- @Java_ZZZZZ
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
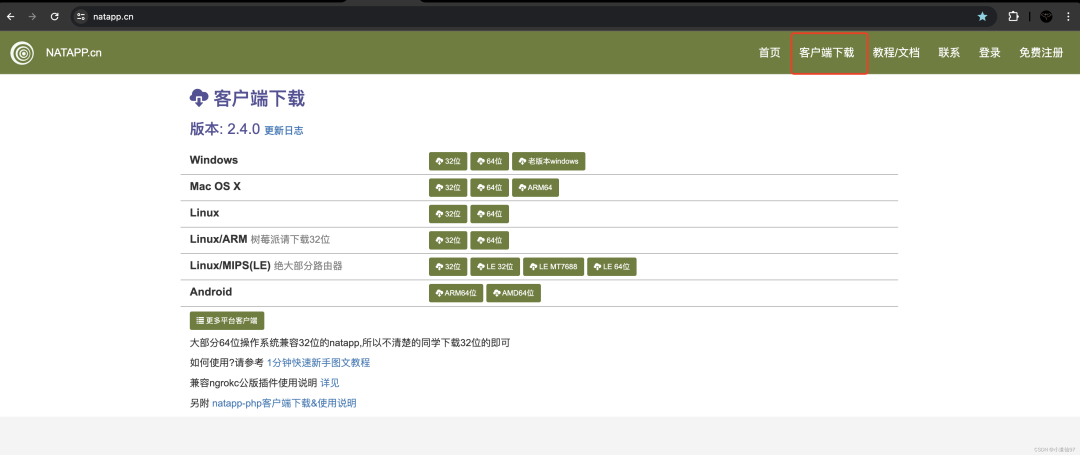
1、登录注册账号、下载软件2、使用2-1、购买隧道、查看token2-2、端口穿透1、登录注册账号、下载软件2、使用2-1、获取并设置 token2-2、使用3、隧道1、注册测试公众号2、回调代码3、回调配置在一些特殊的场景下,需要把我们的内网暴露出去,比如写了一个接口或网站想让别人看到,或者进行第三方开发调试的时候需要一个外网可用的回调地址。来对比一下ngrok和natapp免费功能的优劣| 限
UltraRAG 2.0是基于MCP架构的RAG框架,通过YAML声明式配置实现复杂逻辑,仅需传统框架5%代码量。它提供组件化封装、灵活扩展和轻量流程编排,支持多阶段推理系统,在复杂多跳问题上性能提升约12%。该框架显著降低开发门槛,让研究者专注于算法创新,适用于智能客服、教育辅导等多种场景。
之前第一版的爬虫书《Python3网络爬虫开发实战》在 2018 年出版,上市三年来,一直处于市面上所有爬虫书的销冠位置,豆瓣评分 9.0 分,销量 10w 册。如今,这本书现在又进一步做了升级,第二版将案例进行了全面升级,自建了案例平台防止代码过期,同时增加了非常多的新技术、新知识的介绍,比如异步爬虫、JavaScript 逆向、安卓逆向、Kubernetes、智能解析等等。同时每一个知识点都有

当我们谈论人工智能(AI),机器学习(Machine Learning),深度学习(Deep Learning),以及大模型(Large Models)时,实际上是在讨论人类如何让计算机学会像我们一样思考、学习和做出决策的技术。但是很多人都分不清他们之间的区别。

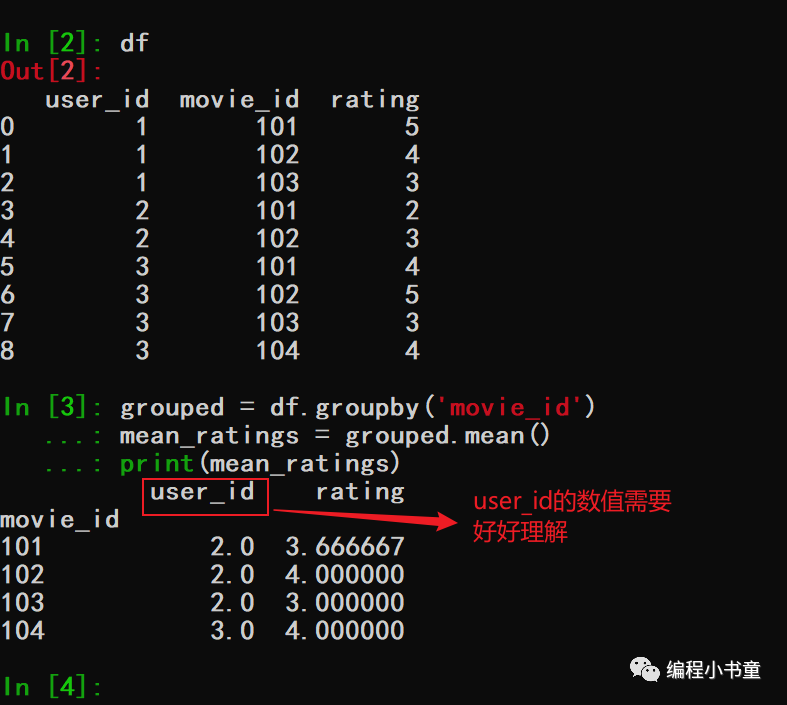
在数据分析和数据科学领域,数据聚合和分组是非常常见的操作。它提供了大量的功能,用于读取,清洗和处理各种类型的数据。Pandas是一个流行的Python库,提供了丰富的数据分析和处理功能。本文将介绍如何使用Pandas进行数据分组和聚合,包括分组操作和聚合函数的使用,以及使用transform和apply方法进行数据变换。
大数据是近几年各大企业非常关注的热点。大数据所延伸出来的相关岗位大数据开发工程师、大数据挖掘工程师、大数据分析师等等也成为受人追捧的高薪岗位。对于大数据开发工程师而言,拥有各种高效的开发工具。而对于大数据分析师,常用的工具有哪些?

matplotlib采用面向对象的技术来实现,因此组成图表的各个元素都是对象,在编写较大的应用程序时通过面向对象的方式使用matplotlib将更加有效。但是使用这种面向对象的调用接口进行绘图比较烦琐,因此matplotlib还提供了快速绘图的pyplot模块。本节首先介绍该模块的使用方法。

在人工智能领域,大语言模型(LLM)的应用日益广泛,选择合适的推理(部署)框架对实现高效、稳定的模型运行至关重要。Ollama和vLLM作为当下流行的LLM部署工具,各具独特优势与适用场景。本文将深入剖析二者的优缺点,并给出选型建议,同时附上它们的具体使用案例,以便读者更直观地了解其应用情况。

在人工智能领域,大语言模型(LLM)的应用日益广泛,选择合适的推理(部署)框架对实现高效、稳定的模型运行至关重要。Ollama和vLLM作为当下流行的LLM部署工具,各具独特优势与适用场景。本文将深入剖析二者的优缺点,并给出选型建议,同时附上它们的具体使用案例,以便读者更直观地了解其应用情况。
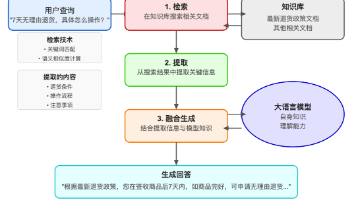
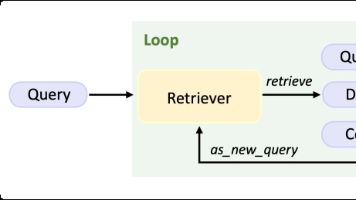
CSDN独家福利最近,人工智能大模型火得一塌糊涂,各种新名词也层出不穷:RAG、Agent、微调、提示词工程……是不是听着就头大?别担心,今天咱们就用大白话,把这些概念一次性讲清楚,让你彻底搞懂它们是什么、有什么用,以及它们之间的区别和联系。