- @qq_42055933
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要 本文深入解析AI Agent的Function Calling交互原理,通过时序图拆解核心流程,涵盖用户提问、模型决策、函数执行与结果回传。核心角色包括用户、AI应用和基础大模型,通过ReAct架构实现自主决策循环。生活化类比(如餐厅点餐)帮助理解流程,并提供Python和Java双语言代码实战,展示如何注册工具、定义Function Schema及实现Agent逻辑。文章还总结了生产环境中

摘要 本文深入解析AI Agent的Function Calling交互原理,通过时序图拆解核心流程,涵盖用户提问、模型决策、函数执行与结果回传。核心角色包括用户、AI应用和基础大模型,通过ReAct架构实现自主决策循环。生活化类比(如餐厅点餐)帮助理解流程,并提供Python和Java双语言代码实战,展示如何注册工具、定义Function Schema及实现Agent逻辑。文章还总结了生产环境中
摘要 本文深入解析AI Agent的Function Calling交互原理,通过时序图拆解核心流程,涵盖用户提问、模型决策、函数执行与结果回传。核心角色包括用户、AI应用和基础大模型,通过ReAct架构实现自主决策循环。生活化类比(如餐厅点餐)帮助理解流程,并提供Python和Java双语言代码实战,展示如何注册工具、定义Function Schema及实现Agent逻辑。文章还总结了生产环境中
在RAG系统的架构中,文档分割器(Document Splitter)承担着"承上启下"的核心角色。当一份长篇文档(如PDF、Word、Markdown)被加载后,我们需要将其切割成语义完整、长度适中的小片段(Chunk),再送入向量数据库进行Embedding存储。分割质量直接决定检索精度:切得太碎会丢失上下文,切得太长会超出模型Token限制,切的边界不对会破坏语义连贯性。
文章摘要 作者分享了自己从后端开发转向Agent开发的经历,通过开发基于RAG的问答机器人和接入智谱GLM等国产大模型,发现用户对聊天机器人交互体验的感知有限,往往只将其视为简单的聊天框。为提升线下场景体验,作者利用魔珐星云平台为国产大模型添加具身交互能力,开发了一个3D数字人导购Demo。该Demo整合了模型理解、工具调用和实时表达,解决了多技术栈协同、交互延迟和打断响应等难点,展示了AI在门店

文章摘要 作者分享了自己从后端开发转向Agent开发的经历,通过开发基于RAG的问答机器人和接入智谱GLM等国产大模型,发现用户对聊天机器人交互体验的感知有限,往往只将其视为简单的聊天框。为提升线下场景体验,作者利用魔珐星云平台为国产大模型添加具身交互能力,开发了一个3D数字人导购Demo。该Demo整合了模型理解、工具调用和实时表达,解决了多技术栈协同、交互延迟和打断响应等难点,展示了AI在门店
摘要: RAG(检索增强生成)通过结合外部知识检索与大模型生成能力,解决了传统LLM的知识时效性、领域专业性和幻觉问题。其核心流程包括:用户查询输入→Embedding编码→向量检索→结果召回与重排序→Prompt组装→LLM生成。关键技术涉及Embedding模型选型(如OpenAI、BGE)、向量数据库(如Milvus、Pinecone)及相似度算法(如余弦相似度)。RAG架构经历了从朴素RA
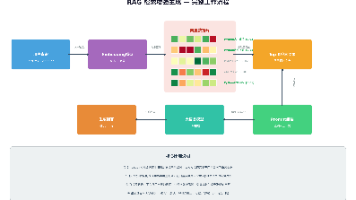
摘要: RAG(检索增强生成)通过结合外部知识检索与大模型生成能力,解决了传统LLM的知识时效性、领域专业性和幻觉问题。其核心流程包括:用户查询输入→Embedding编码→向量检索→结果召回与重排序→Prompt组装→LLM生成。关键技术涉及Embedding模型选型(如OpenAI、BGE)、向量数据库(如Milvus、Pinecone)及相似度算法(如余弦相似度)。RAG架构经历了从朴素RA
摘要: RAG(检索增强生成)通过结合外部知识检索与大模型生成能力,解决了传统LLM的知识时效性、领域专业性和幻觉问题。其核心流程包括:用户查询输入→Embedding编码→向量检索→结果召回与重排序→Prompt组装→LLM生成。关键技术涉及Embedding模型选型(如OpenAI、BGE)、向量数据库(如Milvus、Pinecone)及相似度算法(如余弦相似度)。RAG架构经历了从朴素RA
摘要:视频介绍了基于亮数据 Bright Data SERP API 的 Google 多场景数据采集实操(包括 Maps、Trends 和 AI Overview)。用户可通过专属链接注册,免费使用 MCP 并获得 25 美元试用金,适用于 AI 开发者、数据工程师及创业团队测试项目需求。官方推荐关注 CSDN 技术博客、GitHub 中文区和知乎机构号获取最新技术动态与福利。