




- @yanqianglifei
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
模型上下文协议MCP与Ollama的整合实现指南在过去一两个个月里,模型上下文协议(Model Context Protocol,MCP)频繁出现在各种技术微信交流群中。我们已经看到了许多很酷的集成案例,大家似乎相信这个标准会长期存在,因为它为大模型与工具或软件的集成设立了规范。前面一篇文章给大家分享了MCP一些基础概念,但是读完之后还是模棱两可,所以决定尝试将Ollama中的小型语言模型与MCP
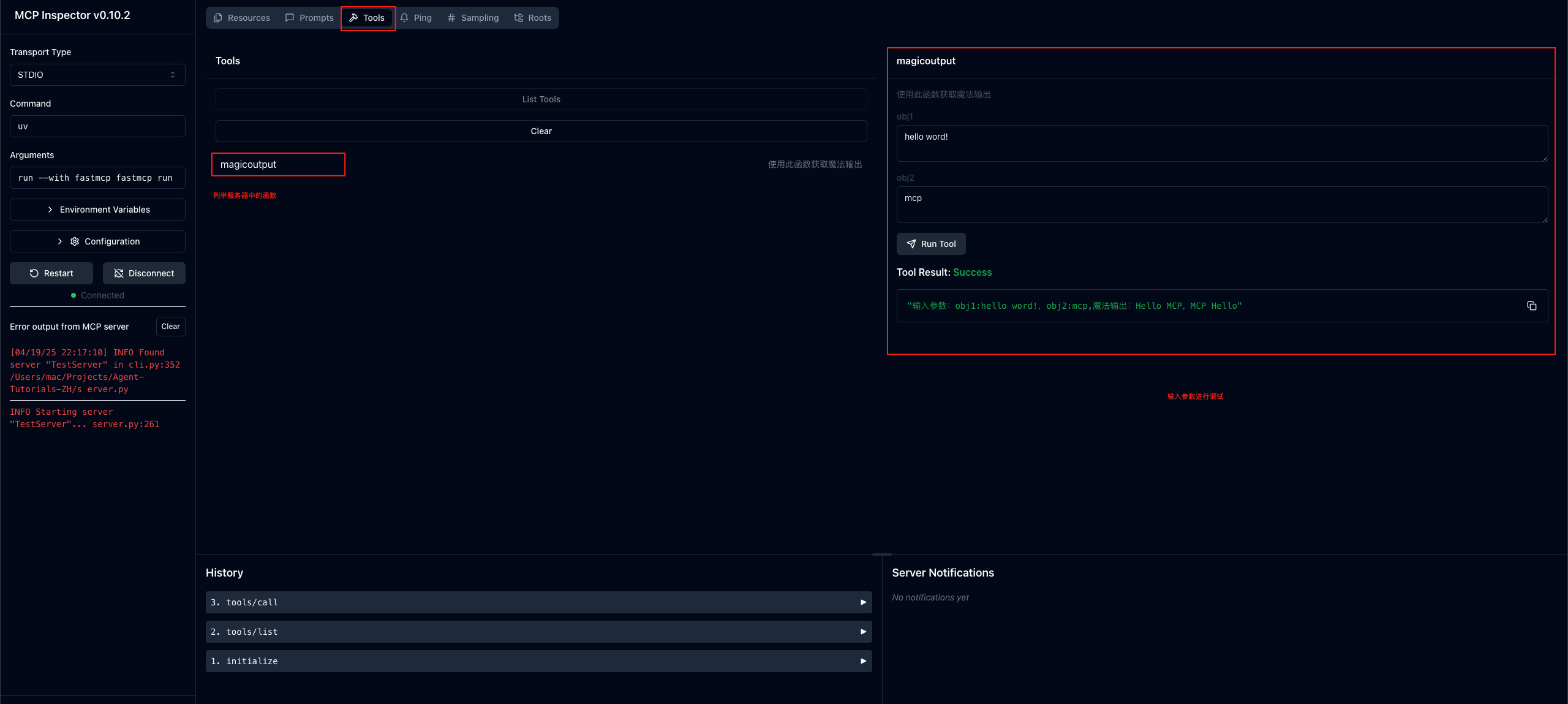
这篇论文说的是:判断一个 AI 生成的 idea,不该只问「新不新、顺不顺」,而该问「它是谁的后代」——把论文拆成可审计的想法基因,看它究竟继承了什么、改了什么、又丢了什么。而实测结果是,今天最强的 AI 科学家们,「写得像模像样」的能力,远远跑在了「血脉连贯」的能力前面。IG-Bench 真正戳中的,可能不是模型的能力上限,而是我们评价科研的方式本身。我们习惯了用「新颖性」给创意打分,可科学史从
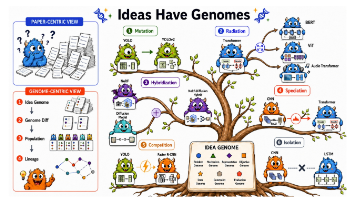
解决复杂问题不一定需要一个超大的全能模型,一个小而精的"指挥官"模型协调各种专业工具和模型可能更高效。
近几个月来,AI领域出现了一个令人担忧的趋势:尽管开源社区在不断进步,但闭源模型(如GPT-5、Gemini-3.0-Pro)的性能提升速度明显更快,开源与闭源之间的差距不是在缩小,而是在扩大。架构效率瓶颈:传统的注意力机制在处理长序列时效率极低,限制了模型的部署和训练训练资源不足:开源模型在后训练(post-training)阶段的计算投入严重不足智能体能力落后:在实际部署的AI Agent场景

智能体 RL 的竞争,正在从「调一个损失函数」变成「运营一座训练工厂」。算法差异当然存在——GRPO、PPO、REINFORCE 在不同环境里各有胜负——但真正拉开差距的,是轨迹存储的严谨度、环境编排的吞吐量、任务合成的流水线、训练崩溃的预警系统。这些东西没有一个会出现在论文的公式区,却决定了同一套算法是起飞还是崩盘。这也回答了开头的问题:3B、7B 的小模型为什么能在智能体任务上反超顶级闭源模型

上下文工程需要从"临时拼凑"升级为"系统工程"。当前主流框架虽然提供了记忆、工具等功能,但都是各自为政、缺乏统一治理的。论文提出的文件系统抽象,就像给混乱的施工现场搭了一套脚手架——所有材料(记忆、工具、知识库、人类输入)都有固定的位置,所有操作都有标准的流程,所有变更都有清晰的记录。这种"一切皆文件"的思想并不新鲜(Unix 从 1970 年代就在用了),但应用到 智能体 上下文管理却是个创新。
本文探索了Ollama 的更高级交互选项。我们测试了Ollama API的工作方式,以及重要的参数和配置,确保模型的最佳性能。定制模型,让它更好地适应特定用例,在 AI 驱动的应用程序中提供更好的用户体验。

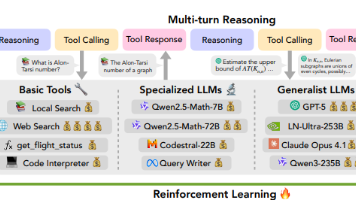
原文:https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents智能体之所以实用,正是因为它拥有自主性、智能性和灵活性,但这些特性也让评估变得更加困难。在实际应用中,那些真正有效的评估策略,往往需要结合多种技术手段,才能与被测系统的复杂度相匹配。
语言模型中存在一个众所周知但难以描述的现象,称为"上下文腐化"。Anthropic 将上下文腐化定义为"随着上下文窗口中 token 数量的增加,模型从该上下文中准确回忆信息的能力下降",但社区中的许多研究人员知道这个定义并没有_完全_切中要害。例如,查看像RULER这样流行的大海捞针基准测试,大多数前沿模型实际上表现非常好(一年前的模型就能达到 90% 以上)。但有人注意到。
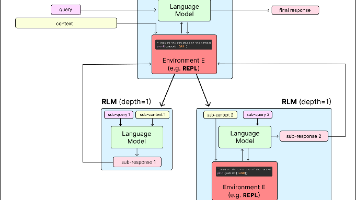
PocketFlow 的出现提醒开发者:复杂的问题不一定需要复杂的解决方案。通过将 LLM 应用建模为简单的有向图,剔除所有冗余,PocketFlow 实现了透明的逻辑和完全的掌控。如果已经厌倦了在复杂框架中"跳水",想从零开始真正掌握 AI 应用的构建,PocketFlow 的极简主义或许正是通往智能体革命的门票。GitHub 仓库 https://github.com/the-pocket/P
