




- @2402_84949062
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在上一篇文章我讲了如何利用LLaMA-Factory微调大模型,这一篇我会简单的讲一下如何将训练完成后的模型导出并加载到ollama供自己调用
MinIO 是一个非常轻量的服务,可以很简单的和其他应用的结合使用,它兼容亚马逊 S3 云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等。我将在本篇展示如何进行文件的上传

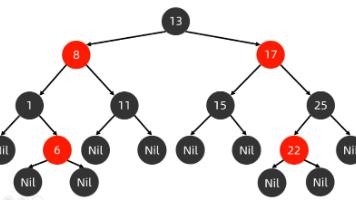
【数据结构】红黑树超详解---一篇通关红黑树底层原理(含源码解析+动态构建红黑树)
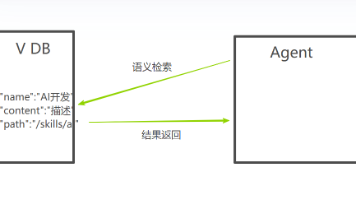
本文探讨了智能体应用中Skill配置的优化方法。核心思路是采用"渐进式披露"策略,通过树状目录结构组织大量Skill文件,并建立索引机制减少模型上下文负担。文章提出多维度优化方案:1)使用语义向量+关键词的混合检索提升召回率;2)引入查询改写机制处理模糊请求;3)设置Top-K和阈值过滤确保结果相关性;4)实现冷热数据分离的缓存策略。这些方法共同解决了生产环境中Skill检索的
本文介绍一款与langchain适配性极好,额度大的api联网搜索工具Tavily,原生支持作为工具为大模型配置。每月大量免费额度,方便测试和个人开发。

本文介绍了Claude Code的安装与配置方法。提供了两种安装方式:通过npm指定2.1.153版本安装(新版v2.1.156不支持第三方模型),或使用脚本安装。详细说明了环境变量设置步骤,并推荐安装CC-Switch工具以支持第三方模型访问。文章给出了DeepSeek-V4的配置示例,特别强调需禁用自动更新以避免版本升级导致的问题。最后通过终端测试验证了配置的正确性,确认v2.1.153版本可

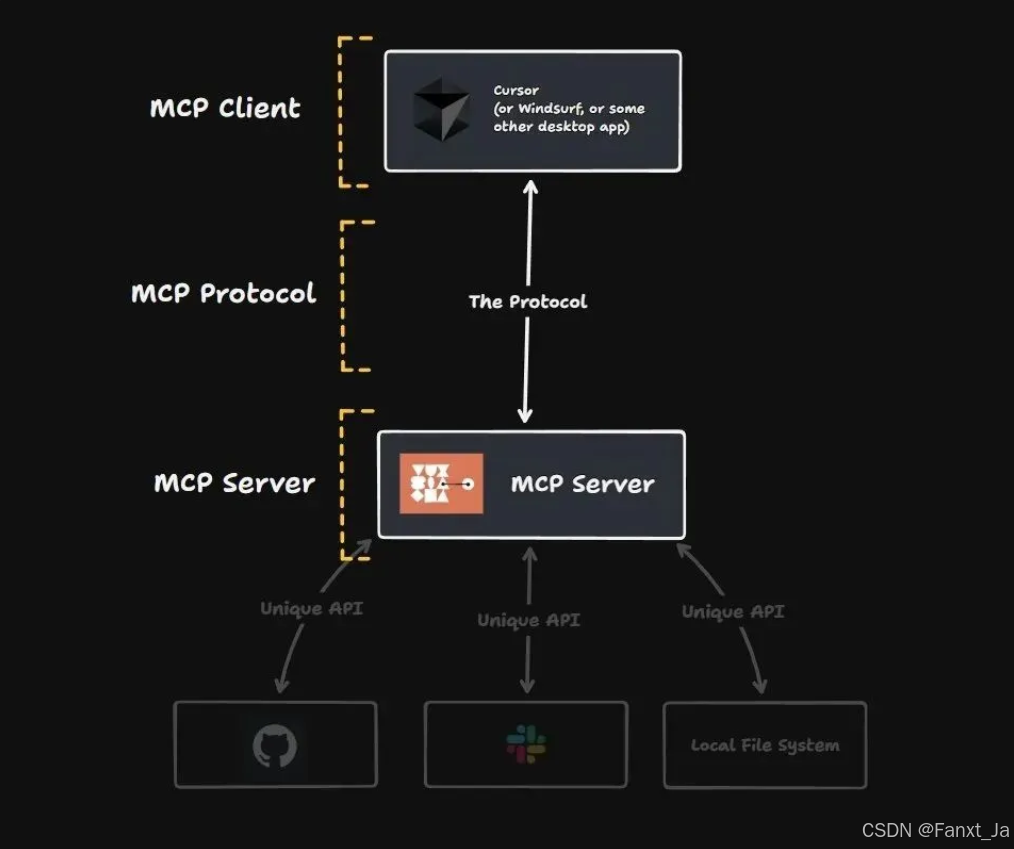
在AI的时代下,各企业也开始了转型,逐步向智能化方向转变,首当其冲的就是服务自动化、智能化,但是由于以往大模型与企业本地服务接口的匹配性问题,导致调用本地知识库的过程复杂化。我将介绍一个专门解决这类问题的标准化协议MCP,以医疗场景为例,用于介绍其在应用上的优势。
经过近百次的尝试,我发现通过代码直接部署大模型的不稳定性以及操作、技术上的难度远远超过了其本身的价值,尤其是对于初学者以及硬件能力较弱的机器。而采用ollama直接一键部署大模型则显得更加有优势,其在模型的控制上更稳定,模型库包含了大量不同大小的模型的不同量化版本,一键部署更加方便。 上一篇文章我介绍了通过Python环境直接使用代码部署大模型的示例,本篇我将借助ollama完成同
Spring AI更新的速度非常快,在一个月之前我还在用着最新的M7版本,中间经过M8、1.0.0RC1,现在马上就到了1.0.0正式版。正式版当然也新增了许多东西。 因为大多数人都在用M7和M8版本的Spring AI,本篇文章我就介绍一下M7、M8版本向1.0.0版本做兼容时主要需要修改的点

在较新的Java版本中,编译器已经支持了接入各种AI模型工具进行开发,这篇文章我会介绍如何利用Spring AI进行大模型的调用的基础方法
