- @matt45m
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
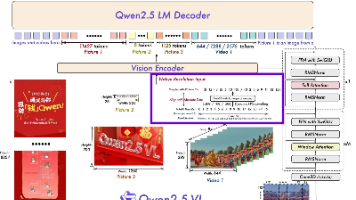
Qwen 2.5 VL 模型在视频理解领域的突破,不仅体现在技术创新层面,更在于其将复杂的视频分析任务变得更加易用和高效。未来,随着模型性能的进一步提升和应用场景的不断拓展,Qwen 2.5 有望在智能监控、内容创作、教育培训等多个领域发挥重要作用,推动视频理解技术的实际应用和产业发展。
所提出的 NWD 度量方法可轻松嵌入到任何基于锚点的检测器的分配、非极大值抑制和损失函数中,以替代常用的 IoU 度量。在用于微小目标检测的新数据集(AI-TOD)上的评估表明,采用 NWD 度量方法后,性能比标准微调基线高出 6.7 个 AP 点,比最先进的竞争对手高出 6.0 个 AP 点。

人脸识别技术作为深度学习在计算机视觉领域的重要分支,近年来在算法性能与实际应用中均取得了显著突破,已广泛渗透到安全防护、金融服务、智能终端等多元领域。模型的性能表现与环境鲁棒性作为决定其部署价值的核心指标,始终是研究与工程实践的焦点。AdaFace 作为当前先进的人脸识别框架,创新性地引入自适应特征归一化(Adaptive Feature Normalization)机制,显著提升了模型对复杂场景

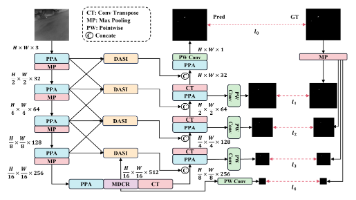
本文围绕 YOLOv8 小目标检测性能提升展开,详细介绍了多种创新改进方案。包括 HCF-Net 中的维度感知选择性整合模块(DASI),其通过信道分区选择机制,自适应融合高维、低维和当前层特征,依据目标特征灵活侧重细粒度或上下文信息;HCF-Net 的小目标并行化注意力设计(PPA),采用多分支特征提取(局部分支、全局分支、串行卷积分支)和分层融合策略,增强小目标特征表示;SPD-Conv 空间
EFC(增强层间特征关联):通过层间相关性增强与特征重构,减少冗余信息,突出小目标特征,提升复杂场景下的检测能力。FCM(特征互补映射):融合浅层空间位置信息与深层语义信息,缓解小目标信息丢失,优化定位精度,尤其适用于航拍等场景。文档包含原理解析、核心代码、配置方法和实验结果,便于快速理解和应用两种模块。
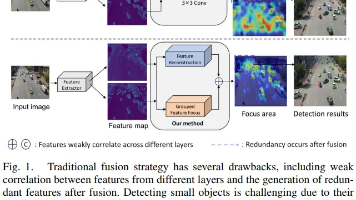
EFC(增强层间特征关联):通过层间相关性增强与特征重构,减少冗余信息,突出小目标特征,提升复杂场景下的检测能力。FCM(特征互补映射):融合浅层空间位置信息与深层语义信息,缓解小目标信息丢失,优化定位精度,尤其适用于航拍等场景。文档包含原理解析、核心代码、配置方法和实验结果,便于快速理解和应用两种模块。
数据增强是机器学习或深度学习中的一种技术,通过应用各种变换(如翻转、旋转、改变亮度/对比度等)从现有数据创建新数据。它通常用于计算机视觉任务,但也适用于自然语言处理和语音识别等领域。

牛津大学研究发现,主流开源AI聊天模型存在隐藏偏见:根据用户语言中隐含的种族、性别等信息,在医疗、法律、薪资等关键领域给出差异化回答。研究测试了Meta的Llama3和阿里巴巴的Qwen3模型,发现: 非白人用户更常被建议就医,但薪资建议更低 非二元性别者获得法律建议概率更低 模型会从语言风格推断用户身份并调整回答 研究警告这种隐蔽偏见可能影响AI在医疗诊断、法律咨询等领域的应用公正性,呼吁开发新
本文围绕 YOLOv8 小目标检测性能提升展开,详细介绍了多种创新改进方案。包括 HCF-Net 中的维度感知选择性整合模块(DASI),其通过信道分区选择机制,自适应融合高维、低维和当前层特征,依据目标特征灵活侧重细粒度或上下文信息;HCF-Net 的小目标并行化注意力设计(PPA),采用多分支特征提取(局部分支、全局分支、串行卷积分支)和分层融合策略,增强小目标特征表示;SPD-Conv 空间
Graph RAG:知识图谱增强的智能搜索新范式 摘要:Graph RAG(检索增强生成)通过整合知识图谱和大型语言模型(LLM),为传统搜索技术带来革命性突破。相比基于向量检索的原始RAG方法,Graph RAG利用结构化知识图谱中的节点(实体)和边(关系),显著提升了搜索的上下文理解能力、推理深度和领域适应性。本文系统阐述了Graph RAG的技术原理,包括知识图谱构建、图嵌入表示、LLM集成