




- @uncle_ll
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深入探讨了LangChain框架的高级自定义能力,帮助企业应对复杂LLM应用场景。主要内容包括: 回调系统核心:详解LangChain全链路事件监听机制,覆盖模型调用、链式执行、工具调用等全生命周期事件,提供完整的回调事件清单和处理方法。 两种回调注入方式:比较构造函数回调(全局生效)和运行时请求回调(单次生效)的特点与适用场景。 实战案例:通过自定义日志回调类和流式Token输出示例,展示如
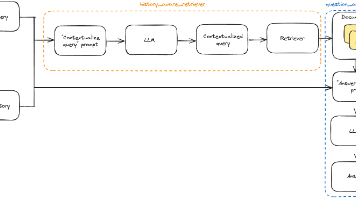
uvuv是 Python 开发者的新宠,它以Rust 的性能优势和现代化设计,解决了传统工具的痛点。如果你专注于 Python 生态,追求速度和轻量化,uv是理想选择;而conda仍然是科学计算领域的全能选手。根据项目需求选择合适的工具,才能事半功倍!
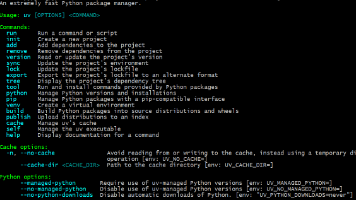
本文介绍了如何利用阿里通义千问API结合LangChain和LlamaIndex框架搭建RAG系统,特别适合零基础开发者。主要内容包括:1)通过Conda创建虚拟环境;2)配置通义千问API密钥;3)使用LangChain实现完整RAG流程,包括文档加载、文本分块、向量索引构建、文档检索和答案生成;4)详细解析了代码实现和参数配置,并提供了运行验证方法。该方案具有成本低(免费API额度)、配置简单
数据加载是RAG系统的关键第一步,直接影响后续流程质量。本文对比了PyMuPDF4LLM、Unstructured等主流文档加载工具,重点解析Unstructured库的多格式支持与智能内容解析能力。通过代码示例演示了如何加载PDF文档并统计元素类型,比较了不同解析策略的适用场景。最后提供常见问题处理方案,强调数据质量对系统性能的决定性作用。
本文详细介绍了在Python 3.10环境下安装Sherpa语音处理工具集的完整流程。主要内容包括:系统环境配置(推荐Ubuntu/CentOS系统)、虚拟环境创建、核心组件(PyTorch 2.5.0、k2、kaldifeat等)的安装方法与版本匹配技巧,以及Sherpa-ONNX轻量推理引擎的部署。文章还提供了安装验证方法和TTS语音合成示例,帮助用户快速测试功能。整个安装过程强调版本兼容性,
摘要:本文探讨了检索增强生成(RAG)系统中的索引优化策略。通过LlamaIndex工具,提出两种核心方法:1)句子窗口检索技术,在保证检索精度的同时扩展上下文,解决信息碎片化问题;2)结构化索引方案,提升大规模知识库的检索效率。实验表明,相比传统方法,优化后的索引策略能显著提高回答的准确性和完整性。文章包含具体代码实现和技术细节,为开发者提供生产级解决方案。
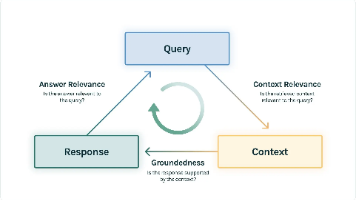
摘要: 检索增强生成(RAG)技术已成为企业级AI应用的核心方案,但其落地效果依赖科学评估。本文提出基于RAG三元组的评估框架,从上下文相关性(检索质量)、忠实度(生成可靠性)、答案相关性(用户价值)三个维度构建全链路评估体系。通过分层评估(检索评估聚焦精确率/召回率等指标,响应评估量化端到端表现)精准定位问题根源,如检索噪声或生成幻觉。该框架为开发者提供标准化评估方法,确保RAG系统在金融、医疗
本文全面介绍OpenAI API开发的核心要点,涵盖Token计费机制、API参数调优、两种主流调用方式及高阶开发技巧。首先解析Token作为计费单元和文本处理最小单位的重要性,提供实用换算公式和统计方法。其次详解六大核心参数的作用与调优建议,包括响应长度控制、输出随机性调节等。文章对比REST API原生调用和官方SDK调用两种方式,提供完整可运行代码示例。最后分享JSON模式、流式响应等进阶技
原文地址:https://yq.aliyun.com/articles/65158?spm=5176.8091938.0.0.3Wl7HH 摘要: 针对Kaggle保险索赔竞赛给定的数据集,本文详细介绍了如何利用python对数据集进行分析并对特种进行预处理操作。以保险索赔竞赛案例和详细的操作步骤,生动形象的讲解了自动预测保险索赔的算法流程。本文由北邮@爱可可-爱生活 老师推荐,...
目标在本章中,将学习使用分水岭算法实现基于标记的图像分割函数:cv2.watershed()理论任何灰度图像都可以看作是一个地形表面,其中高强度的像素表示山峰,低强度表示山谷。可以用不同颜色的水(标签)填充每个孤立的山谷(局部最小值)。随着水位的上升,根据附近的山峰(坡度),来自不同山谷的水明显会开始合并,颜色也不同。为了避免这种情况,要在水融合的地方建造屏障。继续填满水,建造障碍,直到所有的山峰