- @qq_35812205
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
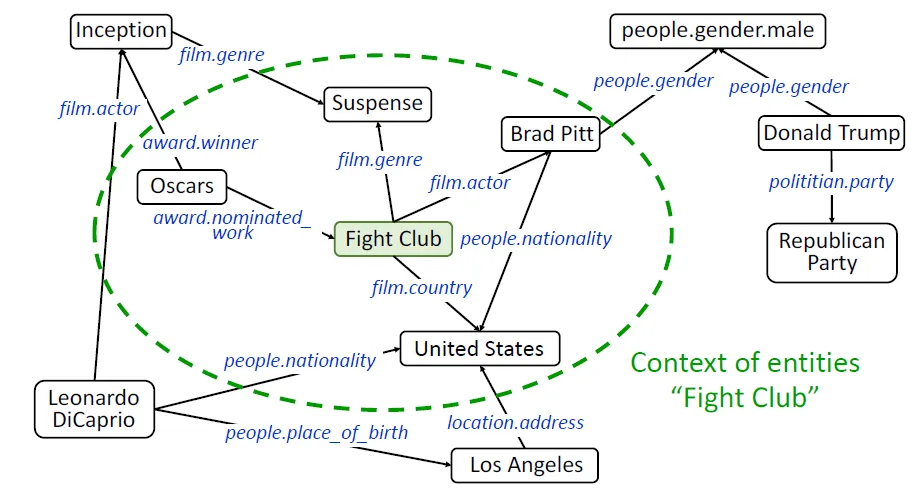
MuJoCo 专用的世界描述语言(MJCF),定义了世界(重力、地板、灯光)、机械臂本体、夹爪与物体等机械臂核心类:负责计算机械臂该怎么动。逆运动学(IK - solve_ik_pose):这是机器人学最经典的问题。你告诉机械臂“手要去桌面上坐标 (0.4, 0.1, 0.03) 的位置抓东西”,代码会通过雅可比矩阵数学计算,反推算出它的 6个关节电机分别需要转动多少度 才能正好把手伸到那里。动作
Codex & Codex CLICodex Cli、对标 Claude Code适合:喜欢命令行、自动化脚本、批量处理任务。特点:轻量、快速、可集成 CI/CD。✅ 在您的 IDE 中尝试支持 VS Code、Cursor、Windsurf 等。特点:图形界面友好,适合日常开发、边写边问。适合:喜欢命令行、自动化脚本、批量处理任务。特点:轻量、快速、可集成 CI/CD。✅ 在您的 IDE 中尝试

AutoGen 将复杂的协作抽象为一场由多角色参与的、可自动进行的“群聊”,其核心在于“以对话驱动协作”。AgentScope 则着眼于工业级应用的健壮性与可扩展性,为构建高并发、分布式的多智能体系统提供了坚实的工程基础。CAMEL 以其轻量级的“角色扮演”和“引导性提示”范式,展示了如何用最少的代码激发两个专家智能体之间深度、自主的协作。LangGraph 则回归到更底层的“状态机”模型,通过显
一、openclaw用于表格分析二、领域openclaw skills三、openclaw安全四、生成学术海报五、OpenClaw Medical Skills六、论文自动生成七、搜索AI Search Hub八、自动分析论文九、使用RL增强OpenClaw能力十、openclaw记忆项目十一、相关厂商clawReference一、openclaw用于表格分析【openclaw用于表格分析项目】基
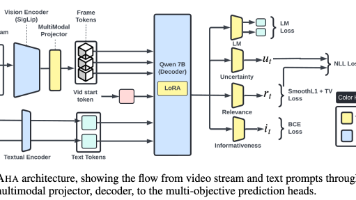
AHA首次实现了严格因果约束下的在线视频高亮检测,通过轻量解耦头、任务聚焦的动态记忆和抗干扰训练,在零样本和全监督设置下均超越离线方法,为机器人、无人机等实时智能体提供了“边看边懂”的新范式。文章目录note一、研究动机现实需求现有方法的致命缺陷二、AHA框架:核心设计思想1. 三大预测头 —— 各司其职2. 动态SinkCache —— 恒定内存的秘诀3. 不确定性感知评分函数4. 抗退化训练(
Yolov8提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺

文章目录零、基础铺垫一、batch normalization二、layer normalization三、应用场景Reference零、基础铺垫“独立同分布”的数据能让人很快地发觉数据之间的关系,因为不会出现像过拟合等问题。一般在模型训练之前,需要对数据做归一化。为了解决ICS问题,即internal covarivate shift(内部协变量漂移)问题,即数据分布会发生变化,对下一层网络的学

主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。 PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。在介绍PCA的原理之前需要回顾涉及到的相关术语:• 方差:各个样本和样本均值的差的平方和的均值,用来度量一组数据的...
学习总结(1)这个task所有求导布局都是分母布局。为了适配矩阵对矩阵的求导,这次的向量对向量的求导,也是以分母布局为准(和之前的不一样)。(2)由于矩阵对矩阵求导的结果包含【克罗内克积】,因此和之前我们讲到的其他类型的矩阵求导很不同,在机器学习算法优化中中,我们一般不在推导的时候使用矩阵对矩阵的求导,除非只是做定性的分析。如果遇到矩阵对矩阵的求导不好绕过,一般可以使用机器学习中的矩阵向量求导(四

两个常见的推荐模块:1)猜你喜欢:各种召回方法,多路召回策略。2)个性推荐:CTR排序,主流是基于深度学习方法,如下图所示:- 一般先用spark进行大数据处理和特征工程,得到的线上特征存入redis;训练样本则送入TensorFlow进行离线模型训练(一些模型可以用spark进行模型训练);- 训练并导出了 如NeuralCF 的模型文件。然后使用 TensorFlow Serving 载入模型