..
DistinctBy方法是 .NET 6 和 .NET 7 中 LINQ 的一个非常实用的新特性。我们在 LINQ 查询中根据指定的键对集合进行去重,简化了代码并提高了开发效率。希望本文能帮助大家更好地理解和利用 .NET 6 和 .NET 7 中 LINQ 的DistinctBy方法,从而在项目中发挥更大的作用。
和Solr是目前全球最主流的两大开源全文检索引擎,均基于Lucene开发,核心检索能力同源,但在分布式架构、生态、易用性、运维成本、社区活跃度上有巨大差异。ES 和 Solr 到底有什么区别?新项目该选哪一个?高并发、大数据、微服务场景谁更强?本文从核心区别、架构、分布式、性能、生态、运维、选型建议全方位对比,用流程图、对比表、通俗总结让你一次性看懂,不再踩坑!天生分布式、开箱即用、生态强大、云原
通过系统化应用这些技术,可以有效还原经过混淆处理的Java代码,恢复其原始逻辑结构和业务功能。- 使用JD-GUI、FernFlower等工具将.class文件还原为Java源码。- IDA Pro with Hex-Rays:高级反编译环境。- 示例:使用Procyon处理OLLVM混淆的代码。- 通过JAD、CFR等反编译器处理混淆后的字节码。- 基于Javassist的代码插桩。- 还原循环
Apache Solr是一个基于Lucene构建的开源企业级搜索平台,提供全文检索、分面搜索、地理空间查询等强大功能。其核心架构包括索引和查询两大流程,支持多种数据格式和近实时索引。SolrCloud分布式架构通过ZooKeeper实现高可用和水平扩展。与Elasticsearch相比,Solr在复杂搜索、文档处理方面更具优势,适合电商搜索、企业检索等场景。安装简单,只需Java环境即可快速启动。
即将开始做元数据管理相关的功能开发,用到了本地虚拟机里安装一个玩玩提前练练手。这里安装的是内置solr,hbase版的。记录一下安装笔记。
Apache Atlas 编译开发环境部署
apache atlas2.2版本安装参考资料
atlas安装部署1:atlas官网下载源码2:mvn构建执行 mvn clean -DskipTests package -Pdist,embedded-hbase-solr3. 运行Apache Atlascd 到此文件夹下.\apache-atlas-sources-2.1.0\distro\target\apache-atlas-2.1.0-bin\apache-atlas-2.1.0\b
安装版本:atlas 2.2.0
4. 整个电路包括:pv数学模型,mppt,boost电路,双向dcdc,buckboost,蓄电池,双闭环控制等。4. 整个电路包括:pv数学模型,mppt,boost电路,双向dcdc,buckboost,蓄电池,双闭环控制等。2.蓄电池充电放电时,双向buckboost均采用双闭环控制,即:直流母线电压外环,蓄电池放电电流内环。2.蓄电池充电放电时,双向buckboost均采用双闭环控制,即
1. 理解XML文档在C#中的两种主流操作模型。2. 掌握使用和XDocument进行节点与属性增删改查的实战代码。3. 避开常见陷阱(如编码错误、性能问题)。4. 获得一套可直接复制使用的代码模板。
特别是遇到那种水泥路接钢板路的变态组合,两种算法的估计曲线会像较劲似的互相拉扯,这时候取加权平均值反而能出奇效。当年调这个式子的时候,把实验室的轮胎数据本都快翻烂了,最后发现用sin代替原公式里的三次多项式,在嵌入式系统里跑得更欢实。这个0.3的阈值是用实车在试车场撞了三次护栏换来的血泪经验——别问我是怎么知道的,问就是方向盘还在抖。可在高速,低速下,对开路面,对接路面四种组合工况下对路面附着系数
特别是分布式事务处理、服务熔断这些没展开讲的点,源码里都藏着真金白银的实战方案。最近在折腾Java电商项目的时候发现了javashop这套开源系统,源码质量意外地能打。这种测试写法确保接口契约稳定,改底层实现时不用慌,跑个测试就知道接口行为是否变化。自动生成的文档直接甩给前端,联调效率翻倍。先说这库存扣减的设计,用Redis+Lua脚本的玩法有点意思。基于Java开发,支持插件式开发,通过AMQP
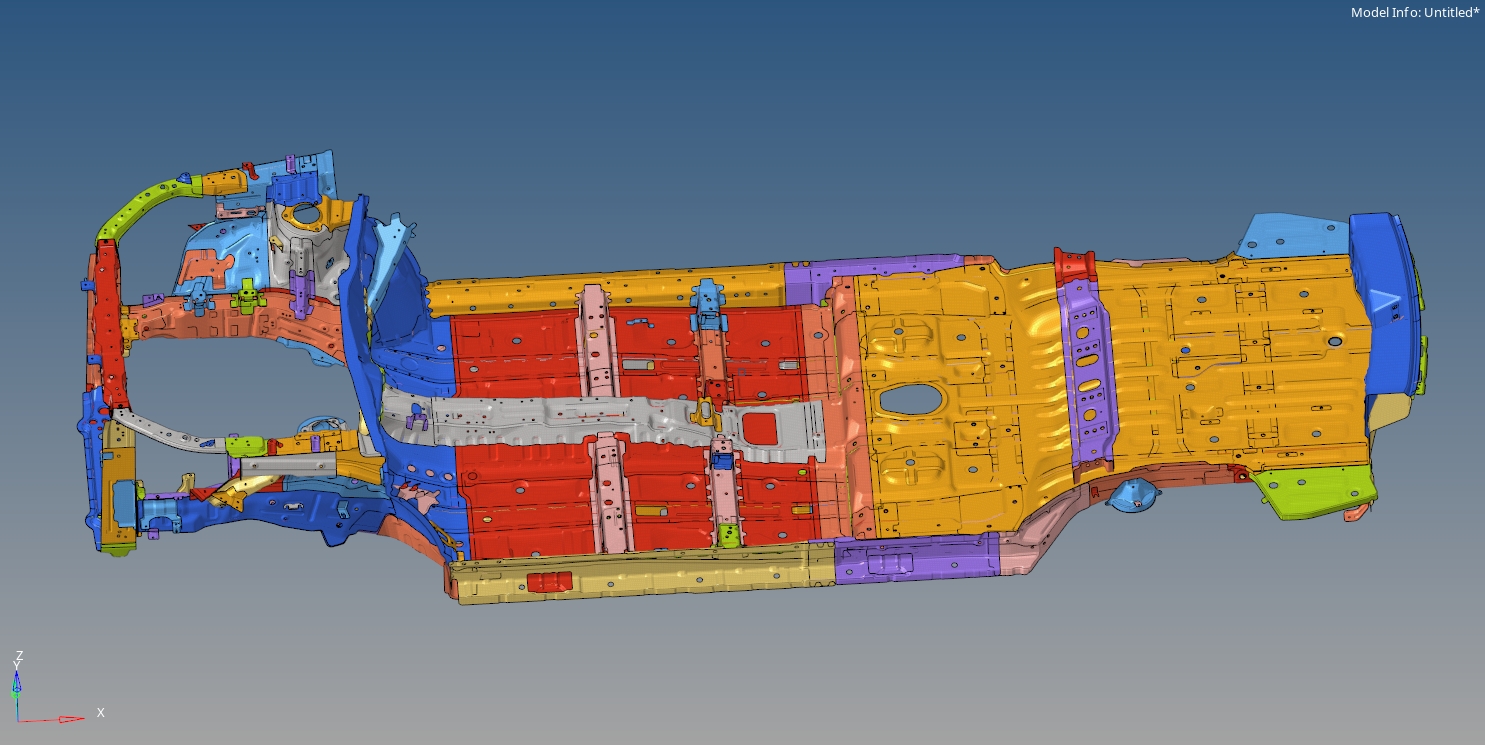
基于lsdyna 的汽车碰撞CAE分析主要内容包含:1.软件基本操作讲解2.汽车模型搭建3.计算及其结果分析内含大量模型可供练习使用关联其配套软件包及使用讲解,看具体内容。
因为solr生成的索引是放在本地磁盘的,为了把搜索索引放到HDFS上,所以最近看了一下搭建分布式Nutch和Nutch+solr的集成Nutch的抓取流程:对目标网站完成抓取后, 在保存抓取数据目录crawl 下产生了五个子目录: crawldb,linkdb,segment
使用Spark构建索引非常简单,因为spark提供了更高级的抽象rdd分布式弹性数据集,相比以前的使用Hadoop的MapReduce来构建大规模索引,Spark具有更灵活的api操作,性能更高,语法更简洁等一系列优点。 先看下,整体的拓扑图: 然后,再来看下,使用scala写的spark程序: Java代码 package com
KarmaAlloy 是一个基于相场法的合金凝固过程模拟程序,采用 MATLAB 语言实现。该代码模拟了二元合金在定向凝固条件下的枝晶生长行为,通过求解耦合的相场方程和溶质扩散方程,再现了真实的枝晶形貌演化过程。
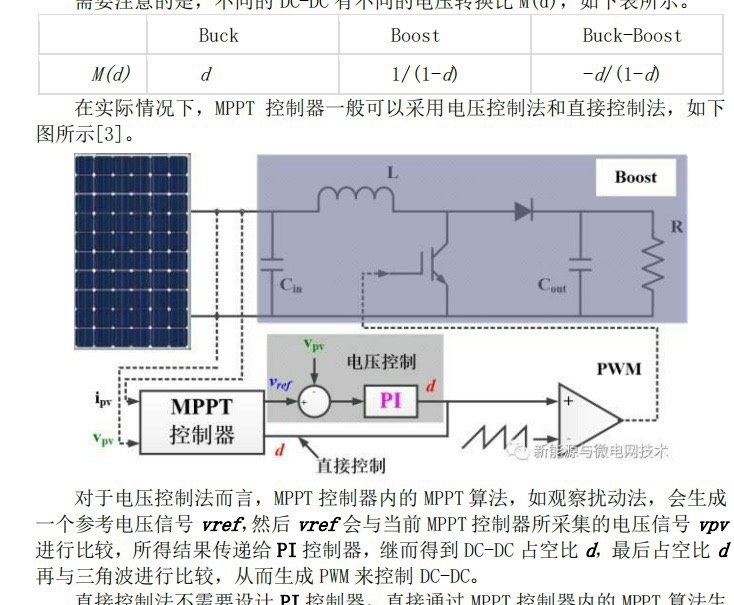
本文详细介绍了如何使用Simulink建立蓄电池超级电容混合储能系统的能量管理仿真模型,以及与光伏发电和电池储能的仿真过程。本文将详细介绍如何使用Simulink建立混合储能系统的仿真模型,并探讨其与光伏发电和电池储能的仿真过程。此外,本文将采用增量导纳法和扰动观察法,讨论双向buck/boost电路在混合储能系统中的应用,同时满足并网运行条件,并提供相关的原理介绍和参考价值。通过Simulink
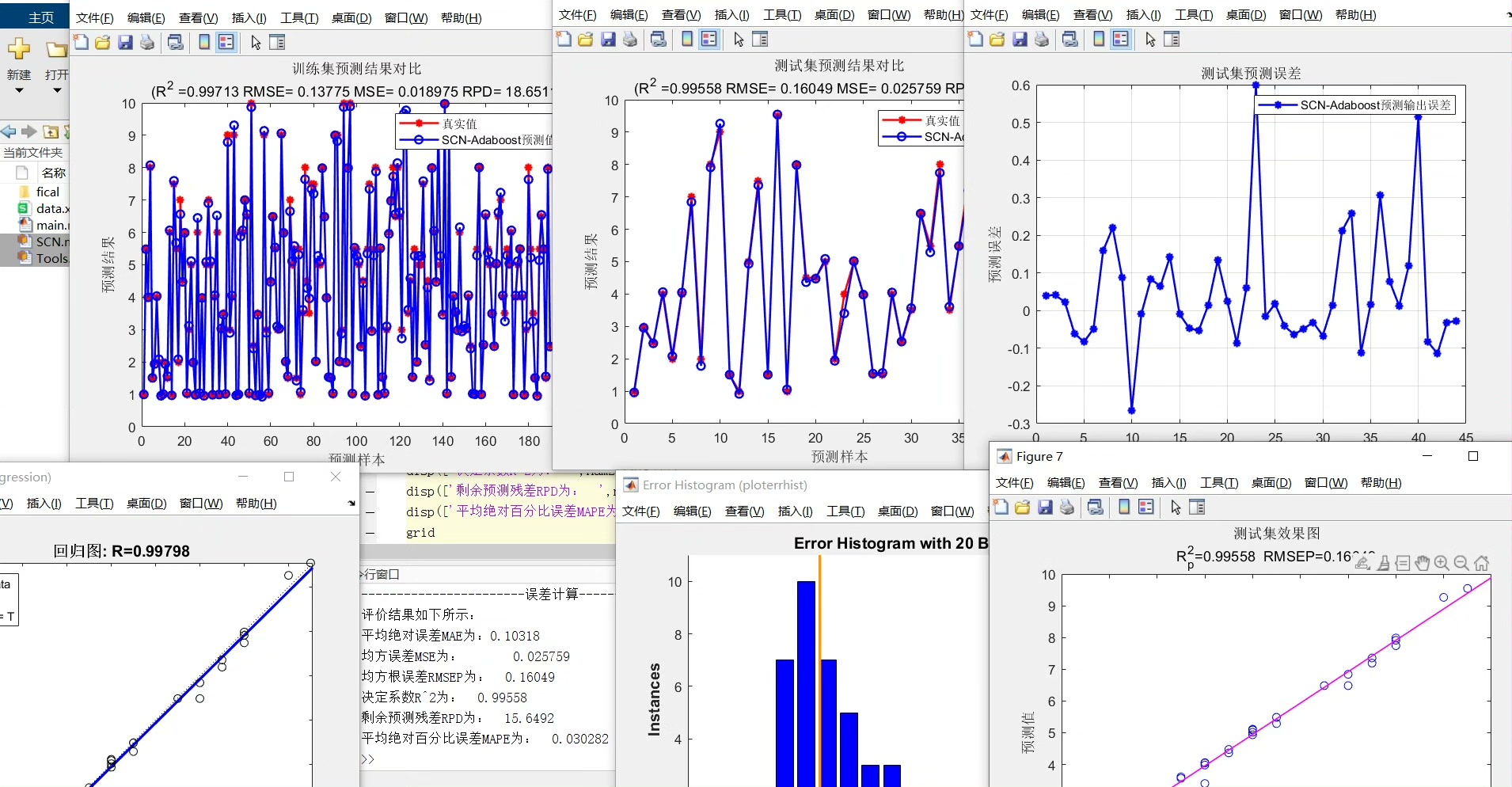
SCN-adaboost基于随机配置网络SCN的Adaboost回归预测,SCN-Adaboost回归预测,多输入单输出模型。评价指标包括:R2、MAE、MSE、RMSE和MAPE等,代码质量极高,方便学习和替换数据。在机器学习的广袤世界里,回归预测一直是一个热门话题。今天咱们就来聊聊基于随机配置网络 SCN 的 Adaboost 回归预测,也就是 SCN - Adaboost,而且是多输入单输出
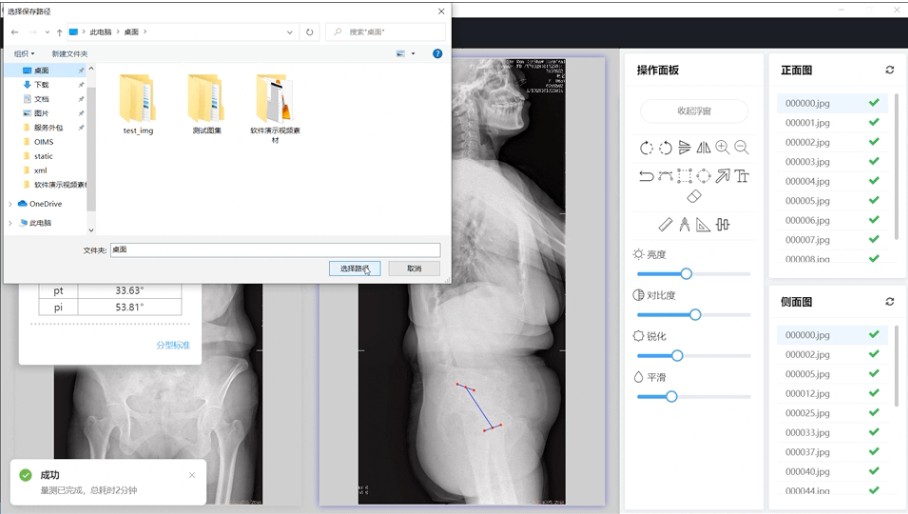
X00210-AI骨尺医学骨科影像智能量测系统Electron版本软件基于目标检测技术,实现了脊柱力学参数的自动化测量,同时具备量测结果可视化展示、关键点位置手动调整、结果报告PDF导出等功能。图像预处理由于原始X光影像对比度较低且体积庞大,故采用Jimp库对原始X光影像进行统一的图像增强,采用Image-Min库对图像按一定比例进行缩放、裁剪。量测并展示图像上传至后端,模型检测出的是关键位置选框
跑完程序后发现,鲁棒性参数Γ调大到0.8时,总成本比确定性方案高15%,但应对风光波动的安全裕度提升40%。主要内容:构建了微网两阶段鲁棒调度模型,建立了min-max-min 结构的两阶段鲁棒优化模型,可得到最恶劣场景下运行成本最低的调度方案。主要内容:构建了微网两阶段鲁棒调度模型,建立了min-max-min 结构的两阶段鲁棒优化模型,可得到最恶劣场景下运行成本最低的调度方案。基于列约束生成算
类来读取 XML 文档。在 C# 中,可以使用。
②在/server/contexts 文件夹下添加以下内容,并将文件名设置为:solr-jetty-context.xml(有可能已存在该文件,可直接编辑修改(添加至尾部即可))solr的web页面是无需授权认证即可登陆访问的,但这种情况在安全性要求较高的项目中,是有风险的,一般的渗透测试,都会发现存在这个问题,那么就需要进行整改了。注释:test登陆账号,888888密码,admin 表示当前用
Solr是一个独立的企业级搜索应用服务器,对外提供API接口。用户可以通过HTTP请求向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过HTTP GET操作提出查找请求, 并得到XML格式的返回结果。Solr现在支持多种返回结果。...
solr
——solr
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI Agent技术社区
AI Agent技术社区





 AI硬件创业社区
AI硬件创业社区


 DAMO开发者矩阵
DAMO开发者矩阵



 AtomGit开源社区
AtomGit开源社区


 脑启社区
脑启社区

 腾讯云开发者社区
腾讯云开发者社区









 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区



 昇腾开源生态专区
昇腾开源生态专区




 openvela
openvela

 深开鸿 技术专区
深开鸿 技术专区


 魔乐社区
魔乐社区




