登录社区云,与社区用户共同成长
邀请您加入社区
前言:SOA(面向服务的架构)是目前企业应用开发过程中普遍采用的技术,基于MVC WebAPI三层分布式框架开发,以此适用于企业信息系统的业务处理,是本文论述的重点。此外,插件技术的应用,富客户端JQuery实现技术,本文也对其具体实现做以说明。相关示例解决方案可以参考GitHub资源,在文章结尾给出。1.系统分层体系架构设计分布式三层系统简单分为数据访问层,业务逻辑层...
FHook:Android Java 层全函数 Hook 框架 FHook 是一款无需 root 的 Android Java 层 Hook 框架,支持 API 28+ 系统。主要特点包括: 任意 Java 方法的入参/返回值拦截与篡改 支持类/实例批量 Hook,覆盖系统关键点监控 提供 Gradle 依赖、源码集成和应用注入三种使用方式 适用场景: 运行期调试(打印调用栈/参数) 临时数据修正
本文介绍了Go语言高阶测试编程技术,主要包括单元测试、Table-Driven测试、基准测试和模糊测试。文章首先讲解了Go内置测试框架的基础用法,包括测试函数编写和常用测试命令。然后重点介绍了Table-Driven测试模式,通过结构体定义测试用例表,实现高效、清晰的测试代码组织。示例中展示了如何测试带错误处理的函数和递归函数,包括正常和异常情况的测试用例设计。最后简要提及了基准测试和模糊测试的概
本文是一篇Python编程入门教程,从基础语法到核心概念全面讲解。主要内容包括:变量与数据类型(动态类型特性)、运算符(算术/逻辑/比较)、流程控制(条件/循环语句)、函数定义与调用(参数/返回值/作用域)、常用数据结构(列表/元组/字典)、文件操作(读写/编码处理)以及标准库和第三方库的使用。通过大量代码示例详细说明了Python的核心语法规则和常见用法,强调实际编程中的易错点和实用技巧,帮助初
JSON Schema是一个用来定义和校验JSON规范的工具,用来检测返回的JSON是否符合预期。
如图:有一个软件有三个版本分别为v110、v111以及v112,其中v110版本已经上市说明功能1到功能30通过了测试,但一段时间后推出了v111版本新增了功能31,这时候我们需要对功能31进行测试,同时为了防止新功能的出现影响前30个功能,我们仍需要对功能1-30进行测试,同样,当v112版本出来时,虽然没有新增加功能,但是我们发现功能30进行了更新,我们同样为了防止更新对其他功能和历史版本造成
文章摘要:MyBatis作为持久层框架可简化JDBC操作,其核心流程包括:1)创建SpringBoot工程并配置MyBatis和MySQL依赖;2)定义实体类与Mapper接口;3)通过注解或XML编写SQL。关键点在于@Mapper注解会触发MyBatis动态生成接口代理类并交由Spring管理,与@Service不同,开发者无需手动实现接口。测试时使用@SpringBootTest自动加载Sp
AI Agent 作为人工智能领域的重要分支,其核心在于模拟智能体的自主决策与任务执行能力。其工作原理通常基于大语言模型,结合规划、工具调用、记忆管理等模块,实现复杂任务的自动化处理。这种技术架构的价值在于能够突破单一模型的局限,通过调度外部工具与环境交互,完成更开放、动态的作业流程。在应用场景上,AI Agent 特别适用于自动化工作流编排、复杂信息处理与决策支持等领域。本文聚焦于 **AI A
STW就是停止所有工作线程,就是GC的时候得停...停一会儿。CMS是并发标记清除,G1是垃圾优先,G1比CMS好用...吧?反正现在都用G1嘛!具体区别...一个是并发,一个也是并发,但是G1把堆分成Region了...多了Region的概念。
本文将彻底改变你对Dev-C++静态库使用的认知,提供一套无需创建臃肿项目文件的现代工作流。对于教育场景,这种方法尤其有价值——学生可以专注于算法实现而非项目配置,教师也能更方便地分发和收集作业代码。传统Dev-C++教程通常会引导用户通过创建"Static Library"项目来生成库文件,再通过"Console Application"项目来使用这些库。创建高质量的静态库不仅仅是编译代码那么简
在这次面试中,张明展示了扎实的Java全栈开发能力,涵盖了后端Spring Boot、数据库MyBatis、前端Vue3、微服务Spring Cloud等多个技术栈。他在项目中积累了丰富的实战经验,并能够将理论知识与实际开发相结合。同时,他也展现了一定的测试能力和DevOps意识,比如使用JUnit 5和Mockito进行单元测试,以及Docker和Kubernetes的部署实践。虽然在某些细节上
debug→ 调试细节info→ 正常流程warning→ 警告error→ 错误critical→ 严重错误#指定输出级别:Info及以上#自定义日志对象#配置自己的日志级别logger.debug("调试信息")logger.info("普通信息")logger.warning("警告")logger.error("报错信息")logger.critical("严重错误")占位符作用日志记录的
本项目是一个基于 WebSocket 的。用户可以通过浏览器注册/登录,选择在线用户进行私聊,实现消息的实时收发。系统采用 Java 作为后端语言,使用 WebSocket 实现通信,前端使用 HTML/CSS/JavaScript 构建页面。
每次开始新的量化研究项目时,最让我头疼的就是整理那些繁琐的证券代码。直到发现了Wind的wset接口,才真正实现了"代码自由"。今天我就把多年实战中积累的自动化解决方案分享给大家,包含完整的错误处理机制和文件备份功能。在实际项目中,我会把所有这些功能封装成一个MarketDataCollector类,包含完整的日志记录和异常通知机制。一个经验之谈:获取期货代码时,特别注意主力合约切换日期,这时容易
在开始追踪数据流转之前,我们需要先了解典型SpringBoot项目的三层架构以及各层对应的数据对象类型。这种分层架构不仅使代码更易于维护,还能有效分离关注点,让每一层专注于自己的职责。在不同层级之间传递数据时,我们会使用不同类型的对象来表示数据:对象类型全称使用场景所在层级VO用于Controller与前端交互ControllerBOService层内部业务处理ServiceDO与数据库表对应的实
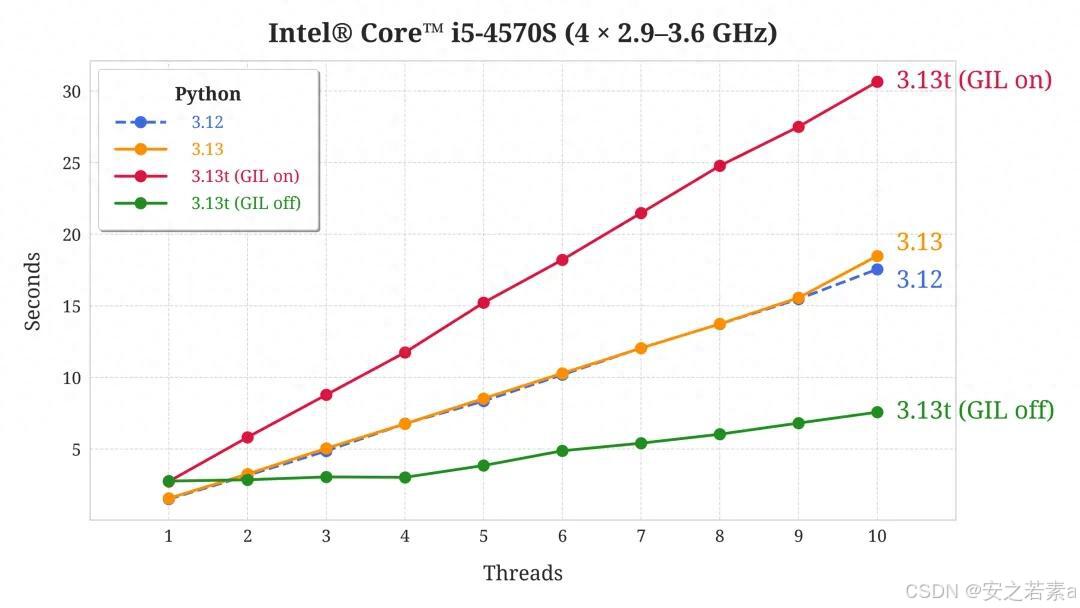
python threading大家好,我是风行者,一个拥有15年开发经验和教学经验的80后Python 3.13.0 终于来了!Python 3.13
这不是普通的游戏——你的每个决策都将通过代码转化为AI智能体的行动。庙算兵棋平台为技术爱好者打开了一扇门,让我们能用Python培养属于自己的"数字指挥官"。记住,每个优秀的AI指挥官都是从第一个"移动"指令开始的。则是平台提供的模板类,包含了智能体与平台交互的基本框架。就像训练新兵需要先教他立正稍息一样,我们的第一个智能体将从最基础的动作开始学起。让我们实现一个最简单的"巡逻型"智能体——它会在
本次测试针对 “贯鸿” 网页聊天室项目的注册、登录、会话管理、消息传输管理核心功能展开。共设计并执行了 几十个测试用例,涵盖了功能测试、边界值测试、异常情况测试等多个方面。测试用例执行情况如下:通过的有45个用例,占大概90%,失败的有5个,占10%,已经对失败的部分进行调整,用例也通过了。编写程序前期真的需要花费多点时间进行设计与思考,不断完善UI界面的功能。缺陷分布:1.注册功能用户名重复注册
大型 CAD软件架构-------------开源代码 2011-03-03 16:25:00| 分类:默认分类 | 标签:|字号大中小 订阅现在网上有很多开放源代码的CAD可以看,总结一下。OpenCASCAD网址是:ht
<br />在世面上的自动化测试工具很多。有开源的,有商业化的,各有各得特色,各有各得优点!下面我就介绍几个我用过的开源自动化测试工具。<br />1 测试 WEB<br /><br />SELENIUM可以说是测试WEB最全面的开源自动化工具, 它可以在WINDOWS, LINUX, MAC 和 SOLARIS 上运行, 而且可以几乎用任何一种编程语言进行构建, 你可以用你熟悉的语言包括 JAV
IK groups and IK elements VREP中使用IK groups和IK elements来进行正/逆运动学计算,一个IK group可以包含一个或者多个IK elements:IK groups: IK groups group one or more IK elements. To solve the kinematics of a simp...
我们大家一定知道百度和谷歌有一个蜘蛛机器人,换句话说就是百度和谷歌的一套收录网站的程序或系统,我们都称它为蜘蛛机器人,他们是程序不是人,也不是神,所以它们总有自己的活动规律,下面就来谈谈。一.网站收录初期 网站被百度收录初期的活动规律,首先进入你提交的网站首页或页面,然后从源文件中分析提取出你提交页面下的内链,然后逐一的提取你的网页。当然它不会一天两天的就给你把你加的
比赛规则: 机器人照片: 2017年山东省机器人比赛一等奖(交叉足)四自由度,arduino nano 最小系统板,用了5个稳压模块其中4个模块分别负责给4个舵机供电,降压模块调到5.2v(电压调高了容易烧舵机!!),另一个给arduino供电,电池采用航模锂电池。舵机最好要选用优质舵机60块钱以上的吧,否则很容易坏。 比赛程序大体思路,循迹分为左侧循...
芯片封装步骤:来料(晶圆)→晶圆表面贴膜(WTP)→晶圆背面研磨(GRD)→晶圆背面抛光(Polish)→晶圆背面贴膜(W-M)→晶圆表面去膜(WDP)→晶圆烘烤(WBK)→晶圆切割(SAW)→切割后清洗(DWC)→晶圆切割后检查(PSI)→紫外线照射(U-V)→晶片粘结(DB)→银胶固化(CRG)→引线键合(WB)→引线键合后检查(PBI)→塑封(MLD)→塑封后固化(PMC)→正印(PTP)→
(1)电功率的计算公式 用电压乘以电流,这个公式是电功率的定义式,永远正确,适用于任何情况。对于纯电阻电路,如电阻丝、灯炮等,可以用“电流的平方乘以电阻”“电压的平方除以电阻”的公式计算,这是由欧姆定律推导出来的(其中的电流和电压都是有效值(有效值就是均方根值,对于正弦波,有效值等于峰值/1.414,注意是峰值不是峰峰值))。 但对于非纯电阻电路,如电动机等,只
在第一部分使用高速SPI以太网控制芯片W5200登录Telnet服务器的时候,我们给大家介绍了很多关于telnet服务器的相关知识,不知道对您是否有帮助呢?您有什么意见和建议呢?欢迎和我们一起来讨论。我们已经知道Telnet服务虽然也属于客户机/服务器模型的服务,但它更大的意义在于实现了基于Telnet协议的远程登录(远程交互式计算),今天我们继续为大家讲解如何使用W5200E01-M3登录T
(以oracle9i版本为例,本机必须安装oralce9i的客户端)第一步:orahome92-configuration and migration tools- net managers第二步:在“服务命名”中点“+”第三步:编辑一个你的服务名,(不是对方的数据库名)第四步:默认选择TCP/IP第五步:主机名填入对方的机器IP
<br />CSCI是计算机软件配置项(Computer Software Configuration Item)简称,在软件设计文档中经常用到。<br /> 配置与配置项<br /><br /> 在配置管理中,“配置”和“配置项”是重要的概念,“配置”是在技术文档中明确说明并最终组成软件产品的功能或物理属性。因此“配置”包括了即将受控的所 有产品特性,其内容及相关文档,软件版本,变更文档
IC卡用的芯片是一种集成电路芯片,但决不是一般意义上的集成电路芯片。除了IC卡的特殊应用环境要求IC卡用芯片具有较小的体积及环境适应性外,更重要的就是IC卡用芯片的安全性。 IC卡用芯片的安全性是IC卡安全性的基础,在IC卡用芯片的设计阶段就提供了完善的安全保护措施,十分重要也十分有效。这首先要求对IC卡用芯片可能进行的物理攻击(探测)进行全面的分析。 一般典型的探测方法有:通过扫描电
集成锁相环芯片Si4133的原理及应用[日期:2008-9-3]来源:中电网 作者:刘华平,郭伟[字体:大 中 小] 引言 频率合成技术是近代射频微波系统的主要信号源。目前广泛采用的是数字式频率合成器,一般由晶体振荡器、分频器、鉴相器、滤波器和VCO(压控振荡器)等组成,将晶体振荡器输出的频率信号分频得到标准频率信号,然后与VCO输出的频率信
一、答辩前准备1、熟悉你的论文,分为两类,一部分是做本科生毕业设计的(xx系统,xxapp),另一部分做算法的,我着重说的是做毕业设计的2、准备你的ppt,链接如下(https://www.zhihu.com/question/23221029),注意多图表,少文字,我们答辩的时候,直接跳过背景,直接看你的设计部分,上台,打开你的ppt,鼠标选中ppt演示---排练计时,每个人5到9分钟不...
测试
——测试
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI Agent技术社区
AI Agent技术社区








 DAMO开发者矩阵
DAMO开发者矩阵










