登录社区云,与社区用户共同成长
邀请您加入社区
摘要 DeepSeek-VL 是一个开源视觉-语言模型,针对真实世界应用设计,在数据构建、模型架构和训练策略三方面进行创新: 数据构建:创建多样化数据集,覆盖网页截图、PDF、图表等真实场景,并通过用例分类体系构建指令微调数据,显著提升用户体验。 模型架构:采用混合视觉编码器,在固定计算预算内高效处理高分辨率图像(1024×1024),平衡语义理解和细节捕捉。 训练策略:通过联合语言-多模态预训练
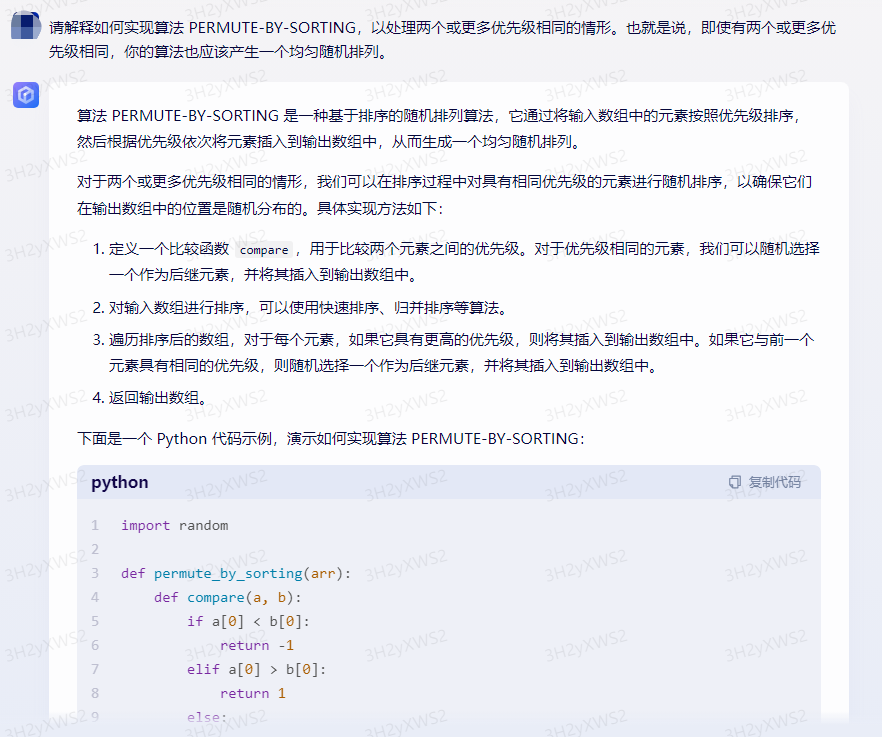
算法 PERMUTE-BY-SORTING 是一种基于排序的随机排列算法,它通过将输入数组中的元素按照优先级排序,然后根据优先级依次将元素插入到输出数组中,从而生成一个均匀随机排列。对于两个或更多优先级相同的情形,我们可以在排序过程中对具有相同优先级的元素进行随机排序,以确保它们在输出数组中的位置是随机分布的。具体实现方法如下:1.定义一个比较函数 compare,用于比较两个元素之间的优先级。对
输入cmd+k,在输入框里面键入想要实现的功能。除了桶排序,其他排序实现真实有效。1、cursor地址。
计数排序是一种非比较的整数排序算法,通过统计元素出现次数实现排序。其核心步骤包括:确定数据范围、统计频率、累加计数、反向填充。该算法时间复杂度为O(n+k)(k为整数范围),速度快于比较排序,但需要额外空间且仅适用于确定范围的整数。示例展示了Java实现过程,通过统计元素频率并重新填充数组完成排序。计数排序具有稳定性,但数据范围过大时效率会下降。
本文详细介绍了SpringSecurity与JWT在分布式系统中的认证授权实现方案。主要内容包括:1) 阐述认证授权核心概念及JWT无状态认证优势;2) 提供完整代码示例,涵盖基础环境搭建、JWT工具类封装;3) 详解自定义认证授权逻辑实现,包括用户详情服务、JWT过滤器和安全配置;4) 演示登录接口和权限控制实战;5) 总结常见问题解决方案。该方案采用JWT实现无状态认证,结合SpringSec
冒泡排序(Bubble Sort)是一种简单的排序算法,它的基本思想是通过不断交换相邻两个元素的位置,使得较大的元素逐渐往后移动,直到最后一个元素为止。冒泡排序的时间复杂度为 O(n2)O(n^2)O(n2),空间复杂度为 O(1)O(1)O(1),是一种稳定的排序算法。
本文介绍了Linux系统的基础指令和操作原理。主要内容包括:1)bc指令的浮点运算功能;2)计算机体系结构、Linux版本和发行版的查看方法;3)常用热键如Ctrl+C、上下键、Tab等提高操作效率;4)Shell与内核交互的原理,通过媒婆比喻形象说明Shell作为命令解释器的作用。文章旨在帮助读者深入理解Linux底层结构,掌握常用指令原理,提升操作效率。
【代码】插入/希尔/选择/堆/冒泡/快速/归并/计数排序等。
基于相邻元素的比较与交换,是一种交换排序。每一轮都会把当前未排序区间的最大值 “冒泡” 到区间尾部。每一轮在未排序区间中找到最小值(或最大值)将其与未排序区间的第一个元素交换位置重复上述步骤,直到整个数组有序初始化:默认数组第一个元素为已排序部分,其余为未排序部分。遍历待插入元素:从第二个元素(i=1)开始,逐个处理未排序部分的元素。查找插入位置:将当前元素(key)与已排序部分从后往前比较,大于
本文系统探讨冒泡排序、快速排序与归并排序的可视化实现策略与对比分析方法。从可视化架构设计出发,深入剖析三种算法在视觉语言、操作映射与性能呈现上的本质差异,并建立包含实时计数、输入切换、智能推荐的多维度对比框架。为算法教学与工程实践提供从“看见过程”到“理解本质”的完整认知路径。
> 📌 本文系统梳理二叉树属性在lecode上的一些热门题目附完整 Java 代码 + 关键逻辑解析+lecode练习地址。适合 LeetCode 刷题 &> 面试复习!
本文精选了Java开发和面试中最实用的20+种算法,涵盖排序、查找、双指针、链表、树和动态规划等核心算法。重点讲解了快速排序、归并排序、二分查找、滑动窗口、链表反转和01背包等高频考点,提供完整的Java代码实现(JDK8+风格),并分析时间复杂度、优化技巧和适用场景。排序算法部分对比了快速排序、归并排序和堆排序的性能特点;查找算法重点讲解二分查找模板;双指针部分包含滑动窗口经典实现;链表和树部分
Java中的Arrays工具类提供了数组操作的便捷方法,包括比较(equals/deepEquals)、打印(toString/deepToString)、排序(sort/parallelSort)、查找(binarySearch)、填充(fill)、复制(copyOf)等功能。特别要注意:数组比较需用Arrays.equals()而非equals()方法;binarySearch要求数组已排序;
表格排序算法时间复杂度空间复杂度稳定性适用场景冒泡O(n²)O(1)稳定小数据量、几乎有序的数据选择O(n²)O(1)不稳定小数据量、交换成本高的场景插入O(n²)O(1)稳定小数据量、几乎有序的数据快速O(nlogn)O(logn)不稳定通用场景、内存排序首选归并O(nlogn)O(n)稳定需稳定排序、外排序(磁盘)计数O(n+k)O(k)稳定数值范围小的整数排序桶O(n+k)O(n+k)稳定数
本文介绍了Jsoncpp库在C++中的使用,重点讲解了JSON数据的序列化和反序列化操作。Jsoncpp是一个开源库,提供简单易用的API、高性能处理和全面的JSON标准支持。序列化方面,介绍了toStyledString、StreamWriter和FastWriter三种方法;反序列化则通过Json::Reader实现。文章还详细列举了Json::Value类的常用操作,包括构造函数、元素访问、
本文介绍了HTTP请求和响应的基本实现框架。通过C++代码展示了HTTP请求类(HttpRequest)和响应类(HttpResponse)的结构设计,包括请求方法解析、状态码处理、报头管理等功能。重点讲解了HTTP协议的核心特性:无状态、无连接本质,以及通过Cookie和Session机制实现状态保持。同时详细分析了GET/POST等HTTP方法的区别、重定向状态码(301/302等)的应用场景
排序,简单来说就是将一组数据按一种特定的比较方式来递增或增减地将数据重新排列成有序的序列。排序的稳定性:若在一组数据中存在两个或两个以上的相同的数据,在经过一定的排序算法排序后,这些相同的数据的前后顺序不变,那么我们就称这个排序算法是一个稳定的排序,反之,则为不稳定的排序。
前提条件:数组中的数据必须是有序的核心逻辑:每次排除一半的查找范围。
把[first, last)区间中的元素按照cmp中的规则按照非严格的升序排序,不稳定排序(相等的元素在排序后相对顺序可能会发生变化)注意,这里的comp比较器的返回值是bool类型,相等时返回false,当返回值为true时,认为第一个元素比第二个元素小,不换顺序。first, last是迭代器类型(指针类型),指向要排序的数组的第一个元素地址和最后一个元素的下一个地址。priority_que
需要交换 left+1 和 i , 此时如果 i==++left , 是自己根自己交换;注意 : 由于 left+1 位置为已经排好序了的元素 , 所以能让 i++: 需要交换 right-1 和 i , 此时如果 i == --right,也是自己自己跟自己交换 , 交换完成退出循环(因为此时 i == right)[left+1,i-1] 为 1;[i,right-1] 为待排序元素;[rig
,然后将Java对象里的数据填入模版。模版是文本文件,可以是Word,HTML网页,Java代码,XML配置文件,SQL脚本等。建议——基础知识不扎实,多刷题,对于一个产品解决问题的思维,对于简历每一个项目的功能的深挖(从需求分析,为什么要这么做——到可行性分析,要怎么做——到代码实现,用了什么技术做——到功能展现,实现了什么功能,有什么提升)因为要在不影响原有功能的前提下,将一张包含基本信息,微
本文介绍了几个常见算法的实现方法:1) 辗转相除法求最大公约数;2) 斐波那契数列的递归和循环实现;3) 冒泡排序算法。重点详细讲解了五子棋游戏的实现,包括判断胜负的算法、落子逻辑、游戏界面显示和菜单系统设计。其中五子棋胜负判断通过四个方向搜索连续同色棋子,游戏流程包含初始化、轮流落子、胜负判定等完整环节。这些算法示例展示了从数学原理到代码实现的过程,以及如何将算法应用于实际游戏开发中。
冒泡排序是一种简单的排序算法,它的工作原理是重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就交换它们。
2.不可以使用两个for,因为,如果temp是最小值,那我们就实现在第二个for里替换(也就是执行不到else语句,只进行一直往后移位),导致第一个数不得排序。1.最后一定要拷贝回到nums,虽然输出是newNums,但是递归需要用到nums,所以必须拷贝。第二行包含 N 个空格隔开的正整数 ai,为你需要进行排序的数。注意:1.while的判断条件不可颠倒,否则容易出现短路。将给定的 N 个数
/内循环用来确定每一轮要比较的次数,每比较一次最后一个为最大的值会被被唯一的确定,所以需要在nums.length-1的基础上再减去i。//Arrays.toString的使用方式:把数组的内容转成字符串的形式打印出来。for(int x:nums){ //增强型循环,打印排序后的数组。if(nums[j]>nums[j+1]){//判断条件。//定义一个增强型循环,把nums值赋值给x。//in
无参方法:括号为空,无需传入任何数据单参方法:仅传入自定义内容,控制输出文字双参方法:同时传入内容 + 行数,双重自定义控制{主程序-交互版}// 键盘输入必须写这个// 创建输入工具// 创建对象// 1. 调用无参方法System.out.println("=== 1. 调用无参方法 ===");fa.show();// 2. 让你自己输入内容System.out.println("=== 2
同学们经过刚才的学习已经认识了什么是异常了,但是Java无法为这个世界上的全部问题都提供异常类,如果企业自己的某种问题,想通过异常来表示,那就需要自己来定义异常类了。自定义异常的种类我们通过一个实际场景,来给大家演示自定义异常。需求:写一个saveAge(int age)方法,在方法中对参数age进行判断,如果age<0或者>=150就认为年龄不合法,如果年龄不合法,就给调用者抛出一个年龄非法异常
本文系统介绍了数组的概念和使用方法。数组是存储相同类型数据的连续内存容器,具有高效访问特性。主要内容包括:数组的声明创建、下标规则、元素存取、遍历方式及默认值;内存存储原理和扩容方法(手动复制、System.arraycopy、Arrays.copyOf);可变长参数的使用规则;排序算法(冒泡、选择)及工具类排序;二维数组的定义和使用,包括不规则二维数组。文章涵盖了数组的基础操作和进阶应用,适合编
本文深入探讨了Java中Arrays.sort方法的高级应用,重点介绍了如何利用Comparator接口实现多维度与自定义排序。通过实际代码示例,详细解析了二维数组排序、对象多字段排序以及中文处理等常见场景,并提供了性能优化与最佳实践建议,帮助开发者高效处理复杂排序需求。
7月初,在AI这波掉队后,Meta出来掀桌子,先是宣布对外出租闲置AI算力,市场的第一反应是“算力买多了”,Meta一直是算力的大买家,现在要将GPU拿出来出租,是不是说算力过剩了?到7月17日收盘,216港元,市值754亿港元,缩水超80%。逻辑链条大概是这样的:Kimi K3太强了,2.8万亿参数,全球首个开源3万亿级别模型,在Arena.ai编程排名上冲到了全球第,投资者担心模型这么厉害会导
Cursor 积累了三年的用户行为数据——什么样的补全被接受、什么样的重构被采纳、什么样的 Agent 策略奏效——这些数据对训练下一代 Grok 编码模型来说是无价之宝。终止费的规模说明了双方对审查风险的预估:如果审查失败,SpaceX 要付 40 亿美元的反垄断专项终止费——这个数字异常大,暗示交易双方确实担心审查,但 600 亿的盘子值得赌一把。原来团队计划做的功能——更开放的多模型支持、更
本文探讨了一个塔罗牌运势应用的开发要点,重点分析了三张牌交互的实现细节。文章首先指出看似简单的三张牌布局实际涉及复杂状态管理,包括牌堆立体感、翻牌动画、独立状态和洗牌算法等。随后详细介绍了页面结构的三个阶段切换逻辑,以及如何利用三个@State数组管理牌面状态。在视觉实现上,通过Stack层叠和渐变效果营造牌堆立体感。最后解释了Fisher-Yates洗牌算法的实现原理,确保每天结果固定。整个设计
过去七年间,特斯拉每隔一段时间就会释放新产品的消息,比如开售Cybertruck皮卡和Semi重卡,揭开了Cybecab和Robovan的面纱,预告了新一代Roadster跑车,入门车型Model 2也一度若隐若现。但与同一商场内的 鸿蒙智行、小米、理想、 智己等品牌的新车相比,Model Y在外观、内饰、空间、配置、动力、电池等方面并不占优,甚至多数指标处于劣势。马斯克擅长造车,更擅长讲故事。如
int minRun = minRunLength(nRemaining)是一个纯粹对数值计算方法,目的是计算出将数组需要划分成多少个run,这时的run的长度使用minRun表示,并且需要让nRemaining/minRun最接近一个2的幂(实际上nRemaining/k严格小于2的幂)。这一步的解读参考后文5.1节,这里暂时跳过,只需要知道countRunAndMakeAscending方法的
本文全面解析C++中常见的排序算法,包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序。每种算法都详细介绍了其原理、C++实现代码以及性能分析(时间复杂度、空间复杂度、稳定性)。文章还介绍了C++标准库中的std::sort函数,并提供了各类排序算法的对比总结表格,帮助开发者根据实际场景选择合适的排序方法。所有代码示例完整可直接使用,是一篇实用的排序算法参考指南。
【代码】Python Day7 列表排序 及 例题分析。
Java:实现大顶堆和小顶堆排序算法(附带源码)
本文展示了Java中10种常见排序算法的完整实现,包括冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、计数排序、桶排序和基数排序。每种算法都提供了详细注释和时间复杂度分析,如冒泡排序O(n²)、归并排序O(n log n)等。代码还包含测试框架,可比较不同算法性能,并支持Java内置排序。实现中使用了优化技巧,如冒泡排序的提前终止检查、希尔排序的动态间隔计算等。文章通过清晰的代
此文章是本人对11大排序的学习和理解,方便自己以后回想记忆。好了正片开始!再接再厉,希望每天能敲敲代码,(目前熟练度也有所上升)写博客其实和我初中写的那种图文文章还不太一样,博客更注重事实和证明(偏理那种吧)学编程和写博客让我感悟到了自学要先学会模仿,嗯。
排序算法
——排序算法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区



















 HarmonyOS开发者社区
HarmonyOS开发者社区

 人工智能6S服务平台
人工智能6S服务平台

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 AI Agent技术社区
AI Agent技术社区