登录社区云,与社区用户共同成长
邀请您加入社区
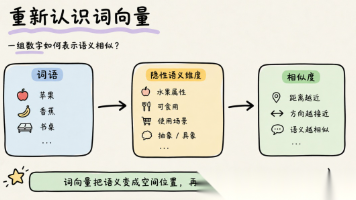
前面讲线性代数时,我们知道了:向量就是一组有顺序的数字。但到了自然语言处理里,问题会变得有点奇怪:
文章摘要 本文介绍了向量数据库在RAG系统中的核心作用,重点对比了Chroma和FAISS两种主流向量数据库的特性与应用场景。主要内容包括: 向量数据库原理:支持语义相似度搜索,与传统数据库的精确匹配形成对比 Chroma与FAISS对比:Chroma简单易用适合原型开发,FAISS性能优异适合大规模数据 元数据过滤技术:通过结构化条件缩小搜索范围,提高查询效率和结果相关性 设备维修系统架构设计建
✅ 优点检索速度天花板,支持 CPU/GPU 加速索引丰富(FLAT、IVF、HNSW、PQ),可灵活取舍速度 / 精度无服务依赖,代码内嵌直接跑❌ 缺点无自动持久化,需手动保存 / 加载索引无元数据管理,文档、标签需要自己维护不适合频繁增删改的动态业务FAISS = 检索引擎:负责算得快,不管存、不管管,做底层内核、离线实验首选。Chroma = 本地玩具库:零配置无脑用,专注开发调试、原型验证
是什么:RAG是一种在大模型回答前先检索外部知识再生成答案的技术。通⽤的基础⼤模型存在一些问题:幻觉问题,LLM有时会⽣成看似合理但实际错误的信息LLM的知识不是实时的,模型训练好后不自动更新知识,导致部分信息滞后LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识。
众所周知,大语言模型在落地应用时会遇到各种各样的问题。而其中模型的“致幻性”是非常可怕。目前主流之一的玩法就是通过知识库对回答范围进行限制。本来想等langchain-ChatChat大佬们的0.3.0版本。等待是折磨的,那不如在等待的时候,自己来瞎折腾玩玩。为了快速跑通,目前大家比较喜欢的就是用langchain来把Embedding模型和向量数据库和LLM模型串联起来。
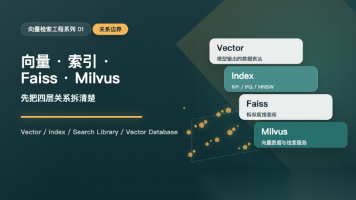
本文对比了Chroma、Milvus、Faiss、Weaviate四个开源向量数据库/库的核心特性和适用场景。Chroma轻量易用,适合原型开发;Milvus支持大规模企业级应用;Faiss是高性能检索库,适合底层优化;Weaviate结合向量和图结构,适合语义关系查询。选型建议:小项目用Chroma,企业级用Milvus,性能优化选Faiss,复杂语义关系用Weaviate。
本文深入解析检索增强生成(RAG)技术栈,涵盖核心原理与工程实践。首先介绍RAG如何通过检索外部知识解决大语言模型的三大局限(知识陈旧、幻觉问题、私有知识盲区),并对比其与微调方案的优劣。重点剖析Embedding模型如何将文本映射为语义张量,以及向量相似度度量方法。随后系统梳理向量数据库的核心价值,对比主流索引算法(IVF、HNSW、PQ等)特性,并详细评测Milvus与FAISS的性能差异。最
优势是速度最快,GPU 版本在百万级数据集上毫秒级出结果,支持多种索引类型(FlatL2、IVF、HNSW 等),社区成熟。的存储架构更灵活,2.x 版本将存储层解耦为 RocksDB(本地存储)和对象存储(分布式存储),配合 etcd 管理元数据。FAISS 这边,当数据量从 500 万增长到 2000 万时,IVF_FLAT 索引的查询延迟从 12ms 飙升至 87ms,内存占用增加了 3.2
方案评审里,三类问题经常被混在一起讨论。第一类是数据问题:embedding 出来的向量质量不够好,换索引能不能救回来?
本文系统介绍了RAG(检索增强生成)技术的核心原理、架构与工程实践。主要内容包括:RAG工作流程解析(文档分块、向量检索、生成增强);Embedding模型选型指南(BGE、OpenAI等主流模型对比);向量数据库横评(ChromaDB、FAISS、Milvus等优缺点分析);实战代码示例(ChromaDB极速上手、FAISS本地检索、Milvus分布式部署);高级技巧(混合检索、Rerank重排
本文分享了在搭建半导体工艺文档智能检索系统时,针对传统全文检索(如Elasticsearch)无法满足语义搜索需求的问题,作者探索了三种向量数据库方案(FAISS、Chroma、Milvus)的实践经验。通过对比15万份技术文档的处理效果,总结出:FAISS适合离线批量检索,Chroma便于快速原型开发,Milvus则适用于大规模生产环境。文章详细分析了技术原理、性能指标(查询延迟、召回率、运维成
向量数据库是 RAG(检索增强生成)系统的核心基础设施。当你的知识库从几千条增长到百万、千万级时,向量检索的性能瓶颈就会彻底拖垮你的 AI 应用响应速度。Faiss:Meta 出品的纯库,轻量但功能有限Milvus:云原生向量数据库,功能完整,生产级首选Qdrant:Rust 写的新一代向量库,性能出色,API 友好本文将从原理对比 → 性能实测 → 部署配置 → 调优指南四个维度,帮你做出最适合
移动语义的引入显著减少了不必要的内存拷贝,通过右值引用实现资源的高效转移。针对特定场景的自定义分配器可显著提升性能,例如使用monotonic_buffer_resource进行短期对象的快速分配。C++20引入的std::memory_order为原子操作提供精细的内存序控制,避免不必要的内存屏障开销。算法选择应考虑复杂度与实际数据规模,并行算法(std::execution::par)可充分利
文章摘要 该项目构建了一个基于RAG(检索增强生成)技术的物流行业智能问答系统,旨在通过自然语言处理回答用户关于货物追踪、仓储信息等物流问题。系统采用DeepSeek作为大语言模型,结合本地BGE-small中文Embedding模型和FAISS向量数据库实现高效检索。技术栈包括LangChain框架、PyMuPDF文本解析和Streamlit前端界面,支持私有PDF文档的向量化存储与语义搜索。核
总而言之,const是C++语言中一项强大而基础的特性,它贯穿于变量定义、指针操作、函数接口和类设计之中。深入理解并恰当应用const,能够显著提升代码的质量,使其更安全、更清晰、更易于维护。它是C++程序员工具箱中不可或缺的一件利器,体现了C++对类型安全和工程实践的重视。养成使用const的良好习惯,是每一位C++开发者走向成熟的重要标志。
展望未来,C++的发展将呈现几个关键趋势。最后,伴随着标准化的推进,C++的工具链(编译器、调试器、静态分析工具)将越来越成熟和强大,从而降低新手的入门门槛和资深开发者的维护成本。面对未来,C++并非在衰退,而是在不断演化,专注于其最擅长的阵地,并在可预见的未来,继续作为构建数字世界关键基础设施的基石语言而熠熠生辉。概念(Concepts)的加入是C++20里程碑式的特性,它为模板编程提供了强大的
随着 `C++23` 对协程泛化(`co_await`表达式灵活化)的支持,下一代网络协议栈(如HTTP/3、QUIC)的设计大门已被打开。通过`co_await socket::read_validation()`将协程挂起在TCP的`MSG_WAITALL`报文 完整接收 后触发,同步完成数据缓冲区校验,避免多余拷贝。C++20的新型异常处理模型(如`try`/`catch`增强与`std::
通过上述步骤,我们成功构建了一个基于 VLLM、LangChain 和 FAISS 的知识库问答系统。这个系统可以从 PDF 文件中提取文本内容,将其存储到 FAISS 索引中,并使用语言模型生成答案。
确保已安装Faiss库及其依赖(如GPU版本需额外配置)。生成或加载待索引的向量数据,格式为。
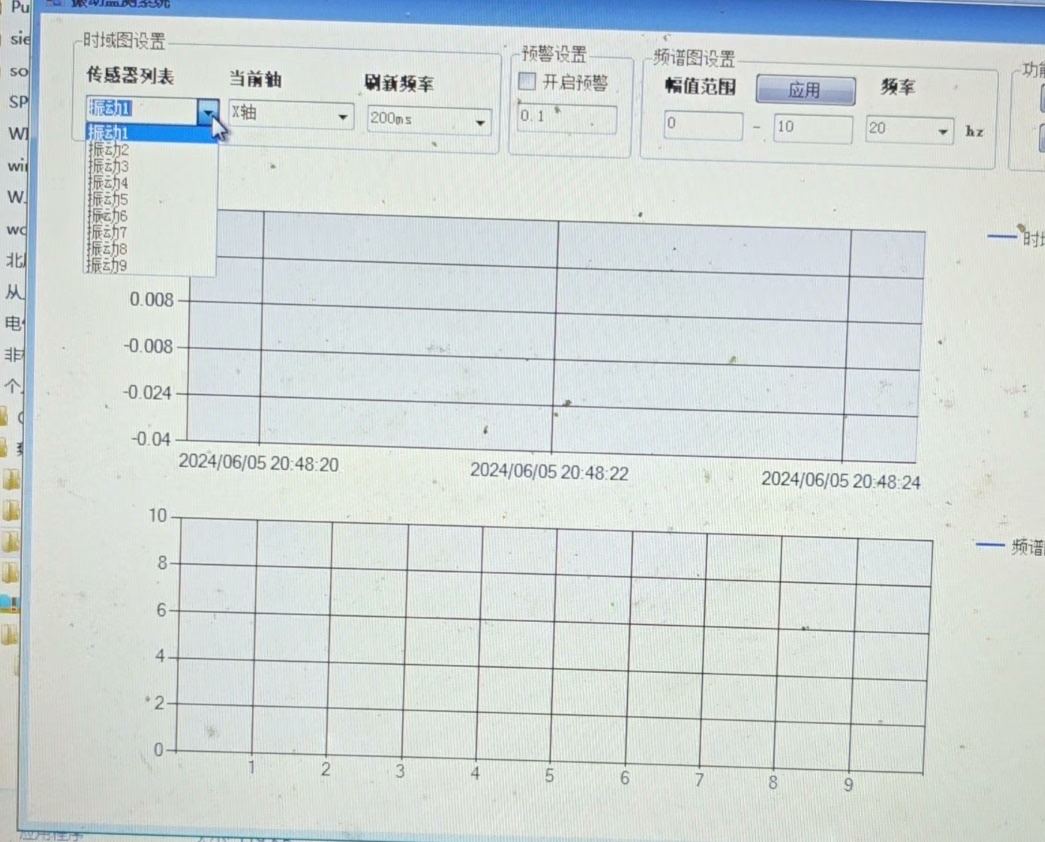
最近在搞工业设备监控系统的时候,需要实时采集振动和温度数据。正好用C#搭了套方案,这里把核心代码和实现思路分享一下。先上张效果图镇楼(假装有图),频谱图和时域图同屏显示还挺酷的。整个系统跑下来,最吃资源的其实是频谱计算部分。C#频谱图振动传感器温度传感器数据采集绘制频谱图和时域图,并存储数据库存储时间200ms左右,可以进行历史频谱图和时域图回放,可以求的最大值并设置阈值报警可以导出报警。不过实际
本文介绍了一种基于向量检索的本地文档语义搜索系统构建方法。通过LangChain的DirectoryLoader/TextLoader加载本地TXT文档,使用BCE嵌入模型将文本转换为向量,并利用FAISS实现高效相似度匹配。系统支持批量文档处理和带评分的语义检索,得分越低表示匹配度越高。该方法完全离线运行,保障数据安全,可扩展支持PDF、Word等多种格式,适用于企业文档检索和个人知识管理。核心
上一篇加了Memory,但是由于是短期记忆,所以有很多限制,从这篇开始,我们学习长期记忆,是 Agent 从「聊天玩具」➡「可成长系统」的分水岭。
本文介绍了如何使用LangChain、Ollama和FAISS在本地搭建一个轻量级RAG(检索增强生成)应用。通过结合开源大模型Qwen2.5、中文嵌入模型bge-m3和高效向量检索库FAISS,实现了一个完全本地化、无需联网的知识问答系统。文章详细讲解了环境准备、代码实现步骤,包括文本切分、向量数据库构建、提示词模板定义等关键环节,并提供了扩展建议。该方案数据完全私有,适合企业内部知识库和个人笔
前几天圈子里有人去面蚂蚁,岗位是大模型应用开发,简历上写"熟练使用 Claude Code 进行日常开发"。一面聊项目聊得挺顺利,面试官对他做的 Agent 方案挺感兴趣,追问了好几个细节,他都答上来了。气氛不错,他心里还暗暗松了口气。
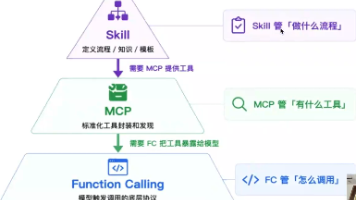
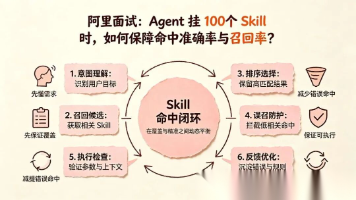
这是 Agent 工程化方向的技术面试中, 一道出现频率极高、区分度极强的经典问题:**Agent 上挂载了几十个 ,上百个 Skill,如何保证命中率?
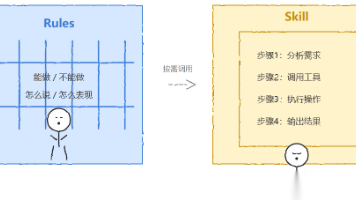
Skill和Rules看似都是"给AI下指令",但本质上解决的是完全不同层次的问题。一个管的是"AI始终要保持的状态",另一个管的是"AI在特定场景下的专业能力"。混在一起,两头都做不好。
从Key帧检索到场景匹配,教你如何在海量视频库中,用一张图片定位到精确帧!
向量数据库Faiss(Facebook AI Similarity Search)是Facebook AI Research开发的一款高效且可扩展的相似性搜索和聚类库,专门用于处理大规模向量数据的搜索和检索任务。Faiss以其出色的性能和灵活性,在图像检索、文本搜索、推荐系统等多个领域得到了广泛应用。以下将详细介绍Faiss的搭建与使用过程,包括安装、基本使用、索引类型选择、性能优化及应用场景等方
faiss
——faiss
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区



 2048 AI社区
2048 AI社区


 DAMO开发者矩阵
DAMO开发者矩阵










 AMD开发者中国社区
AMD开发者中国社区
 AI Agent技术社区
AI Agent技术社区
 DeepSeek技术社区
DeepSeek技术社区







 龙虾开发者社区
龙虾开发者社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


