




- @weixin_46034279
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
神经网络调参是深度学习中不可或缺的一环,它直接影响着模型的性能和泛化能力。当前神经网络模型应用到机器学习时仍有一些问题,主要包括两大类。优化问题深度神经网络优化十分困难。首先他的损失函数是一个非凸函数,找到局部最优解容易,但找到全局最优解并非容易。其次,神经网络参数非常多,训练数据很大,所以无法使用计算代价很高的二阶优化方法。最后,神经网络存在梯度消失或爆炸问题。泛化问题由于神经网络复杂度很高,拟
BLEU优点:计算速度,适合评估机器翻译等文本生成任务的准确性。依赖于 n-gram 匹配,所以对短文本评价友好缺点:无法衡量语义,容易惩罚语义合理的表示;对自由度较高的生成任务表现不佳使用场景:机器翻译、文本摘要,尤其是目标文本相对固定的情形ROUGE优点:对文本摘要任务适用,尤其是 ROUGE-L 可识别长的匹配序列,适合评估摘要生成中较长的语义片段缺点:依赖表层匹配,缺乏对语义的深层次理解使

并没有对应的词向量文件,看来还需要对这些词进行词嵌入训练,还是用fasttext好了。30之后连同嵌入层一起微调10轮,准确率又上去了一个百分点。生成了两个文件,一个是模型文件,一个是词表文件。id 和 词向量都有了,可以构造词嵌入矩阵了。训练(我弄的是12800 词汇表大小)酒店评论数据集,处理成每行一句的形式。效果:基本收敛到了 96%

大型语言模型(LLM)的高吞吐量服务需要一次处理足够多的请求。然而,现有的系统很难做到这一点,因为每个请求的键值缓存(KV 缓存)内存都很大,并且动态地增长和收缩。当管理效率低下时,碎片和冗余复制会严重浪费此内存,从而限制批处理大小。为了解决这个问题,我们提出了,这个注意力算法的灵感来自经典的虚拟内存和操作系统中的分页技术。在此基础上,我们构建了 vLLM,这是一个 LLM 服务系统,它实现了(1

LLaMA-Factory 支持多种推理方式。您可以使用或进行推理与模型对话。对话时配置文件只需指定原始模型和template,并根据是否是微调模型指定和。如果您希望向模型输入大量数据集并记录推理输出,您可以使用使用数据集或使用 api 进行批量推理。Note:使用任何方式推理时,模型需要存在且与template相对应。
手动的离散提示通常导致一个不稳定的性能——比如,在提示中改变一个词可能导致性能大幅度下降。于是提出了新颖的方法 —— P-Tuning,它采用连续的提示 embedding 与离散提示 结合在一起。P-Tuning 不仅能够通过最小化各种离散提示之间的差距来稳定训练,还能在很多基准测试中提高性能。预训练模型一般都可以通过手动编写提示模版进一步的提升性能。但是,手动的离散提示有很大程度的不稳定性。如

LLaMA-Factory 支持多种调优算法,包括:。
作者们探讨了如何通过加性量化(Additive Quantization, AQ)方法实现大型语言模型(LLMs)的极端压缩,目标是将模型的比特数压缩到每个参数仅2到3比特。图 1:在 LLAMA2 的 7, 13 和 70B 模型上,AQLM(2 位)相对于最先进的 QuIP#(2 位)和原始 16 位权重的比较。大模型的参数量通常达到数十亿级别,需要大量的计算和存储资源。本文证明,通过我们提出

【代码】大模型开发和微调工具Llama-Factory-->安装。

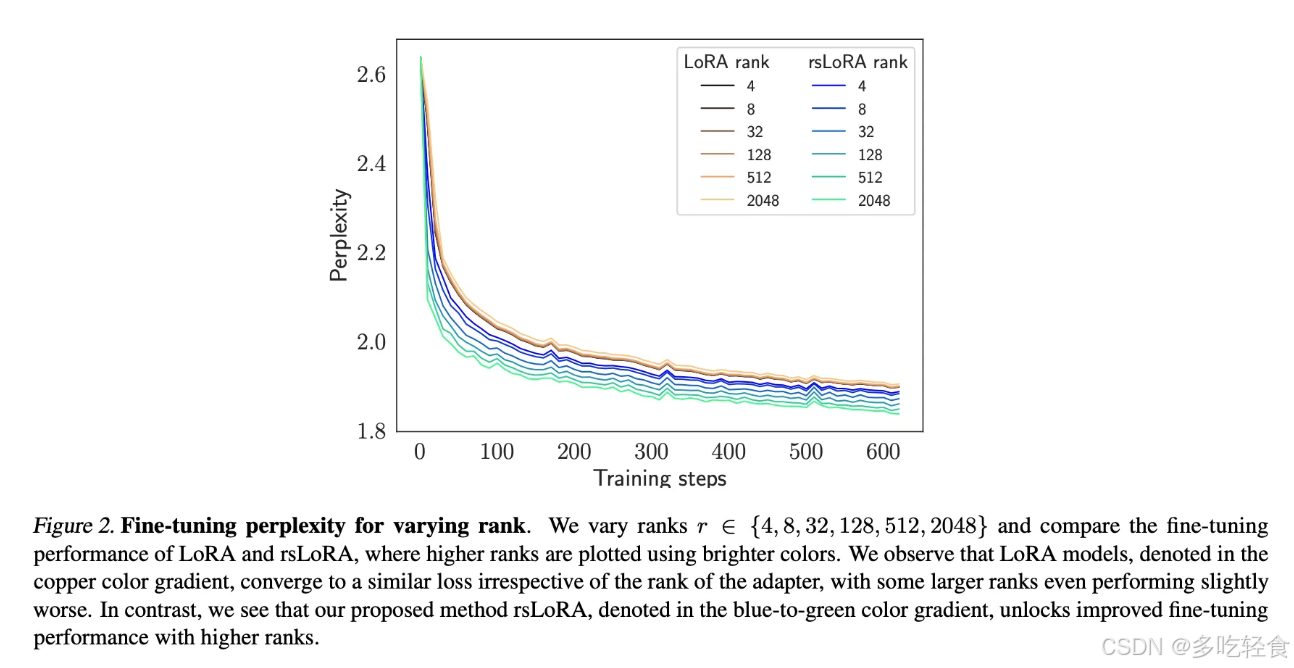
"r": 8,# 起始rank"alpha": 8,# 与rank相同"dropout": 0.1,# 默认dropout"target_modules": ["q_proj", "v_proj"]# 基础配置Step 1: 先固定其他参数,调整 rank 和 alphaStep 2: 确定最优 rank 后,可以尝试增加 target modulesStep 3: 如果还不够好,可以调整 dro
