登录社区云,与社区用户共同成长
邀请您加入社区
为遵守国家网络实名制规定,未绑定将限制内容发布与互动
这对公司来说是降本提效。对打工人来说,就是岗位边界变窄,能力要求变宽。前端不会消失,但“只会写页面的前端”会越来越难。不是测试不重要了,而是纯手工、纯流程型岗位会被压缩。美团 CLC 食杂零售 Keemart 研发团队,前端和后端团队合并。京东创新零售业务,前端部门并入服务端,推全员全栈。但只会前端,可能不太够了。我是在脉脉看到这个讨论的,评论区不少前端、后端、测试都在聊岗位变化。以前是前端只管页
它的“身体”来自魔珐星云,“大脑”则可以自由接入DeepSeek、豆包、Kimi等任何你喜欢的LLM。首先,在您的HTML页面中,需要创建一个用于承载数字人的DOM容器。AI的下一个时代,是具身交互的时代。输入你好,等待回复后继续 输入:这里有什么好玩、这里有什么好吃的、我的症状是发热,中的任意一个,等待回复后继续。你有没有想过,和你对话的AI,不再是一个冰冷的文字框,而是一个会说话、有表情、能打
摘要 本文深入解析AI Agent的Function Calling交互原理,通过时序图拆解核心流程,涵盖用户提问、模型决策、函数执行与结果回传。核心角色包括用户、AI应用和基础大模型,通过ReAct架构实现自主决策循环。生活化类比(如餐厅点餐)帮助理解流程,并提供Python和Java双语言代码实战,展示如何注册工具、定义Function Schema及实现Agent逻辑。文章还总结了生产环境中
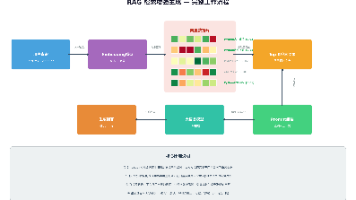
在RAG系统的架构中,文档分割器(Document Splitter)承担着"承上启下"的核心角色。当一份长篇文档(如PDF、Word、Markdown)被加载后,我们需要将其切割成语义完整、长度适中的小片段(Chunk),再送入向量数据库进行Embedding存储。分割质量直接决定检索精度:切得太碎会丢失上下文,切得太长会超出模型Token限制,切的边界不对会破坏语义连贯性。
文章摘要 作者分享了自己从后端开发转向Agent开发的经历,通过开发基于RAG的问答机器人和接入智谱GLM等国产大模型,发现用户对聊天机器人交互体验的感知有限,往往只将其视为简单的聊天框。为提升线下场景体验,作者利用魔珐星云平台为国产大模型添加具身交互能力,开发了一个3D数字人导购Demo。该Demo整合了模型理解、工具调用和实时表达,解决了多技术栈协同、交互延迟和打断响应等难点,展示了AI在门店
想副业赚到钱的朋友们,今天一定要看看漫剧这个赛道。有些人一直在不停换副业,无法长期坚持,核心问题有两个:一个是没利润,大家都在做,高度内卷;二是投入成本高,费时费力,甚至需要一定的前期资金。而漫剧刚好能解决这两大痛点。一是赛道有红利,行业内仍然有增量空间(当然,你不能犹豫,下手要快);二是投入成本低,利用 AI 工具,你不用会画画、不用会剧本,更不用真人出境,一个人就能完成从选题策划到成片输出再到
摘要: RAG(检索增强生成)通过结合外部知识检索与大模型生成能力,解决了传统LLM的知识时效性、领域专业性和幻觉问题。其核心流程包括:用户查询输入→Embedding编码→向量检索→结果召回与重排序→Prompt组装→LLM生成。关键技术涉及Embedding模型选型(如OpenAI、BGE)、向量数据库(如Milvus、Pinecone)及相似度算法(如余弦相似度)。RAG架构经历了从朴素RA
摘要:视频介绍了基于亮数据 Bright Data SERP API 的 Google 多场景数据采集实操(包括 Maps、Trends 和 AI Overview)。用户可通过专属链接注册,免费使用 MCP 并获得 25 美元试用金,适用于 AI 开发者、数据工程师及创业团队测试项目需求。官方推荐关注 CSDN 技术博客、GitHub 中文区和知乎机构号获取最新技术动态与福利。
亮数据browser api :项目迁移更适合的方式。
● 如果你做博弈论或多智能体强化学习研究,需要可运行代码来验证论文算法,全书覆盖的支撑枚举法、虚拟对弈、CFR、DQN、PPO、QMIX、MAPPO、蒙特卡洛树搜索(MCTS)、策略空间响应预言(PSRO)均可直接参考。● 如果你正在做自动驾驶或多机器人协作,策略训练不收敛或协作效果差,建议从第22章开始补深度强化学习基础,然后进入第23~26章的多智能体算法,重点看VDN、QMIX和多智能体近端