登录社区云,与社区用户共同成长
邀请您加入社区
GRUB2是Linux系统最常用的引导加载程序(Boot Loader)。它的核心职责:允许用户选择启动哪个操作系统或内核版本向内核传递启动参数(如调整运行级别、启用调试模式)提供救援模式入口单用户模式是一种维护模式,用于:重置root密码(忘记root密码时)修复文件系统错误排查启动故障移除损坏的软件包Systemd 是 Linux 系统的初始化系统(init system)和服务管理器,PID
“想要用docker搭建Hadoop集群吗?想要的话可以看我这篇博客!我把好多坑都走了,尽情复制吧!”
基于 CentOS 7 搭建 GitLab
openssl安装
链接:https://pan.baidu.com/s/1gx-5WJk5YPWIIXT8iEzkbQ提取码:6666
SSD固件是运行在主控芯片上的嵌入式操作系统,负责FTL地址映射、垃圾回收、磨损均衡、ECC纠错、温度管理等所有底层逻辑。它决定了SSD的性能表现、数据安全和使用寿命。本文从固件的架构分层、核心模块、启动流程、升级机制到安全风险,全面拆解这块"隐藏在硬件中的软件"。
CentOS 7下PyTorch/PyArrow运行时库升级方案 针对CentOS 7运行深度学习框架时出现的libstdc++和libgcc_s版本过低问题,本文提供了一种安全高效的解决方案。关键点包括: 问题根源:Devtoolset的沙盒隔离机制导致编译期与运行期库版本不一致,系统仍使用默认的GCC 4.8.5动态库。 解决方案: 从Anaconda提取预编译的GCC 11.2运行时库(li
本文介绍了Linux学习中常用的两类开发工具。首先讲解了软件包管理器(如yum/dnf、apt),重点说明其解决依赖关系的优势,并列出CentOS系统下dnf的常用命令。其次详细介绍了vim多模式编辑器的三种基础模式(命令/插入/底行模式)及其核心操作命令,包括模式切换、光标移动、编辑操作等,同时提及了vim的配置文件位置。全文强调Linux生态中软件来源的社区属性,指出丰富的软件仓库是衡量操作系
我安装了一次,发现安装完成后重启,出现报错,导致不能顺利进入操作系统。我的这台电脑的主板以前坏过,因此更换了主板,当时买了一块不知名厂家的主板。因为当时我的CPU、内存和显卡还能用,如果要使用它们,主板就不好找,因此找了一块不知名的主板。我想可能是两块显卡导致故障,因此我把显卡拔下来,然后重装centos5.x,这一次顺利安装成功。因此故障原因可能是centos5.x没有老显卡的驱动,或者是在ce
一. 远程桌面在windows10远程上操作jetson Xavier,远程的前提:jetson xavier和Windows的PC在同一个局域网内(我这里是直接在windows10上开启热点)。安装xrdp:sudo apt-get install xrdp vnc4server xbase-clients1.1:桌面共享没反应桌面共享其实就是一个vnc-server(因此没有必要再在linux
• TCP/IP协议的本质是⼀种解决方案• TCP/IP协议能分层,前提是因为问题们本身能分层TCP/IP协议与操作系统的关系(宏观上,怎么实现的)为什么 Windows 和 Linux 能互相通信操作系统可以不一样,但是两端的网络协议栈必须遵守同一套标准。各层在系统中的位置应用层:操作系统之上,由用户应用程序实现传输层、网络层:集成在操作系统内核数据链路层:网卡驱动程序中网卡:底层硬件TCP/I
上一篇文章我们讲解了如何编译基于cpu版本的Dynaslam,但是实时性差得很啊!!!!因此本文决定编译基于***gpu版本的Dynaslam***!!!!!!!!实际上大体的编译过程和上一篇博客基本一致,只是需要安装对应的CUDA和cudnn以及tensorflow-gpu版本,下面一步步的进行介绍:1、下载cuda9.0(必须9.0,不是9.1或者9.2)至于具体如何安装大家参见这篇博...
操作系统环境CentOS6.6vlmcsd发布地址:http://forums.mydigitallife.info/threads/50234-Emulated-KMS-Servers-on-non-Windows-platforms1.找到二进制和源码下载下载地址:http://rghost.net/6G8wYxwnX解压密码20152.解压解压后找到vlm
本教程将指导您在 CentOS 7.9(2009 版本)操作系统上,部署一个高可用的 RocketMQ 4.9.8 集群。我们采用经典的“两主两从”架构,并配置为同步复制(SYNC_MASTER)和异步刷盘(ASYNC_FLUSH),以在保证数据可靠性的同时,兼顾写入性能。我们可以在四台机器中的任意两台(例如 101 102 103)上启动 NameServer,以实现高可用。在规划 Rocket
摘要:本文包含4个实用的Shell脚本实现:1)批量创建100个用户并生成随机密码,输出到userlist.txt;2)通过源码编译安装Nginx并实现开机自启动;3)系统巡检脚本,检测CPU、内存、磁盘和IO使用率;4)主机存活检测脚本,通过ping命令检查IP列表中的主机状态。每个脚本都包含详细实现代码和功能验证说明,适用于Linux系统管理场景。
本文详细介绍了GREP工具的使用方法及正则表达式的语法规则。GREP是一种强大的文本搜索工具,支持多种参数选项如忽略大小写(-i)、显示行号(-n)、递归搜索(-r)等。文章将正则表达式分为基础正则和扩展正则两类,系统讲解了字符匹配、次数匹配、位置边界匹配以及分组与后向引用等核心语法。通过一个测试文件演示了GREP与正则表达式结合的实际应用场景,包括字符集匹配、位置锚定、次数限定等常见操作示例。文
是一种网络引导技术,允许计算机在没有本地硬盘、光驱或 USB 的情况下,通过网络从服务器加载操作系统镜像并启动安装程序。它依赖于 DHCP、TFTP 和 HTTP/FTP/NFS 等协议协同工作。Cobbler是一个 Linux 安装服务器,它封装并自动化了 PXE 配置的复杂性,提供了 Web 管理界面,可以集中管理发行版、配置文件、系统模板和电源管理,极大简化了批量系统部署。如果你需要更个性化
本文是一篇详细的 MySQL 安装教程,全面覆盖了 Windows 和 Linux 两大操作系统的安装方法。Windows 系统部分详细介绍了两种安装方式:MSI 安装包(图形化安装向导)和 ZIP 压缩包(手动配置安装),包括下载步骤、安装过程、服务管理、环境变量配置等完整流程。Linux 系统部分基于 CentOS Stream 8,演示了通过 dnf 包管理器安装 MySQL 8.0.26
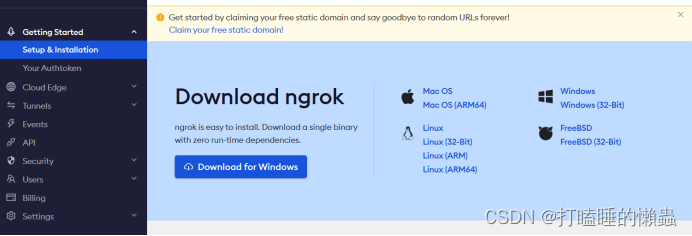
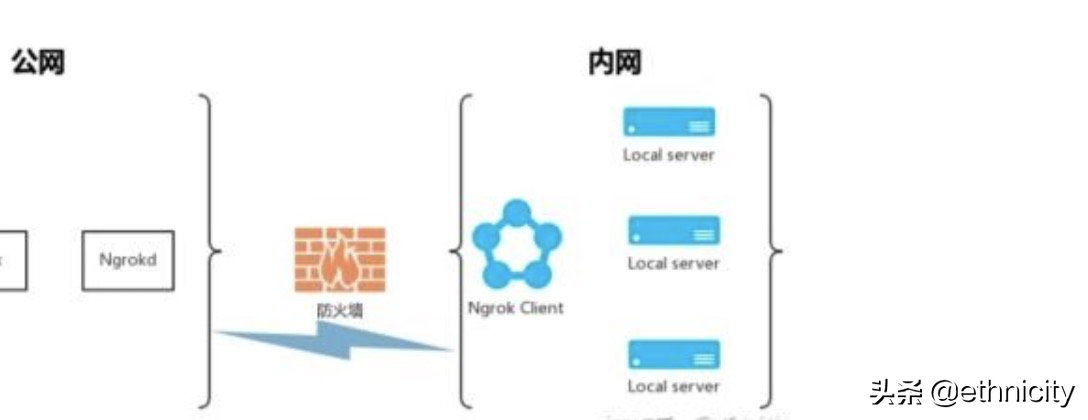
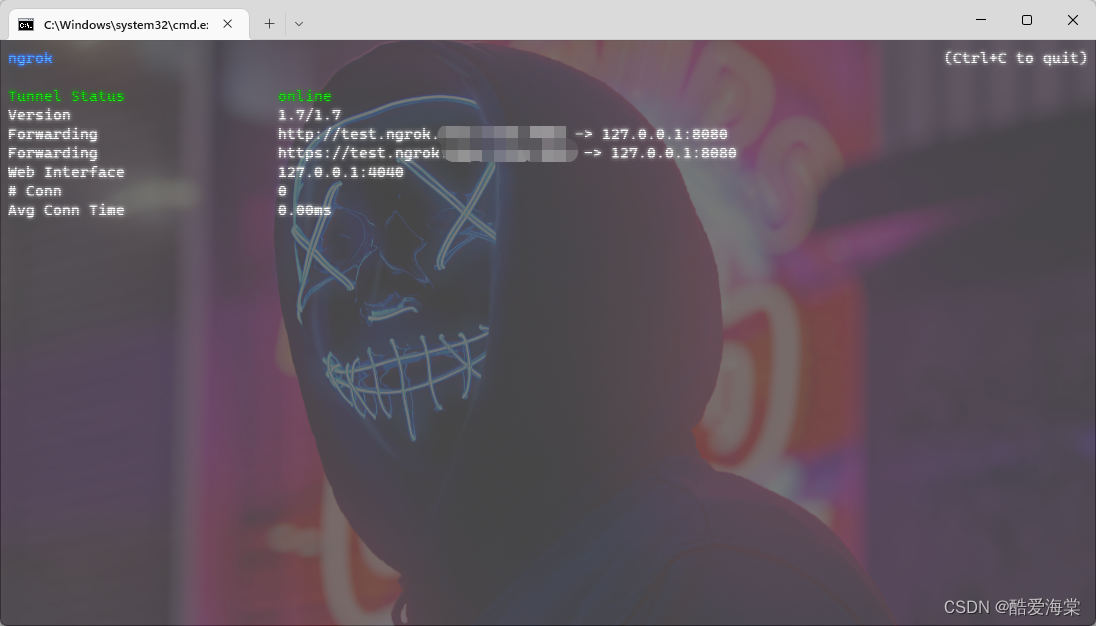
什么是NgrokNgrok是一款用go语言开发的开源软件,它是一个反向代理。通过在公共的端点和本地运行的Web服务器之间建立一个安全的通道。Ngrok可捕获和分析所有通道上的流量,便于后期分析和重放。应用场景用于对处在内网环境中,无外网IP的计算机的远程连接。Ngrok可以做TCP端口转发,对于Linux可以将其映射到22端口进行SSH连接。Windows的远程桌面可以
1.vagrant安装注意Vagrantfile 文件的创建,需要命令行窗口在管理员权限下才能进行2.virtualBox虚拟机ip修改修改结果:
本文详细介绍了在Linux系统中安装DeepSeek及相关组件的完整流程。主要内容包括:1)系统环境准备,包括更新系统、安装开发工具和Python环境;2)Docker的安装配置,包括卸载旧版本、添加镜像源和设置加速器;3)Ollama的两种安装方法及服务配置;4)Open-WebUI的pip安装和启动方法;5)DeepSeek的配置建议以及两者集成方案;6)常见问题解决方案,如Docker启动失
但是centos直接运行报错,参考。ubuntu可以直接。
同时开放多个端口修改配置文件ngrok.yml(这个文件一般在执行注册命令的时候会生成,里面有一个authtoken:)在这里添加你想要的端口,形式如下:红色框里面代表你要添加的端口,如需更多继续在后面跟上即可保存文件,回到ngrok目录,执行./ngrok start --all(启动所有端口)./ngrok start tunnel1 tunnel2 (启动指定端口)启动完成后如下图...
lenovo电脑安装双系统(win8+centos8), 分区efi+gpt默认Windows8,引导是system_drv/EFI/Microsoft/boot/bootmgfw.efi使用EaseUS Partition Master Free Edition 分区, 分出9G Ext3用来存储centos8 ISO文件, 空闲20G安装centos8使用Rufus3.13.1730制作 ce
1.安装gityum install git查看git 版本:
右上角,设置-地区-使用当前地区,返回就会出现一个聊天(前提是有tizi)
上免费下载,但下载前需要进行登录,可以使用谷歌邮箱登录或者github账户登录,也可以使用邮箱注册新账户登录,注册新账户时需验证邮箱后方可激活。4. 执行如下命令,启动服务,生成随机域名实现内网穿透(这里的端口可以换成其他的,但是要能通过防火墙,也可以关闭防火墙)。由于后面的操作中需要使用到apt或snap命令,而Cent OS 7并未预装此类命令,这里选择安装snap命令。到这里snap就安装好
问题描述问题一Centos7 安装JDK 报错[root@localhost admin]# rpm -ivh /usr/jdk-8u311-linux-x64.rpm警告:/usr/jdk-8u311-linux-x64.rpm: 头V3 RSA/SHA256 Signature, 密钥 ID ec551f03: NOKEY警告:正在等候 事务 锁定 /var/lib/rpm/.rpm.lock
添加隧道到目标服务器内网网段路由*.*.*.*/* 替换为目标服务器内网网段。#添加隧道到目标服务器内网网段路由*.*.*.*/* 替换为目标服务器内网网段。modprobe ip_gre #开启gre模块。#创建隧道节点ip 不要与服务器本身路由冲突就行。modprobe ip_gre #开启gre模块。#创建隧道节点ip 不要与服务器本身路由冲突就行。替换为服务器A的内网IP地址,将。替换为服
准备一台云服务器(本文ECS),一个域名(二级域名也可以),并且域名正确解析到云服务器安装环境安装gcc和git(下载ngrok源码)yum install gcc -yyum install git -y安装go语言环境去官网https://golang.org/dl/下载最新安装包网很慢的下载地址:https://pan.baidu.com/s/1c2i2oa
阿里云服务通过docker,ngnix完美搭建Ngrok服务器
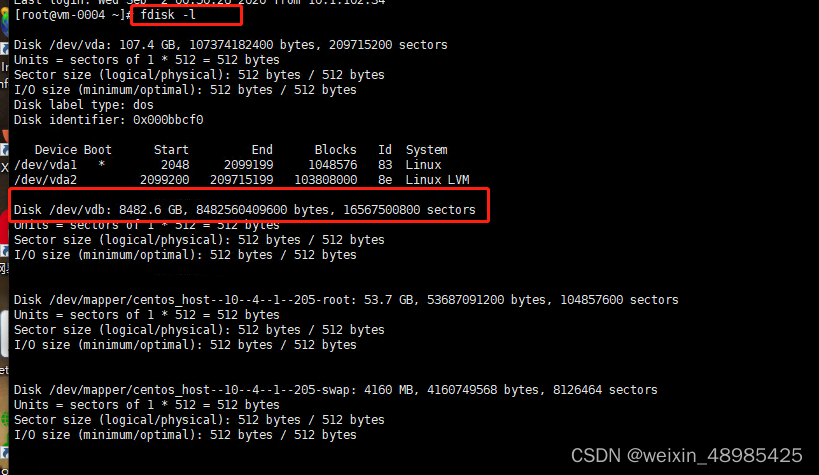
centos7下 mbr分区转gpt分区
自己动手,丰衣足食!准备工作阿里云上的centos服务器,ssh连接(xshell),ftp连接(filezilla),以及解析到服务器的域名(这里以xyz.com为例)step1:基本环境配置安装gccyum install gcc -y安装gityum install git -y安装go环境yum installgolangstep2:编译ngrok源码获得git源码git clone ht
自建ngrok服务器:服务端centos7.6,被控端windows,控制端windows;实现内网穿透
场景需要一个有固定公网ip地址的主机,通过这个主机穿透办公室的内网主机,可以理解代理功能1、gityum -y install gitgit是1.8及其以上的版本就行2、go环境wget https://redirector.gvt1.com/edgedl/go/go1.9.2.linux-amd64.tar.gztar -zxvf go1.9.2.linux-amd64.tar.gz -C /u
移动硬盘用命令查看得知是gpt格式的parted /dev/sdc print#看下硬盘的具体分区情况mount -t ntfs /dev/sdc1 /usr/local/test1mount: 未知的文件系统类型“ntfs”如果是这里出错 是系统无法识别ntfs分区这里是需要安装一个软件包ntfs-3g 让系统识别ntfs官网地址下载https://www.tuxera.com/communit
安装环境安装gcc和gityum install gcc -yyum install git -y安装go语言环境yum install -y mercurial git bzr subversion golang golang-pkg-windows-amd64 golang-pkg-windows-386检查环境安装git ...
由于Ngrok是一个端口阻塞的程序,我们运行了,就会导致程序的界面一直占用,这时候,我们需要和Screen结合起来用了,通过screen,就可以解决端口阻塞的程序问题了
ngrok是一个内网穿透的解决方案,它可以使你的本地网络暴露在公网,就是不局限于局域网进行访问,ngrok分为服务端和客户端,需要将服务端部署到现有公网服务器,客户端在本地运行即可注意:需要提前将服务中需要用到的端口全部开放,默认需要的端口 80、443、4443,有防火墙的也需要开放这些端口,第一次编译服务的时候可能会比较慢,多等一会就好了。...
当下使用chatgpt来帮助完成工作已然成为主流,但想访问必须先面对地区的封锁,所以使用openai官方提供的API来部署至本地服务器从而更加便利的使用chatgpt。本文章主要介绍如何部署私有聊天机器人。
本文是我从零开始部署 k3s 并将考试系统跑起来的完整过程,每一步都有具体的命令和输出,适合和我一样刚入门的同学参考。你只需要描述"我想要什么状态"(Deployment、Service、Pod 的 YAML),K8s 的控制平面会不断地把实际状态往期望状态上收敛。Pod 挂了自动重建,节点重启后自动恢复,这就是 K8s 自愈能力的来源。:自带 Traefik(Ingress)、CoreDNS(D
讲解了centos8的linux系统,怎么安装pgsql16数据库,并可远程连接访问。包含官网下载地址。
-auth-local=authmethod 连接的本地用户指定在pg_hba.conf中使用的认证方法 这个选项为通过 Unix 域套接字连接的本地用户指定在pg_hba.conf中使用的认证方法 (local行)。此外,在具有大量WAL的数据库中,每个目录的WAL文件的绝对数量可以成为一个性能和管理问题。如果--locale-provider是内置的,那么必须指定--locale或--buil
5.有时候会提示文件无法删除,显示Read-only file system.加入这一行后,就可以进入系统的单用户模式,此模式下可对文件进行操作。:Linux CentOS7 系统,卡在开机界面。4.进入到命令行模式后,利用cd ls rm 命令。1.长按电源键关机,开机后,进入选择内核界面。:系统磁盘空间不足,导致开机无法进入系统。:进入安全模式,删除一些文件,再重新开机。6.清理完成后,重启系
本文介绍了在CentOS 7系统上安装MySQL 8.0的完整步骤。主要内容包括:卸载系统自带的MariaDB以避免冲突;下载MySQL资源包并解压安装;配置环境变量和my.cnf配置文件;创建数据存储目录;初始化MySQL数据库;最后启动MySQL服务。文中详细说明了每个操作步骤的具体命令和注意事项,特别是配置文件的路径设置和初始化参数的选择。通过本文的指导,用户可以顺利完成MySQL 8.0在
centos
——centos
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区


 深开鸿 技术专区
深开鸿 技术专区







 AI编程社区
AI编程社区



 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区


























 AtomGit AI 社区
AtomGit AI 社区





