




- @weixin_74085818
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
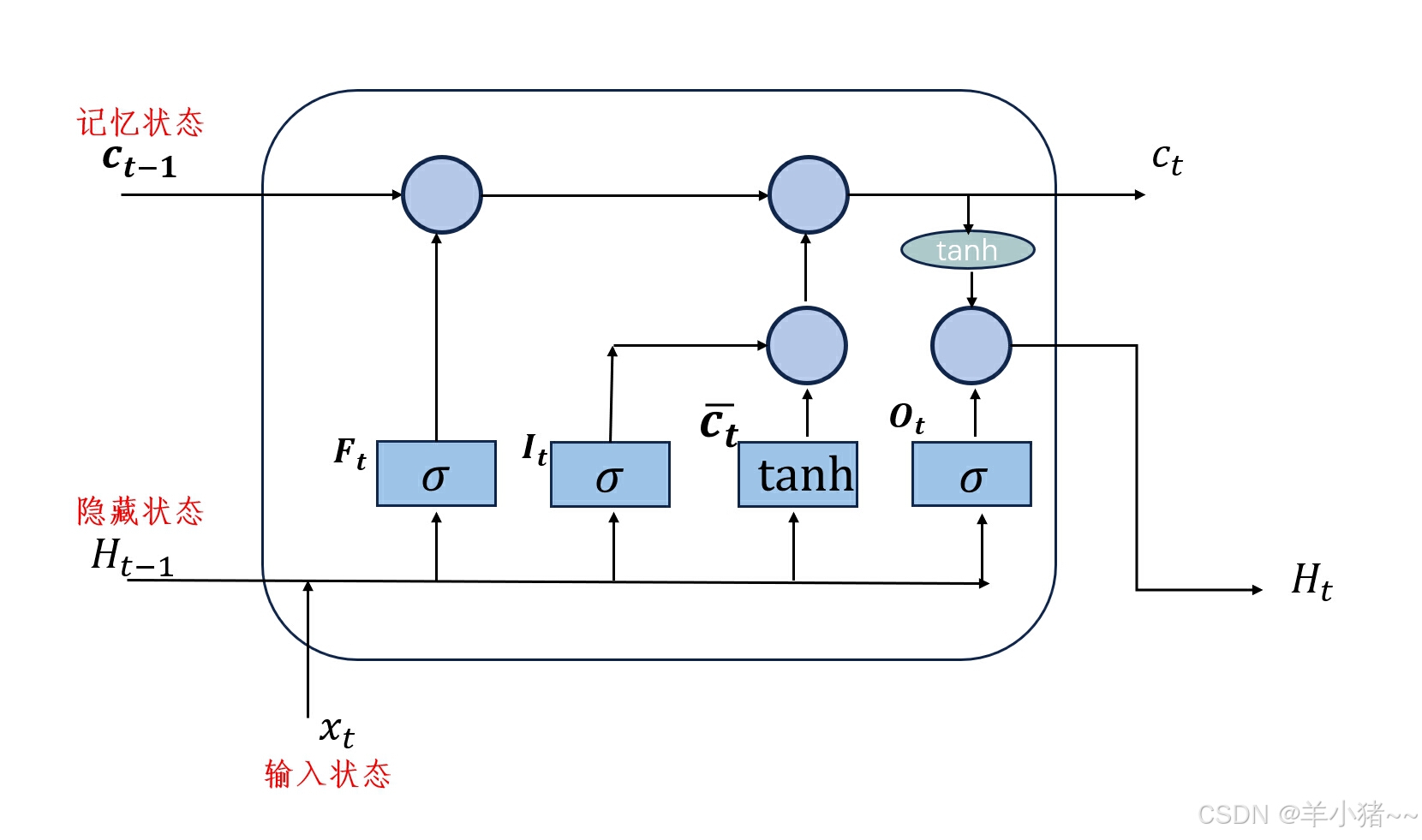
当然,结合案例实战,看代码是如何构建神经网络的才是最重要的,下面就是一个股价预测案例,核心是在于怎么构建LSTM网络结构,怎么进行前向传播。
这是一道“泰迪杯“杯的数据分析赛题,对于我现阶段,难度还是很大的,参考了不少资料做完的,这一次我再一次意思到了自己的实力🌵🌵🌵🌵🌵🌵;熟练使用Pandas、机器学习库是基础😢😢😢😢😢😢😢;我感觉数据分析具有很强的业务性,很适合学生去学习,从而了解业务;这一次代码量很大,观看起来应该都很麻烦,但是总体坐下来对数据分析逻辑也有了不小帮助;
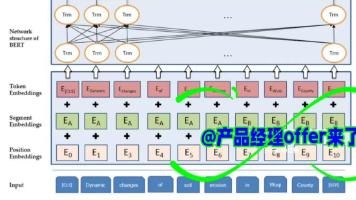
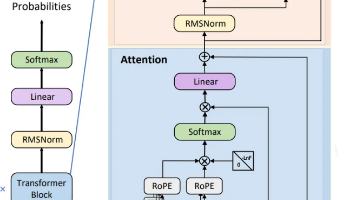
摘要: BERT是一种基于Transformer编码器的预训练语言模型,通过双向上下文捕捉文本信息。其架构包括输入层(Token/Position/Segment Embedding)、Transformer编码器(自注意力机制等)和任务相关输出层。BERT采用两种预训练任务:MLM(随机遮蔽词汇预测)和NSP(句子连续性判断)。与GPT不同,BERT是双向模型,适用于多种NLP任务。输入支持单句
LLama
本文介绍了RAG(检索增强生成)框架及其应用实践。RAG通过整合检索与生成,实现了知识更新无需重新预训练,并提升了模型回答的可解释性。文章详细解析了RAG的流程,包括文本分块、向量化、索引构建、检索、重排序和提示词工程等步骤。最后以Qwen大模型为例,展示了RAG的实战应用,包括PDF文本读取、分块处理、向量嵌入、相似度计算和语义搜索等关键环节,为读者提供了完整的RAG实现方案。
本文介绍了Ollama本地大模型部署工具的使用方法。主要内容包括:下载安装Ollama(版本0.16.3)、部署轻量级qwen3:0.6b模型、运行与退出操作。重点讲解了Ollama提供的API接口,包括聊天对话、文本向量化、模型管理等8个核心接口的调用方法和Python示例代码,特别详细说明了/chat和/embeddings接口的使用场景和请求格式。文章还提及了因硬件限制选择小模型的考虑,为本
环境:seaborn绘制热力图的时候,版本需要与matplotlib版本配对,matplotlib版本需要在3.8.0以下随机森林:可以决解多重共线性问题进一步熟悉了数据分析的过程不足:算法的扩展性、数据特征提取没有做。

yolov5源码中,网络结构的参数存放在.yaml文件中,如下:每个.yaml文件中都有一下几个部分:以为例子:文件描述了模型的参数、骨干网络(backbone)和头部网络(head),以及它们之间的连接方式。🎫 **提示:**不同的.yaml文件只是和不一样。anchors:backbone:head: [参数nc: 80:表示模型被训练来检测 80 类物体,这是 COCO 数据集的类别数量。

时间是每隔固定时间收集的,故有用特征为:温度、CO、Soot。rmse、r2都不错,但是拟合度还可以再提高。
