




- @qq_38563206
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2026年北京亦庄人形机器人半程马拉松赛事成为全球具身智能领域里程碑。赛事规模较2025年扩大5倍,吸引300余台机器人参赛,冠军"闪电"机器人以50分26秒打破人类纪录。核心技术突破包括液冷散热系统、高扭矩电机和高密度电池,推动自主导航占比提升至38%。赛事通过创新规则设计(如1.2倍加权系数)引导技术路线,促进产学研协同和供应链成熟。中国在标准制定和产业化方面取得领先,荣耀

我们有时候在生成较大的图谱时,会产生大量的节点以及与之关联的关系,可能会遇到' 由于初始节点显示设置, 并非所有返回节点都被显示. 仅显示 300 个节点中的 300 个 '上述问题。即便我们在代码段中已经设置了MATCH (n) RETURN n LIMIT 10000这是由于neo4j图数据库本身的初始化设置导致的问题在设置里进行修改即可原参数为300,100,1000,上述为自行设置此时再执
阿里巴巴通义千问团队推出的Qwen3-VL-8B-Instruct是一款80亿参数的开源视觉语言模型,采用Dense架构设计,通过交错MRoPE位置编码、DeepStack特征融合和文本-时间戳对齐三项技术创新,在32项评测中超越Gemini 2.5Pro等闭源模型。该模型支持256K token长上下文,具备精准的工业质检(91.3%准确率)、视频事件定位(96.8%准确率)和医疗诊断能力,同时
本文系统探讨了AI语音交互的三大核心技术:语音活动检测(VAD)、回声消除和降噪。VAD作为"触发器"准确识别语音段,回声消除解决设备间的声学干扰,降噪技术提升语音清晰度。三项技术协同工作形成完整音频处理流水线,在远场交互、医疗记录等场景中显著提升系统性能。研究指出,未来技术将向轻量化模型、多模态融合和自适应学习方向发展,结合边缘计算和专用硬件加速,为智能家居、车载系统等应用场
可能是在本机windows下使用pycharm,由于内部的各自系统路径限制导致无法在pycharm的命令行终端中成功创建项目。如果,还是想直接在pycharm中执行各种相关命令,可以尝试解决本机pycharm中的python运行环境问题,可参考以下。django的确已经安装。可导入输出其版本信息,执行命令的位置也不存在问题,命令输入无误。可以尝试在Anaconda中自带的Anaconda Prom

但此时你已经将训练好的模型及模型代码放置在指定路径中,为了django的views或者你的predict函数调用,那么这是为什么呢?在实际生产中,我们往往会将训练好的深度学习模型作为Web系统的后端用于构建系统,在这个过程中可能会出现一个问题,例如我们的模型名称为“方法读取模型的参数,此时你就会发现成功读取了模型及参数,并且可以完成predict操作或views调用。,例如你读取模型结构后赋值变量
我们有时候在生成较大的图谱时,会产生大量的节点以及与之关联的关系,可能会遇到' 由于初始节点显示设置, 并非所有返回节点都被显示. 仅显示 300 个节点中的 300 个 '上述问题。即便我们在代码段中已经设置了MATCH (n) RETURN n LIMIT 10000这是由于neo4j图数据库本身的初始化设置导致的问题在设置里进行修改即可原参数为300,100,1000,上述为自行设置此时再执
计算机视觉及图像处理领域会议,CCF推荐(A类,B类,C类)
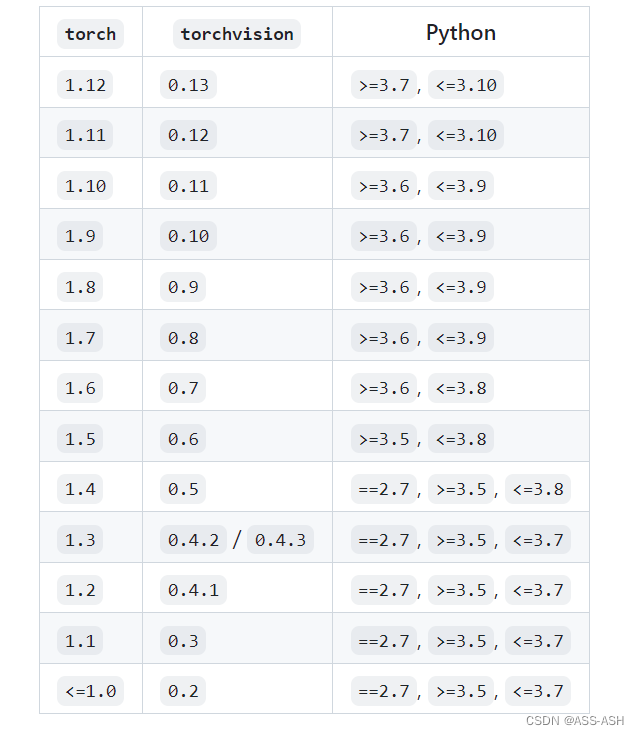
随着python语言和pytorch框架的更新,torch\torchvision\torchaudio与python之间的版本对应关系也在不断地更新。torch与torchvision。torch与torchvision。torch与torchaudio。
2026年北京亦庄人形机器人半程马拉松赛事成为全球具身智能领域里程碑。赛事规模较2025年扩大5倍,吸引300余台机器人参赛,冠军"闪电"机器人以50分26秒打破人类纪录。核心技术突破包括液冷散热系统、高扭矩电机和高密度电池,推动自主导航占比提升至38%。赛事通过创新规则设计(如1.2倍加权系数)引导技术路线,促进产学研协同和供应链成熟。中国在标准制定和产业化方面取得领先,荣耀