




- @qq128252
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
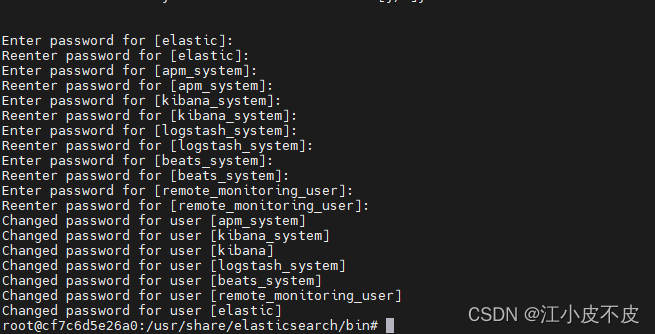
docker 安装elasticserch8系列,用于充当向量数据库。由于需要安装elasticsearch、IK分词插件、kibana。所以需要保持这三者的版本一致性。
在现代应用程序开发中,数据库是存储和管理数据的核心组件。Python 作为一种强大的编程语言,提供了多种库来连接和操作数据库。本文介绍了如何使用 pymysql 库连接到 MySQL 或 Apache Doris 数据库。首先,本文概述了数据库连接的基本步骤,包括建立连接、执行查询、处理结果和关闭连接。然后,详细讲解了使用 pymysql 库的代码示例,展示了如何通过 Python 程序实现与数据

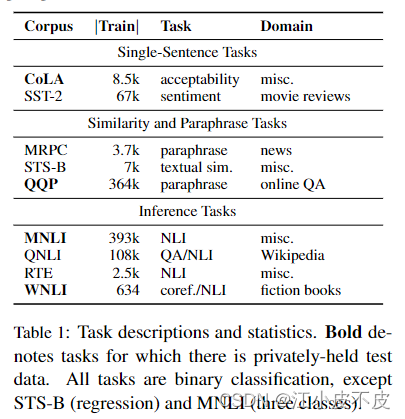
当前大多数以上词级别的NLU模型都是针对特定任务设计的,而针对各种任务都能执行的通用模型尚未实现。为了解决这个问题,作者提出了GLUE,希望通过这个评测平台促进通用NLU系统的发展。斯坦福问答数据集(SQuAD),这是一个由众包工作者在维基百科文章上提出的10万多个问题的阅读理解数据集,每个问题的答案都是相应阅读段落的一部分文本。SQuAD数据集的构建分为三个阶段:1. 筛选文章;2. 通过众包的
继美团发布YOLOV6之后,YOLO系列原作者也发布了YOLOV7。YOLOV7主要的贡献在于:1.模型重参数化YOLOV7将模型重参数化引入到网络架构中,重参数化这一思想最早出现于REPVGG中。2.标签分配策略YOLOV7的标签分配策略采用的是YOLOV5的跨网格搜索,以及YOLOX的匹配策略。3.ELAN高效网络架构YOLOV7中提出的一个新的网络架构,以高效为主。4.带辅助头的训练。

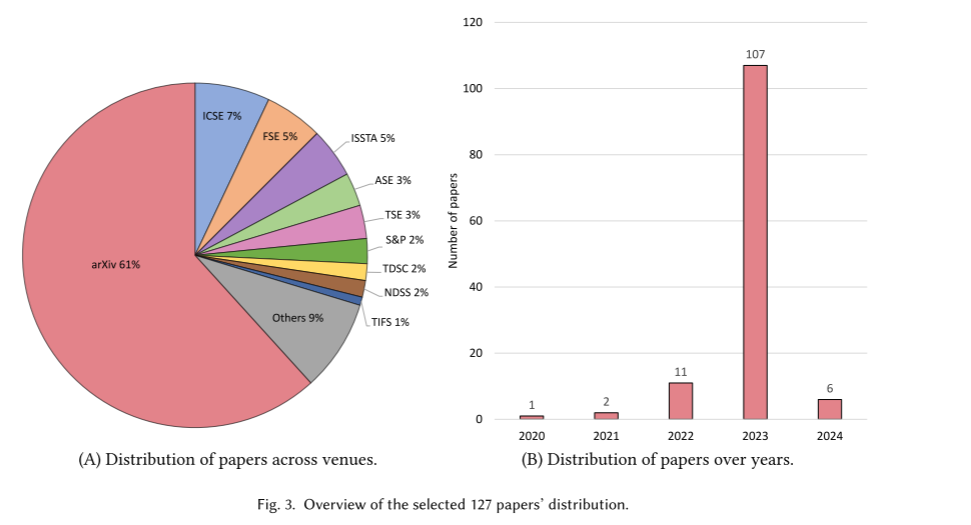
得益于大型语言模型(LLMs)的突破性进展,自然语言处理(NLP)在过去十年间实现了飞速发展。LLMs 正逐渐成为网络安全领域的一股强大力量,它们能够自动检测漏洞、分析恶意软件,并有效应对日益复杂的网络攻击。具体而言,LLMs 被广泛应用于软件安全领域,可从代码和自然语言描述中识别漏洞,并生成相应的安全补丁。同时,LLMs 也被用于分析安全策略和隐私政策,帮助识别潜在的安全违规行为。在网络安全领域
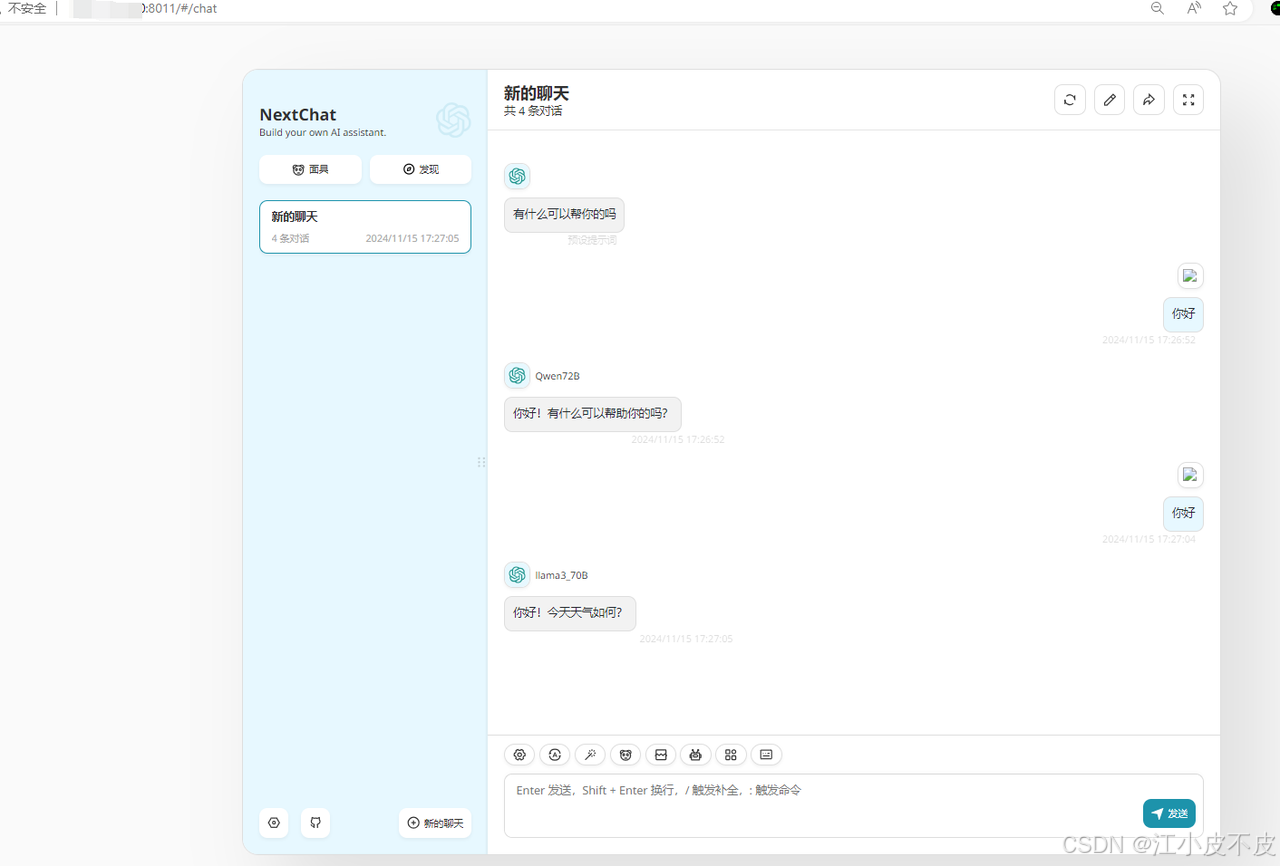
本文讨论了如何使用 VLLM、OneAPI 和 ChatGPT-Next-Web 打造私有化的聊天大模型。首先介绍了 VLLM 的关键技术和部署方法,包括内存优化、推理加速、模型量化等,以及通过 docker 镜像进行部署和启动服务。接着阐述了 OneAPI 的概述、部署过程,包括启动镜像、登录、添加 API、测试渠道、添加令牌和使用服务等步骤。最后说明了 ChatGPT-Next-Web 的概述
当前大多数以上词级别的NLU模型都是针对特定任务设计的,而针对各种任务都能执行的通用模型尚未实现。为了解决这个问题,作者提出了GLUE,希望通过这个评测平台促进通用NLU系统的发展。斯坦福问答数据集(SQuAD),这是一个由众包工作者在维基百科文章上提出的10万多个问题的阅读理解数据集,每个问题的答案都是相应阅读段落的一部分文本。SQuAD数据集的构建分为三个阶段:1. 筛选文章;2. 通过众包的
大海捞针测试通过在长文本中随机插入关键信息,形成大型语言模型(LLM)的Prompt。该测试旨在检测大型模型能否从长文本中提取出这些关键信息,从而评估模型处理长文本信息提取的能力数星星测试通过两个任务评估LLMs的长上下文能力:多证据获取和多证据推理。实验使用了多种长文本数据,中文版本使用《红楼梦》,英文版本使用Paul Graham的文章作为长文本。

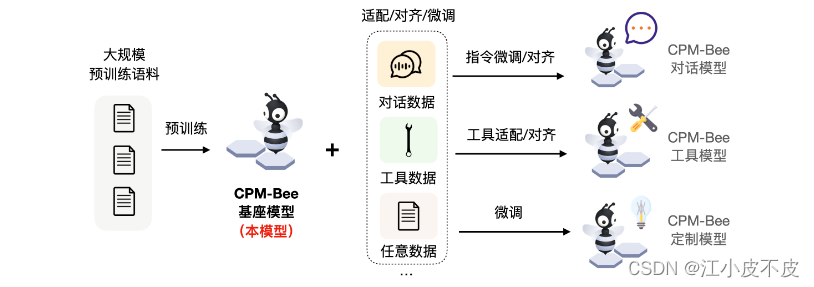
CPM-Bee是一个完全开源、允许商用的百亿参数中英文基座模型,也是CPM-Live训练的第二个里程碑。它采用Transformer自回归架构(auto-regressive),在超万亿(trillion)高质量语料上进行预训练,拥有强大的基础能力。开发者和研究者可以在CPM-Bee基座模型的基础上在各类场景进行适配来以创建特定领域的应用模型。
solver只能选择liblinear,因为l1正则化损失函数不是连续可导的,而其他三种都是需要二阶导数。L1:预测效果差、模型特征多,需要让一些不重要的特征系数归零,从而让模型稀疏化。若class__weight 和 sample_weight都使用,权重就是。balance:根据数据量自动分配,样本量越多,权重越低。samme.r:(默认)样本集预测错误的比例进行划分。自定义权重比例:{0:0