




- @verse_armour
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
关于机器学习中的梯度下降和正规方程。
【代码】三种目标检测数据集格式对比:PASCAL VOC 格式、 COCO 格式、YOLO 格式。
注意必须安装 Git LFS,否则大文件只能下到指针文件。操作比较简单,但是一般来说比较慢,网络不好的时候容易下载中断,又要重新下载。以下是详细的下载指南,以及国内用户最常遇到的“网络连接”等问题的解决方案。下载 Hugging Face 数据集时,90% 的问题都集中在。适用场景: 习惯用 Git 管理、需要查看历史版本的用户。这个方案是我下来最流畅的一个,没有遇到问题。适用场景: 下载原始文件
卷积层、池化层、非线性激活函数代码示例
动态规划——找零问题
量子计算目前受到噪声的严重影响,特别是双量子比特门带来的噪声。在噪声中等规模量子硬件上,减少双量子比特门数量至关重要。我们提出了基于ZX演算、图神经网络和强化学习的量子电路优化框架。通过结合强化学习与树搜索,我们的方法解决了选择最优ZX演算重写规则序列的挑战。我们的方法训练了直接在ZX图上操作的强化学习策略,能够发现任意优化规则,显著减少CNOT门数量。实验表明该方法与最先进电路优化器竞争力相当,

world_size(进程总数):在分布式训练或并行计算任务中,world_size表示总共有多少个进程参与计算。每个进程通常运行在不同的CPU核心、GPU或整个计算节点上。4.将数据加载器train_dataloader与train_sampler相结合。Shell 脚本可以自动化任务,使得重复性的工作可以快速、一致地完成。2.在获取训练数据集后,设置train_sampler。3.定义模型后,
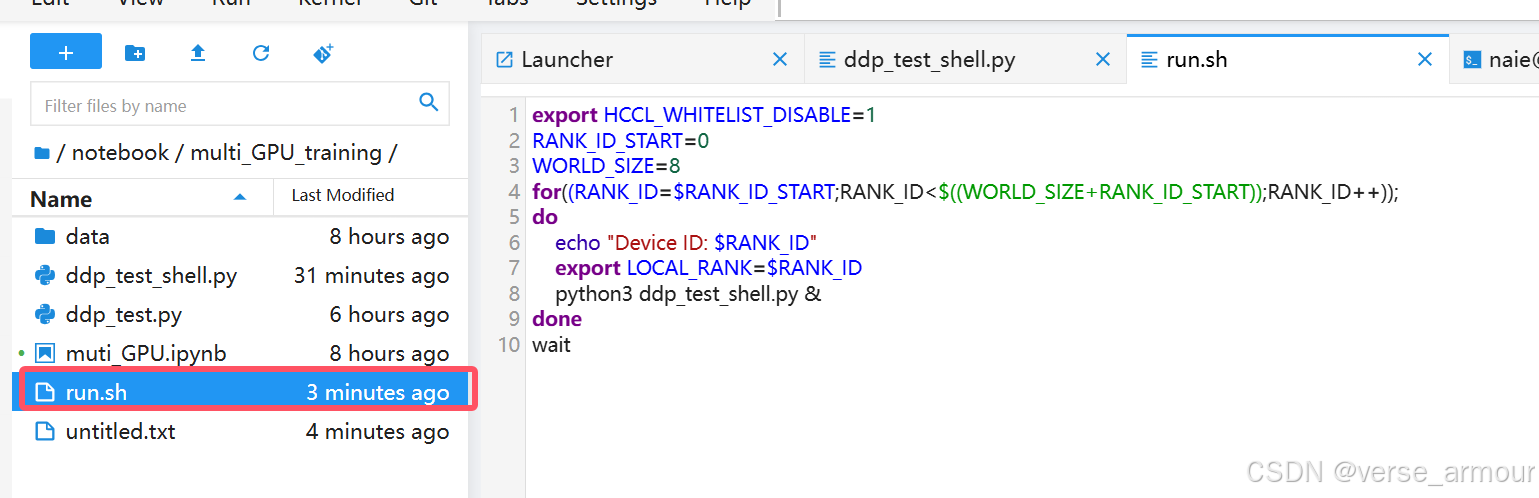
解决办法:如果是运行单卡模式,在训练脚本中加入export ASCEND_RT_VISIBLE_DEVICES=0(指定 0 号卡对当前进程可见)。PRETTY_NAME:操作系统的友好名称,通常用于显示。VERSION_ID:操作系统的版本号,通常是一个数字。ID_LIKE:操作系统所属的家族或类似的操作系统。BUG_REPORT_URL:报告错误的 URL。HOME_URL:操作系统的官方网站

在多进程环境中,数据共享是一个挑战。torch.multiprocessing 允许在进程之间共享 PyTorch 张量,这些张量存储在共享内存中,而不是在进程之间复制数据。DDP通过在每个进程中创建模型的一个副本,并在每个副本上独立地进行前向和反向传播,从而实现并行计算。在每个训练步骤后,DDP自动同步各个进程计算出的梯度,确保所有进程的模型参数保持一致。这个采样器的设计目的是确保在分布式训练过
