登录社区云,与社区用户共同成长
邀请您加入社区
OpenAI Codex是一款面向开发者的AI编程工具,支持自然语言转代码、调试、自动化系统操作等功能,适配Windows和macOS系统。Windows用户可通过微软商店或WSL2安装,macOS用户推荐Homebrew或NPM安装。国内用户可使用CC-Switch接入国产大模型(如DeepSeek)规避OpenAI账号限制。核心功能包括代码生成、调试、本地文件操作等,但存在语言适配(界面仅英文
CCSwitch是一个本地代理工具,可将第三方大模型API转换为OpenAI兼容格式,使CodexCLI/CodexDesktop支持小米MiMo、Claude等模型。安装后通过15721端口转发请求,用户只需在界面添加供应商API信息并激活即可使用。它能自动管理Codex配置,支持热切换供应商和多种代理模式,并备份配置日志方便排查问题。操作流程为:安装软件→添加供应商→激活使用→通过Codex直
Agent Skill 是 Agent 可以调用的、面向具体任务封装好的能力单元。它可以是一个函数,也可以是一个 API,也可以是一段工作流,还可以是一个外部服务。搜索网页;查询数据库;读取文件;解析 PDF;调用天气 API;调用地图 API;执行代码;发送邮件;生成图片;检索知识库;调用企业内部系统;生成结构化报告。但是需要注意:Skill 不等于随便写一个函数。这个 Skill 是做什么的;
GPT-3是由OpenAI开发的1750亿参数语言模型,是GPT-2规模的100多倍。该仓库提供论文配套资源,包括生成样本、合成数据集、训练数据统计和评测基准重叠分析等,但不含模型权重。研究表明,GPT-3在few-shot设定下能完成翻译、问答等多项任务,其生成内容已接近人类水平。仓库材料对研究大模型训练评估具有参考价值,实际模型需通过API使用。论文也探讨了数据泄露风险和社会影响等关键问题。
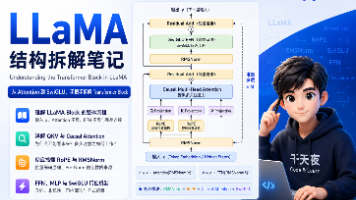
这篇文章详细讲解了LLaMA模型的Transformer Block架构,主要包括以下核心内容: LLaMA采用Decoder-only Transformer结构,通过自回归方式预测下一个token。 每层Transformer Block由两个主要部分组成: Attention和 FFN/MLP。RMSNorm,causal attention,旋转位置编码 RoPE,SwiGLU,等
本文是对LLaMA大模型研究系列的总结,重点解读了LLaMA论文的核心贡献。LLaMA证明了仅使用公开数据,通过合理的数据规模、模型结构和训练优化,就能训练出性能强大的基础语言模型。论文提出了7B-65B参数的模型系列,其中LLaMA-13B在多数任务上超越了GPT-3 175B,而LLaMA-65B则与Chinchilla-70B和PaLM-540B竞争。LLaMA的创新点在于强调"小而强"的路
摘要 论文《PatentGPT: A Large Language Model for Intellectual Property》提出了一套面向知识产权领域的领域大模型训练流程,而非全新架构。针对知识产权领域三大核心挑战——专业知识强、隐私要求高、文本极长,研究团队以LLaMA2/Mixtral等开源模型为基础,通过240B+token的IP领域数据继续预训练、指令微调(SFT)、强化学习对齐(
本文是对 OpenAI 于 2022 年 3 月发表在 arXiv 上的论文《Training language models to follow instructions with human feedback》(Ouyang 等,arXiv:2203.02155)的系统性精读。该论文是 ChatGPT 技术路线的直接前身,首次将"基于人类反馈的强化学习"(Reinforcement Learn
标签管理模块通过「参数-模板-打印」模型,把传统硬编码的标签格式彻底数据化。二次开发时,90% 需求只需修改配置或增加字典项,真正需要编码的场景集中在驱动层新打印机适配。理解上述流程与代码骨架后,可在 1-2 小时内完成新标签上线,显著降低交付成本。C# Winform通用开发框架,支持多语言,多数据库,自动更新,模块化,可用其开发任意CS端系统,非常适合需要快速搭建项目的团队或个人使用。
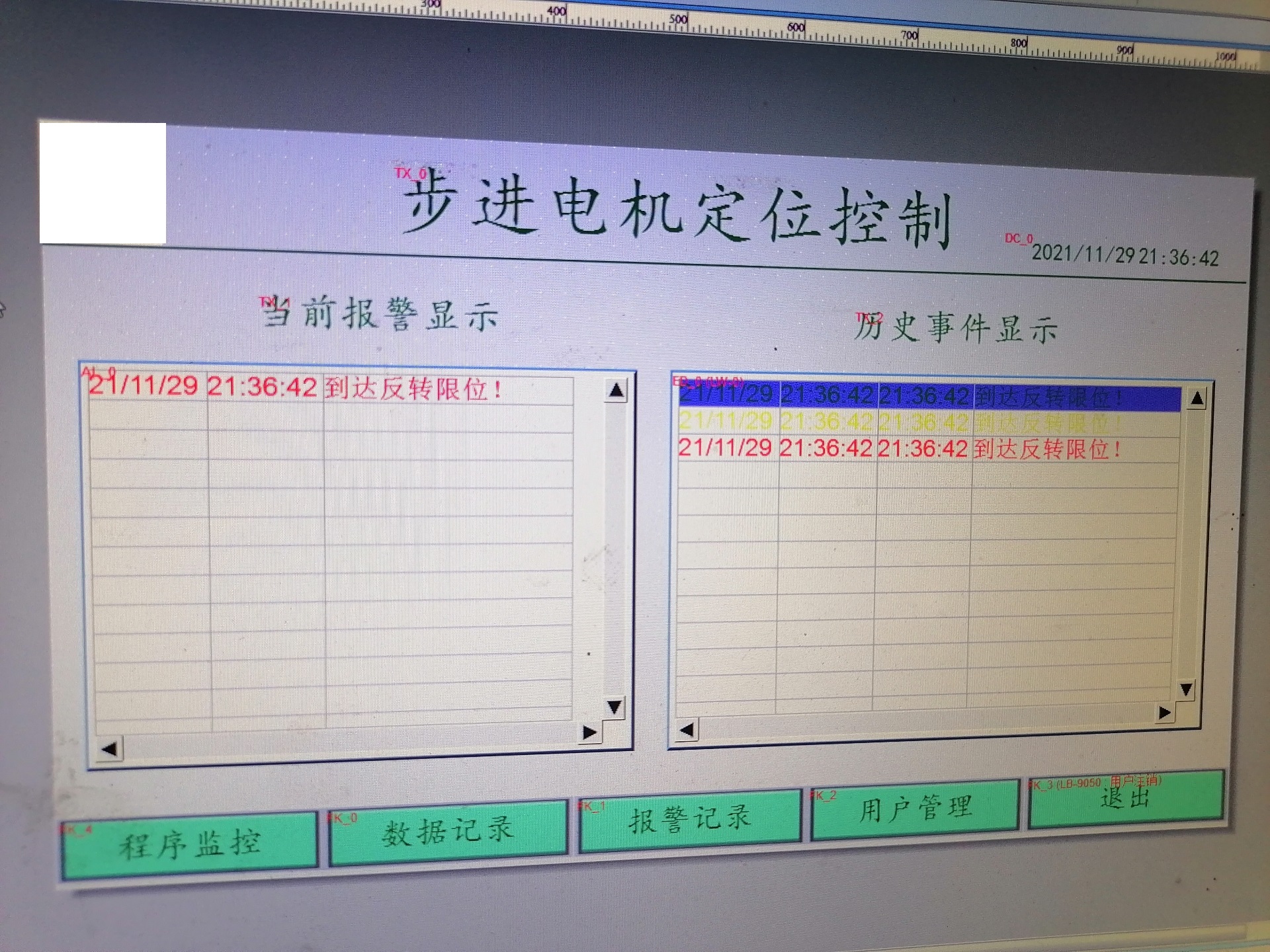
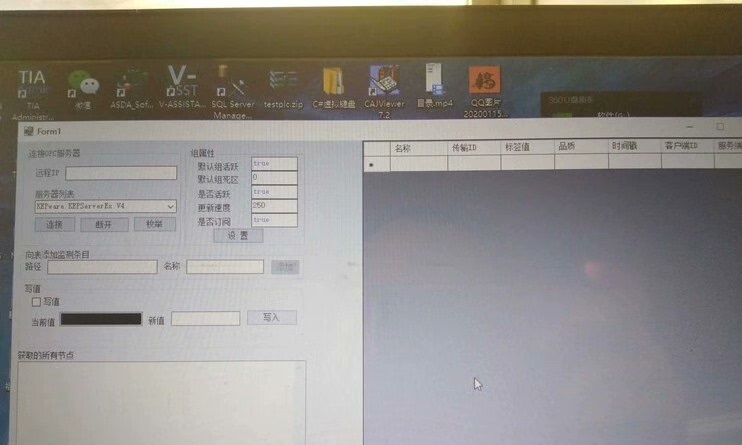
本文详细分析了一个基于C#开发的OPC客户端应用程序和工业数据采集系统。该系统主要用于与OPC服务器进行通信,实现工业设备数据的实时采集、监控和存储,并提供了完善的数据查询和管理功能。OPC Automation接口的正确使用:合理管理OPC服务器连接和组项生命周期数据库事务处理:确保数据的一致性和完整性跨线程UI更新:保证在多线程环境下的界面响应性和稳定性内存管理:及时释放COM对象和数据库连接
编辑添加图片注释,不超过 140 字(可选)来源 | 新智源 ID | AI-era 一觉醒来,Meta直接丢了一颗重磅核弹:Llama 2! 继LLaMA开源后,Meta今天联手微软高调开源Llama 2,一共有7B、13B、70B三个版本。编辑切换为居中添加图片注释,不超过 140 字(可选)据介绍,Llama 2接受了2万亿个token训练,上下文长度4k,是Llama 1的2倍。微调模
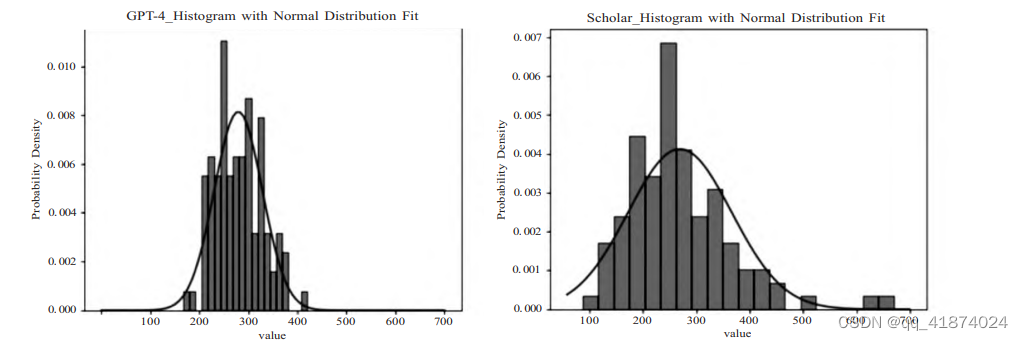
为了防止人工智能生成文本的滥用,保证生成内容的质量,并讨论如何解决人工智能生成论文所带来的问题,有必要根据主题要求,识别和检测人工智能生成文本的模式,包括字段、模型、图像和公式。它包括不同的生成语言,无论是翻译,生成的次数,以及输出字数是否有限制等,对于AI生成的理论和方法。:根据附录二中提供的十个AI生成的段落,请判断这些段落产生的次数(不超过5次),从中文翻译成英文的次数(不超过一次),从英文
i = send_message_to_bot(bot_id, user_id, message) # 获取生成器对象a = list(i) # 将生成器对象的值放入列表中print(b)if re.search('[\u4e00-\u9fff]', b): # 匹配中文字符范围。
前文已经介绍如何使用fine-tuning模型构建自己的chatbot,但是fine-tuning模型也是一个基于概率的模型,由于AI团队使用的训练集数据的规模极大且繁多,你想通过这单次的微调就很快改变模型比较有难度。幸运的是目前OpenAI团队推出了Retrieve助手,它可以基于你提供的私有数据和你进行对话,这样我们不就可以站在巨人的肩膀上做事了吗哈哈哈^^本文主要介绍openAI的assis
这是 Claude Code 源码学习系列的第三篇。Context Collapse 是四级压缩中最具创新性的设计——它将传统的"同步全文总结"进化为"后台异步多段折叠",在不阻塞用户的情况下持续维护上下文健康。
gpt-3
——gpt-3
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区

 AI编程社区
AI编程社区


 龙虾开发者社区
龙虾开发者社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 DAMO开发者矩阵
DAMO开发者矩阵