- @NIIT0532
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
鸿蒙智联(HarmonyOS Connect)与小米米家等智能家居平台在生态模式、用户体验、供应链支持和市场布局等方面存在显著差异。鸿蒙智联聚焦底层技术,提供高壁垒的互联协议和芯片支持,强调多设备协同和隐私保护,吸引了美的、海尔等高端品牌合作,市场表现强劲,设备数量已超10亿台。小米米家则以产品主导,通过性价比和广泛的产品覆盖吸引用户,但面临高端市场和技术创新挑战。未来,鸿蒙智联有望通过跨行业设备

环境准备graph LRA[安装Tesseract OCR] --> B[添加系统PATH]B --> C[下载语言包]C --> D[放置到tessdata目录]项目配置-- Maven依赖 -->核心代码模板try {return "";性能优化检查表[ ] 图片DPI≥300[ ] 已完成二值化处理[ ] 选择了合适的PSM模式[ ] 验证了语言包加载[ ] 处理了特殊字符集。
强化学习(Reinforcement Learning, RL)与具身智能(Embodied AI)的结合是当前人工智能领域的前沿方向,尤其在基于大型语言模型(LLM)的智能体(LLM-based Agents)中展现出巨大潜力。以下从突破点、核心方向及代表作的视角,系统分析其技术融合路径与未来挑战
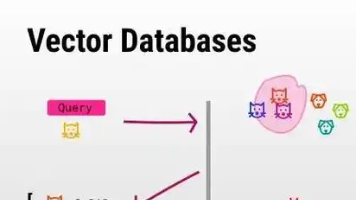
Chroma是一款开源的向量数据库,专门为AI应用设计,可以高效存储和查询嵌入向量(embeddings)。它提供了简单的API接口,支持语义搜索、推荐系统等多种AI应用场景。
这些差异在实际数据库迁移或跨平台开发时需要特别注意,建议通过数据库文档和测试验证具体语法。通过系统化的准备、执行和验证流程,可以确保从PostgreSQL到达梦数据库的平滑迁移。:达梦默认使用READ COMMITTED,与PG相同但具体实现可能有差异。:PostgreSQL的TSVECTOR到达梦需要使用专门的全文检索功能。:类似语法转换,注意达梦的触发器事件可能有差异。

EvidentlyAI是一款开源机器学习可观测性框架,专为AI系统全生命周期管理而设计。该工具提供三大核心功能:数据质量检查(缺失值/异常值检测)、模型性能评估(支持分类/回归/生成任务)、实时监控与漂移检测,覆盖从实验到生产的全流程。其优势在于模块化设计、100+内置指标和灵活的Python接口,适用于表格/文本/嵌入等多种数据类型。关键应用场景包括模型验证、生产监控和合规分析。使用注意事项涵盖
数据中台与低代码平台的结合正在成为企业数字化转型的重要推手。数据中台的核心作用是整合企业中的不同数据资源,打破数据孤岛,让各个部门在统一的平台上共享数据。这种数据共享不仅方便,而且能极大提高协同效率。而低代码平台则是一种能够大大降低编程难度的开发方式,它提供可拖拽的组件和直观的逻辑操作界面,让开发人员甚至非技术人员都能快速开发出功能完整的应用程序当数据中台与低代码平台结合时,数据中台可以作为基础设
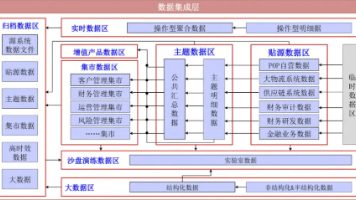
下载对应版本的NVIDIA驱动(.run文件)并传输到内网环境。下载对应版本的CUDA安装包(.run文件)并传输到内网。下载对应版本的PyTorch wheel文件并传输到内网。下载对应版本的TensorFlow wheel文件。下载对应版本的cuDNN压缩包并传输到内网。下载OpenCV源码包并传输到内网。

【代码】图数据库neo4j面试题。
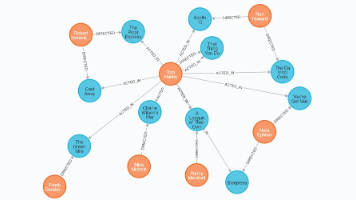
和 。