登录社区云,与社区用户共同成长
邀请您加入社区
本文提出了ZenithVM(zVM)这一类型化统一虚拟机的设计理念,旨在解决分布式计算时代的两大核心问题:操作系统与数据库之间的抽象错配,以及编程语言生态的割裂。文章通过历史回顾指出,传统操作系统为数据库提供的底层支持存在根本性缺陷,导致现代数据库系统不得不重复实现80%的操作系统功能。同时,各类编程语言虚拟机(如JVM、V8)的孤立发展造成了严重的生态碎片化。 zVM的核心创新在于构建了一个具备
【150字摘要】数据库先驱Michael Stonebraker提出的"数据库式操作系统(DBOS)"揭示了OS与DB的本质统一:传统操作系统的进程调度、文件系统、网络栈分别对应数据库的事务调度、存储引擎和分布式协议。DBOS项目用SQL优化器替代调度器,以分布式事务表重构文件系统,将网络通信转化为消息队列表,实现系统级事务化。这一理念与TypedUniVM(zVM)的类型化虚
本文探讨了基于zVM构建下一代分布式操作系统(zOS)的构想。文章指出传统操作系统在分布式环境中的三大痛点:内核与用户割裂、单机设计局限和进程模型低效。zOS将具备四大颠覆性特征:1)以zVM为微内核,消除系统调用开销;2)实现进程级热迁移;3)建立全局类型化内存空间;4)用图数据替代传统文件系统。这种架构将大幅简化技术栈,使分布式开发就像编写本地代码。虽然实现挑战巨大,但Fuchsia OS等前
【摘要】zVM虚拟机通过类型安全的软件隔离机制,实现了操作系统内核70%的核心功能,剩余30%可作为用户态服务运行,形成微内核架构。其颠覆性在于:1) 用轻量级TypedActor替代传统进程/线程,实现跨节点零拷贝通信;2) 驱动和文件系统作为可热插拔的沙箱字节码;3) 基于类型系统的能力安全模型;4) 将分布式集群抽象为单一虚拟计算机。相较于为单机设计的传统OS,zVM从底层构建了原生支持分布
今天,我们就来扒一扒内存分区的底裤,用最接地气的例子,让你彻底搞懂程序运行时的那块“地盘”是怎么划分的。—### 一、内存分区:程序员的“领土划分”想象一下,你的程序像一个小国家,内存就是它的领土。现代操作系统和编译器,通常把进程的虚拟内存划分为以下几个关键区段:| 分区名称 | 存放内容 | 特点 ||---------|---------|------||—### 二、栈:程序的“临时工”栈是
做电商运营、竞品分析、选品调研的时候,我们经常需要持续盯一批商品:价格波动、库存变化、规格变动、销量走势。手动打开网页复制粘贴,效率低还容易遗漏关键变化。最近折腾 OpenClaw 这套工具,发现可以快速把商品基础信息定时拉取到本地,做成轻量化监控脚本。不需要复杂爬虫框架,几行代码就可以完成定时采集、数据落盘、简单分析,适合个人小团队做竞品跟踪、选品复盘。注意:本文仅用于技术学习,使用时请遵守平台
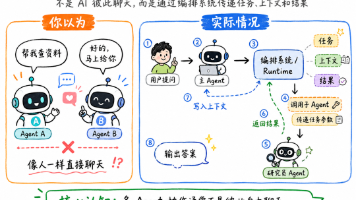
如果你用过 ChatGPT 或类似的 AI 工具,你的体验大概率是这样的:你问一个问题,AI 给你一个答案。看起来像是一个 AI 从头做到尾。
摘要: C++并非C的严格超集,二者虽有90%基础语法兼容(如内存模型、控制流),但存在关键差异:C99特性(如变长数组)在早期C++中不支持,而C++独有的类、模板等特性C无法使用。历史渊源上,C++从“带类的C”发展为独立多范式语言,底层仍与C共享系统级内核(手动内存管理、直接编译为机器码)。核心区别在于范式:C专注结构化编程,追求极致性能;C++融合面向对象、泛型等范式,适合复杂工程。生态上
PyTorch torch.cuda.is_available() 返回 False 主因是 CUDA 驱动、CUDA Toolkit 与 PyTorch 版本不兼容,需满足:nvidia-smi 显示的 CUDA Version ≥ PyTorch 所需版本 ≥ nvcc --version 输出版本(若装了 Toolkit),并检查 WSL2/Docker/用户组权限、GPU 架构匹配及资源占
梯度检查点是通过只保存部分中间激活值、反向时重算前向来节省显存的技术,能降低40%~60%显存但增加15%~30%训练时间,要求模块前向可重入且无副作用。梯度检查点是什么,为什么能省显存梯度检查点(torch.utils.checkpoint.checkpoint)不是“不存梯度”,而是“不存中间激活值”。PyTorch 官方推荐方式是用 checkpoint.checkpoint 包裹函数调用,
Thread对象的Join方法表示把Thread加入进来,暂停当前线程,并把它设置为WaitSleepJoin状态,直到加入的线程完成为止。//不能把入池的线程改为前台线程不能给入池的线程设置优先级或名称入池的线程只能用于时间较短的任务。当操作系统的线程调度器选择了要运行的线程,这个线程的状态才会从Unstarted修改为Running状态。IsBackground 表示是前台线程还是后台线程 f
具身智能的后端架构,本质是高维实时控制系统的云边协同。ROS2不会消失,但需要适配层。DDS在机器人内部不可替代,云端→机器人必须走gRPC/QUIC等现代协议桥接。盲目替换DDS是错误的,正确做法是边缘网关做协议适配。多模态异步融合是2026下半年的工程共识。同步融合的延迟代价太大,各模态独立流水线+决策帧同步的方案,在RT-2/Octo等模型的生产部署中已被验证有效。Sim2Real是长期工程
趋势一:开源vs闭源的能力差距从"不可用"缩小到"场景级可用"。通用对话场景差距近乎消失,复杂推理与多模态仍有2-5%差距。企业决策应从"差距多少"转向"我的场景在哪个维度"。趋势二:国产开源模型形成了差异化竞争格局。Qwen的长上下文与多语言、DeepSeek的推理效率与数学能力、Yi的小模型企业精调——三者的差异化定位让企业在不同场景有了明确的选型依据,而非简单的"选最大的模型"。趋势三:混合
多Agent系统在2026下半年正经历从实验到生产的质变。这个质变不是单一技术突破驱动的,而是协议标准化(A2A/MCP)、安全模型成型(身份/权限/审计三层体系)、调度架构成熟(集中式Orchestrator+推理经济管理)三股力量交汇的结果。判断一:企业内部多Agent闭环场景在2026Q3-Q4可进入生产。单组织内的Agent协作,信任边界清晰,调度可控,是最先落地的场景。优先选择集中式Or
PHP 不支持原生 GPU 计算,无 cuda_init() 等函数,官方未提供 GPU 加速扩展;必须异步化注意环境隔离:PHP 运行用户(如 www-data)需有权限访问 GPU 设备(/dev/nvidia0),但生产环境通常禁止 Web 进程直连硬件设备,安全策略会拦截ImageMagick / FFmpeg 的 GPU 加速配置要点这是 PHP 用户最可能接触到的“伪 GPU 加速”场
PHP调用大模型API做用户行为打标需预处理、结构化封装与异步调度,而非直传原始日志;在 PHP 中硬编码一个 $valid_tags 数组,按维度分类,例如:['consumption_level' => ['low', 'mid', 'high'], 'interest_category' => ['skincare', 'makeup', 'haircare']]调用 AI 后,用 json
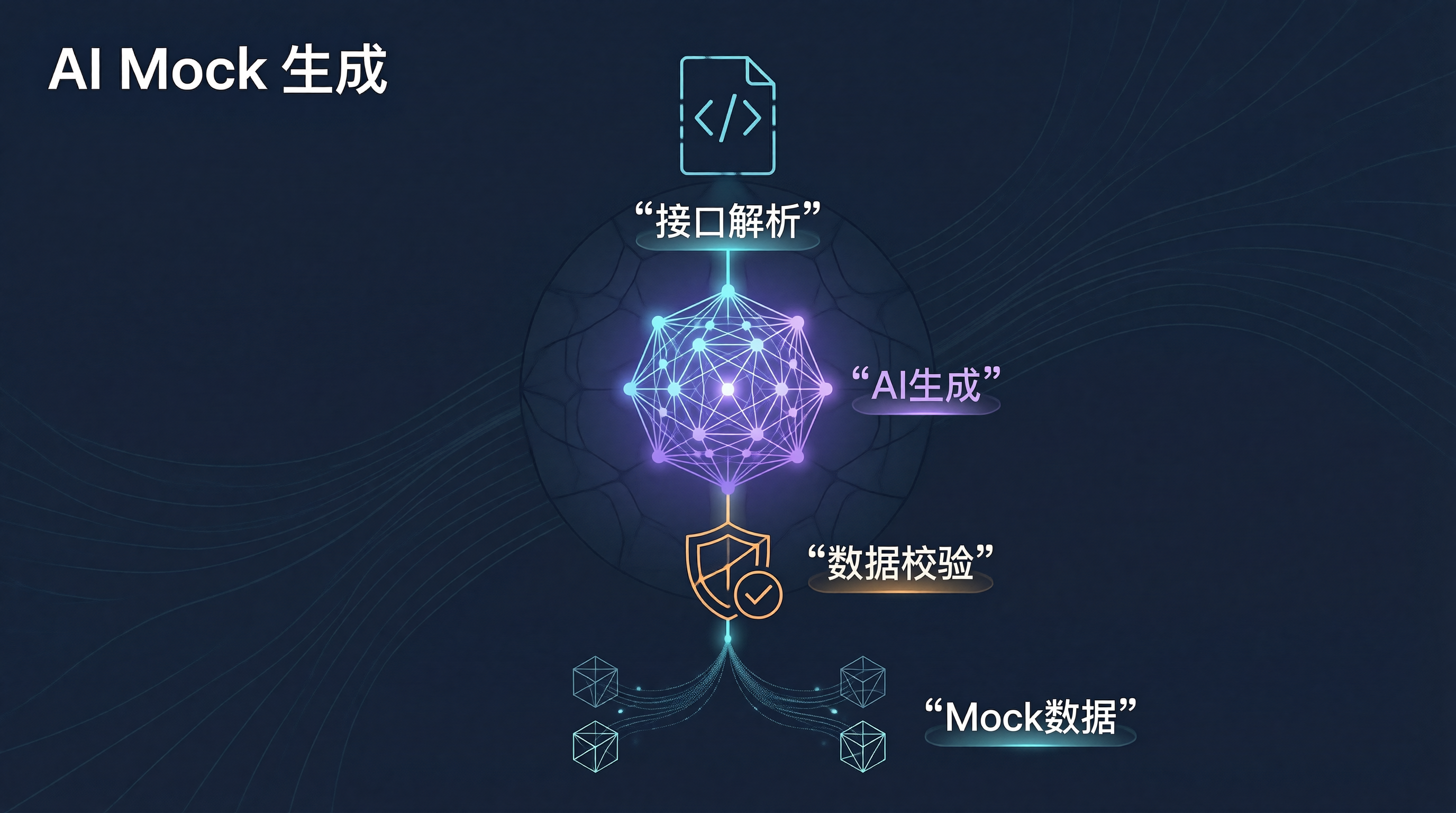
Schema解析将各类接口定义统一为中间表示(IR),Prompt工程将IR转换为大模型能够理解的结构化指令,AI生成与校验确保输出数据的类型正确性和边界覆盖率。本文的兜底生成策略保证了AI不可用时的流程连续性,Schema校验器则在数据质量层面把住了最后一道关。对于微服务团队,这套方案可以将Mock数据准备时间从小时级压缩到分钟级,显著提升接口联调和自动化测试的效率。
JVM(Java Virtual Machine,Java虚拟机)是Java技术体系的核心,也是实现Java语言“一次编写,到处运行”(Write Once, Run Anywhere)承诺的基石。根据Oracle官方定义,JVM是一个为执行Java字节码而设计的虚拟机规范。它提供了一个独立于底层硬件和操作系统的运行时环境,使得编译后的Java字节码(.class文件)可以在任何安装了相应JVM的
元注解是专门用于修饰其他注解的注解,是所有自定义注解的规则基石,直接决定注解的生命周期、作用范围、继承特性和使用规范。熟练掌握元注解,是正确使用、自定义注解的前提。public @interface RequiresPermission { // 权限唯一标识 String value();以下问题均来自生产环境高频BUG、大厂面试高频追问,是无数开发者踩坑总结的核心避坑点,务必熟记。注解的所有属
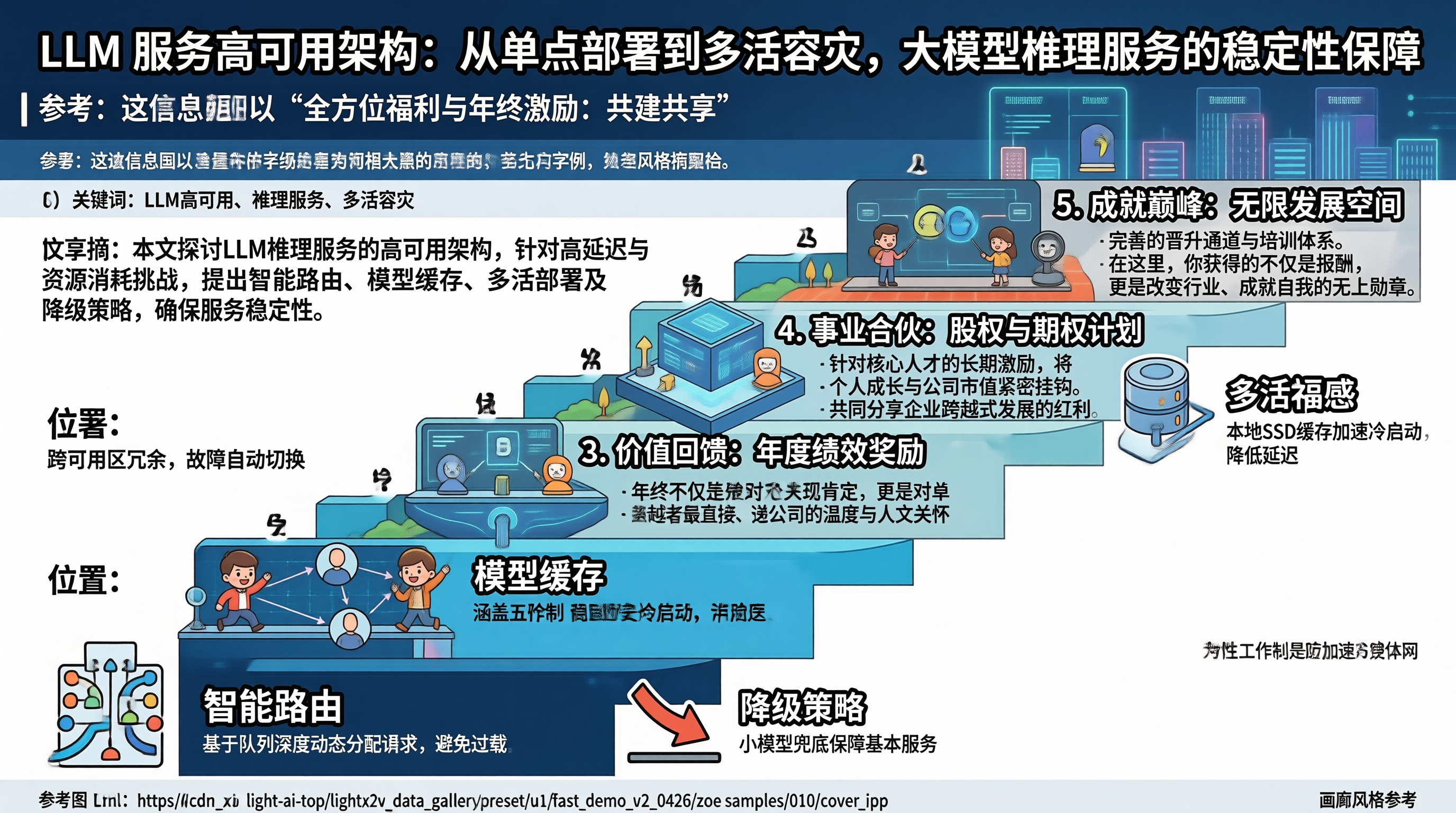
LLM 服务的高可用设计需要针对推理延迟高、资源消耗大的特点进行专门优化。核心策略包括:基于队列深度的智能路由避免过载,模型本地缓存加速冷启动,跨可用区多活部署防止单点故障,小模型降级保障基本可用。落地建议:推理实例部署健康检查和心跳机制,路由层实时感知实例负载;模型权重缓存到本地 SSD,将冷启动时间从分钟级降到秒级;跨可用区部署至少两个推理集群,主集群故障时自动切换;降级策略需要明确告知用户,
层级名称核心问题典型选项L1硬件层GPU/TPU/NPU选什么?多少卡?A100/H100/B200/L40S/昇腾910BL2云平台层自建还是上云?裸金属还是K8s?AWS/Azure/GCP/阿里云/自建IDCL3推理引擎层用什么推理框架?L4编排框架层如何管理Prompt和Agent?LangChain/LlamaIndex/Spring AI/自研L5应用框架层如何构建最终应用?RAG/C
jvm
——jvm
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区


 智能体开发者社区
智能体开发者社区

 AtomGit AI 社区
AtomGit AI 社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 DeepSeek技术社区
DeepSeek技术社区
 MCP技术社区
MCP技术社区
 AI编程社区
AI编程社区

 AI硬件创业社区
AI硬件创业社区
 AI Agent技术社区
AI Agent技术社区
 人工智能6S服务平台
人工智能6S服务平台
