




- @javastart
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
上期文章,我们介绍了MediaPipe Holistic的基础知识,了解到MediaPipe Holistic分别利用MediaPipe Pose,MediaPipe Face Mesh和MediaPipe Hands中的姿势,面部和手界标模型来生成总共543个界标(每手33个姿势界标,468个脸部界标和21个手界标)。对于姿势模型的精度足够低以至于所得到的手的ROI仍然不够准确的情况,但我们运行
由于图片不能复制,原连接如下:https://mp.weixin.qq.com/s?__biz=MzI5MDUyMDIxNA==&mid=2247488685&idx=1&sn=73c1274ae8801c6cfd21fd8e72a0206e&chksm=ec1ff954db68704227272a6a563d4df7577bd281490d3605a63...
K-3D是基于GNU/Linux和Win32的一个三维建模、动画和绘制系统,是一款免费、开放原始码的 3D 模型和动画制作与渲染(rendering) 工具,它强大的功能可以满足专业人士的需求。它可以帮助用户处理在3D扫描捕捉时产生的典型无特定结构的模型,还为用户提供了一系列工具编辑,清洗,筛选和渲染大型结构的三维三角网格(典型三维扫描网格), 该系统依靠了网格处理任务GPL的心向量图库。容易学习
这才是真正的物流大数据挖掘思路!2015-8-17 09:00| 发布者:admin| 查看: 108| 评论: 0|来自: PPV课大数据摘要: 物流大数据主要包括运单信息的数据和车辆信息的数据,然而关于运单信息往往涉及商业机密,并且信息分布于不同行业企业内部,不宜公开。因此当前现实的数据条件来看,实业界和学术界的物流大数据主要是关于货运车辆信 ...
一、本文目标利用facenet源码实现从摄像头读取视频,实时检测并识别视频中的人脸。换句话说:把facenet源码中contributed目录下的real_time_face_recognition.py运行起来。二、需要具备的条件1、准备好的Tensorflow环境2、摄像头(可用视频文件替代)3、准备好的facenet源码并安装依赖包4、训练好的人脸检测模型...
机器之心编译 在我们日常生活中所用到的推荐系统、智能图片美化应用和聊天机器人等应用中,各种各样的机器学习和数据处理算法正尽职尽责地发挥着自己的功效。本文筛选并简单介绍了一些最常见算法类别,还为每一个类别列出了一些实际的算法并简单介绍了它们的优缺点。https://static.coggle.it/diagram/WHeBqDIrJRk-kDDY
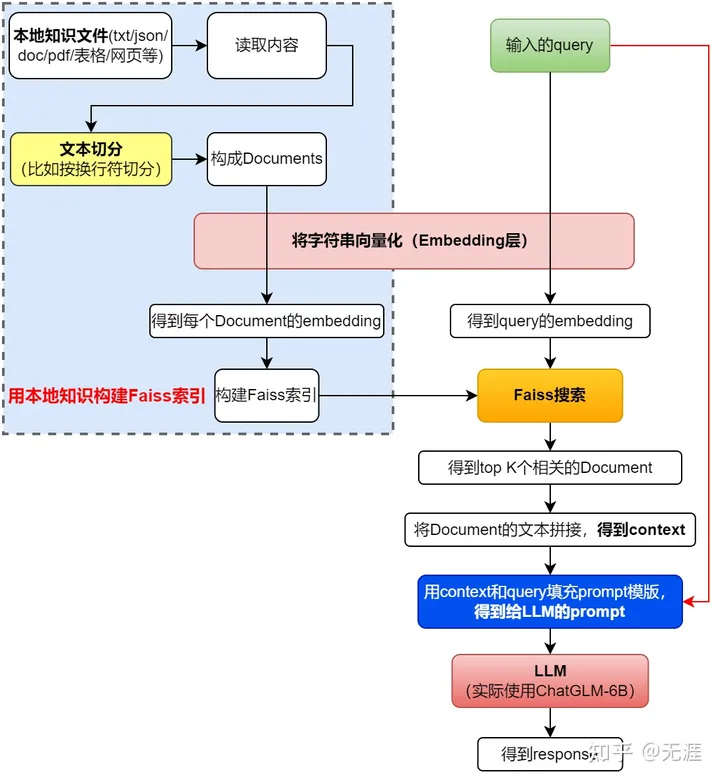
langchain-ChatGLM是一个基于本地知识的问答机器人,使用者可以自由配置本地知识,用户问题的答案也是基于本地知识生成的。GitHub - imClumsyPanda/langchain-ChatGLM: langchain-ChatGLM, local knowledge based ChatGLM with langchain | 基于本地知识的 ChatGLM 问答。
通过边缘算法服务器连接一路或多路摄像头,从不同角度拍摄实时图像,采用边缘算法与摄像头组合配置的分布式网络结构,节省了采用传统 PC 算法服务器(配置 GPU 与 NPU)实现的成本,并且具有更灵活的算法节点扩展方式和高鲁棒性。针对各类院校考试和训练场景,通过固定式检测设备或手机应用程序,可自动识别判断各项运动的动作是否规范标准,规避因人工考评导致的误判、漏判、作弊等问题,便于针对性地制定更精准有效
MemU 打破传统黑盒向量存储模式,将记忆以可读文档形式组织,存储于智能文件夹中,由「记忆代理」自动管理:动态筛选需记录的内容、更新旧记忆、归档无效信息。区别于传统向量嵌入的不可读存储,MemU 采用结构化文档组织记忆,支持人工直接查看(透明化AI记忆内容)、手动编辑(修正错误记忆)及实时分析(统计与可视化),兼顾调试便捷性与数据可操作性。例如提及“上周看的电影”时,能快速关联用户“电影偏好”“观