- @weixin_41338279
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1)Apps SDK:与外部应用无缝集成,把 ChatGPT 打造成未来的操作系统;2)AgentKit:无需编码,拖放搭建智能体。人人都可快速开发智能体,还能评估智能体能力;3)Codex 全面可用:不写一行代码,打造爆款 APP;4)API 更新:三大 API 更新,Sora 2 API 同步上线。

本文记录一个因 ~/.docker/config.json 代理配置不当,导致 Docker Compose 容器间无法通过服务名互访的隐蔽问题。包含根因分析、解决方案和最佳实践,3 分钟帮你排雷避坑。
随着 TPU v6 (Trillium) 的发布、Apple Intelligence 官宣使用 TPU 训练、以及传闻中 Meta 等巨头开始与谷歌洽谈算力合作,谷歌的策略已明显从“自用为主”转向“激进的算力市场争夺者”。这篇深度报告将为你拆解谷歌 TPU 的最新技术进展(v5p与Trillium v6)、针对英伟达的“非对称打击”策略,以及其商业布局的真实意图。
2025年12月5日,摩尔线程(688795.SH)正式登陆上海证券交易所科创板,作为国内GPU领域的领军企业之一,其上市不仅为公司发展注入强大资本,也标志着国产GPU和AI算力赛道迎来一个重要的里程碑。本文将从公司的核心竞争力、行业机遇与挑战出发,为您提供具备前瞻性的投资分析与建议。
在使用 Dify 的 Custom Tool(自定义工具)功能调用外部 API 时,你是否遇到过这样的问题:- 工具调用反复重试,日志中出现多次相同请求- API 明明执行成功了,但 Dify 显示超时失败- 复杂的 AI 处理流程总是在中途断开如果你正在被这些问题困扰,这篇文章将帮你彻底解决!
prompt: hi 聪明可靠的gemini,请写一篇言简意赅、专业详细的关于eBPF和sidecar model使用之间优劣势对比的技术博客,我将发表在csdn上帮助到其他开发者。
提问:GQA(分组查询注意力机制)有什么其他的学习资料吗?我觉得还是要必要深入学习一下,另外大概是从什么模型开始,都普遍采用GQA了?后续还会进一步优化么好眼力!能注意到 GQA 并开始思考它的演进,说明你已经从“大模型使用者”进阶到“大模型研究者”了。GQA(Grouped Query Attention)确实是当前大模型显存优化的核心技术,它像一把手术刀,精准地切掉了 KV Cache 中冗余
OpenClaw是一个开源、可扩展的个人AI助手框架将AI助手深度集成到你的数字生活通过插件连接各种服务(微信、Telegram、邮件、日历等)创建自定义技能,让AI帮你完成特定任务在本地或云端部署,完全掌控你的数据# 生成技能模板 openclaw skill create my-stock-tracker。
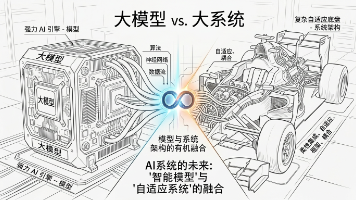
未来的 AI 系统,将是“足够智能的 Model”与“足够自适应的 Harness”的有机融合体。最顶尖的 AI 产品,必然是一辆法拉利:你需要一颗最强的发动机(Big Model),但也必须拥有一套顶级的空气动力学套件和底盘调校(Big Harness),否则,你的车根本跑不快,或者转个弯就翻了。
官网介绍:https://milvus.io/introMilvus 是一个以高效检索和高扩展性为特点的开源向量数据库,支持对大量的非结构化数据(如文本,图像还有多模态数据信息等)进行组织和检索。Milvus 使用Go和C++编程语言开发实现, 并通过CPU/GPU指令级优化,以实现最佳的向量搜索性能。Milvus 提供多种本地部署1. 基于 Kubernetes (K8s) 的全分布式架构:处理