- @ultingCSDN
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
构建RAG混合开发---通过PythonAI加载大模型以及RAG知识库,结合Java访问Python与Vue.js前端的实践交互案例

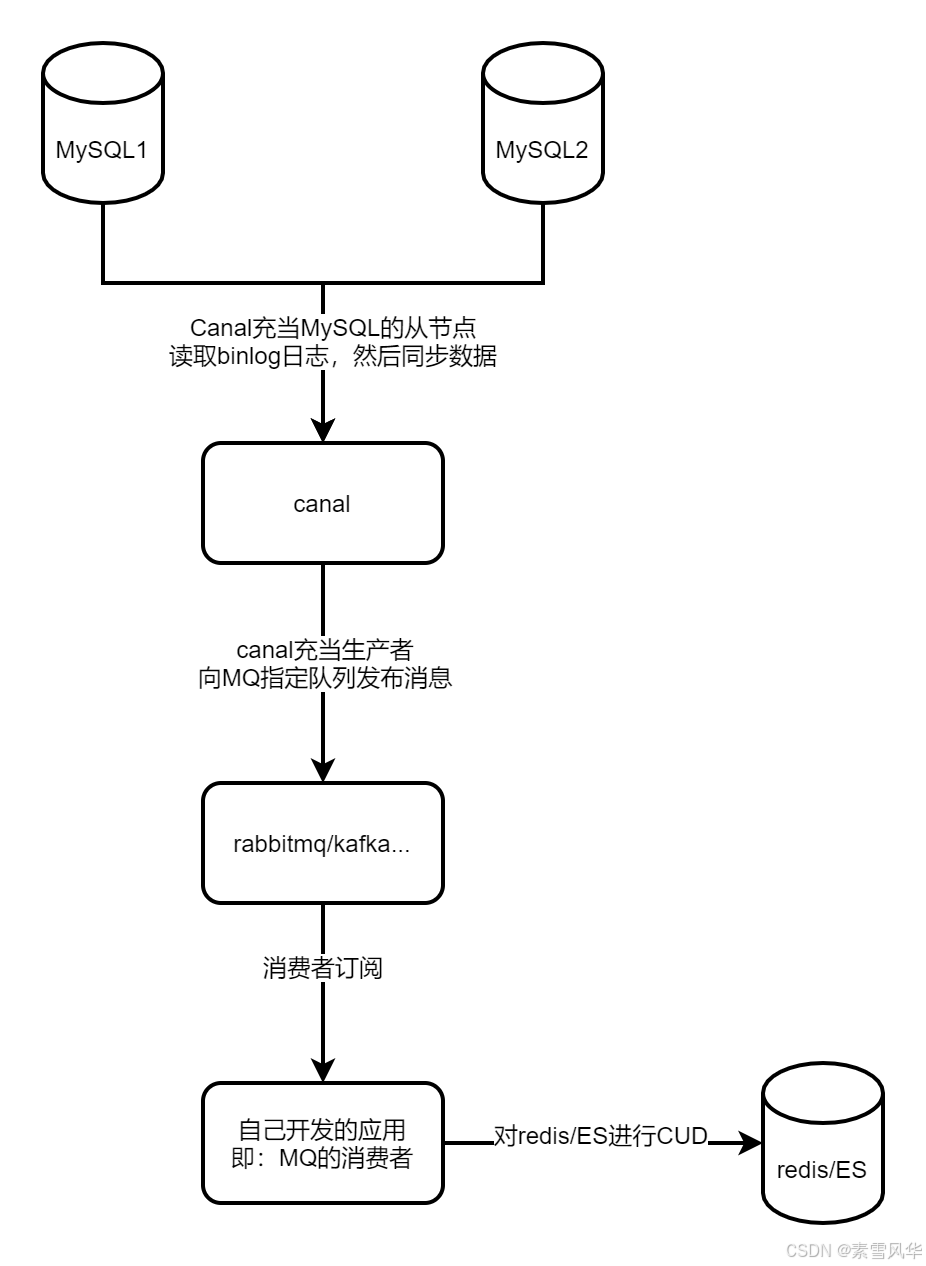
利用docker-compose安装canal并利用rabbitmq进行mysql的数据同步问题...
基于Jenkins+Docker-compose+Dockerfile+Gitee实现的自动化编译+部署实战案例
jenkins+docker+gitee实现容器自动化部署...
写在前文本文是我自己经过实践记录的,环境搭建简单快速,适合于前期学习(如果想深入了解Kafka、Redis、MySQL集群同步等相关知识本文不适用)。使用canal同步有两种方案,一种是使用canal原始的tcp方式,一种是使用canal+kafka类型;Canal原理Canal的服务端伪装成MySQL的从服务器,订阅MySQL的主服务器的binlog日志,实现增量同步数据,保持最终一...
有时候你在conda虚拟环境中,你查看pip --version以及python --version时,你会发现,它的版本和你预期的版本相差很大,这是可能是创建环境时,采用了默认python版本。,说明在conda中依然使用的是宿主机的pip,此时安装的包,会安装在宿主机的pip安装的位置,导致虚拟环境内和宿主机的pip包一样;- 如果设置conda-forge的优先级,可以直接去掉 -c con
基于Jenkins+Docker-compose+Dockerfile+Gitee实现的自动化编译+部署实战案例
jenkins+docker+gitee实现容器自动化部署...
docker-compose安装云服务器版本的一主二从一哨兵模式的redis,并使用本地应用连接redis;

基于PEFT参数高效微调的LORA实战代码