登录社区云,与社区用户共同成长
邀请您加入社区
本指南详细介绍了将 Sphinx 文档部署到 GitHub Pages 的两种方法:手动部署和通过 GitHub Actions 自动部署。内容包括项目结构准备、Sphinx 配置检查、HTML 文档生成,以及具体的部署步骤。手动部署部分讲解了如何推送 HTML 文件到 gh-pages 分支并配置 GitHub Pages 设置。自动部署部分则详细说明了如何创建 GitHub Actions 工
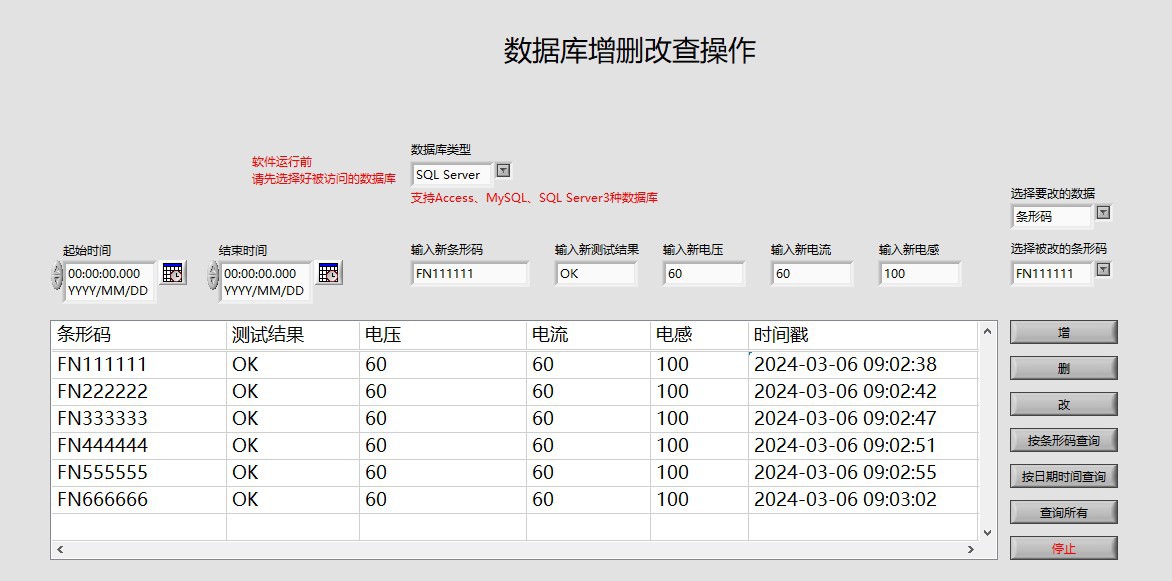
不同数据库需要对应的驱动,比如MySQL要装ODBC驱动,SQL Server建议用Native Client。今天咱们来点LabVIEW操作数据库的硬核玩法,重点拆解Access/MySQL/SQLServer三个数据库的增删改查实战。遇到坑的可以重点看连接字符串配置和驱动版本,这俩坑我帮你们踩了三年...Labview实现对Access/MySQL/SQLServer3种数据库增删改查操作,源
这是最核心的自动文档扩展,可从 Python 源码中提取类、函数、方法、模块的 docstring,并生成 API 文档。Sphinx 是 Python 生态中最流行的文档生成工具,最初为 Python 官方文档而开发,现已广泛用于自动生成各类项目文档,包括 Python 库、API、教程、开发手册等。允许跨项目引用外部文档,如 Python 官方文档、NumPy、Django 等,只需配置对应的
首要原则是“异步到底”,即从异步调用点开始,整个调用链都应采用异步方法,避免混合同步和异步调用导致的死锁或线程池耗尽。Task 类属于 System.Threading.Tasks 命名空间,它不仅能表示异步操作的执行状态,还能承载返回值,并通过 ContinueWith 等方法实现任务延续,构建复杂的异步工作流。为了解决 Task 编程模型中的回调地狱问题,C# 5.0 引入了 async 和
Sphinx 是 Python 生态中强大的文档生成工具,可将 reStructuredText 或 Markdown 转换为 HTML/PDF 等格式。通过 Sphinx,可高效生成专业级技术文档,大幅提升项目可维护性。(实际效果需本地生成查看)
Java Lambda表达式核心解析 Lambda是Java 8引入的函数式编程核心特性,本质是对单一抽象方法接口(函数式接口)的简洁实现。其语法为(参数)->{方法体},如(x,y)->x+y,可替代匿名内部类,依赖@FunctionalInterface注解确保接口合规。JVM通过invokedynamic指令动态生成轻量级函数对象,相比匿名类内存更低、执行更快。典型应用包括集合遍
Sphinx是Python生态中最主流的文档生成工具,最初为Python设计,现支持多种输出格式(HTML、PDF等)。其核心功能包括自动索引、代码高亮和交叉引用,极大简化大型文档维护。基于Pygments实现多语言代码高亮,并通过扩展生态支持Jupyter集成等高级功能。安装简单(pip install sphinx),被Python官方文档及主流项目(如Django、NumPy)广泛采用,是技
Sphinxcontrib Rust 文档的本地化
它用 reStructuredText 作为标记语言,输出 HTML、PDF、EPUB、纯文本、TeX、man page 等多种格式。Python 官方文档、Django、Flask、NumPy、Pandas,你能数出来的主流 Python 项目,文档几乎都是用 Sphinx 生成的。你定义好文档树,Sphinx 自动处理页面之间的链接关系,兄弟页、父页、子页,不用手动维护。社区贡献了大量扩展,有
Sphinx是Python社区广泛使用的文档生成工具,可将reStructuredText源码转换为多种格式文档(HTML/PDF/EPUB等)。其核心优势包括:自动交叉引用、代码高亮、多格式输出、扩展生态完善等。通过解析语义化标记,Sphinx能自动维护文档链接和索引,支持从源码注释生成API文档,大幅降低维护成本。虽然学习曲线略陡峭,但其在大型项目中的结构管理能力突出,被Python官方文档及
SGLang 文档的本地化
Sphinx是Python社区主流的文档生成工具,支持将reStructuredText格式文本转换为HTML/PDF/EPUB等多种格式。它提供自动交叉引用、代码高亮、索引生成等功能,大幅降低技术文档维护成本。作为成熟方案,Sphinx被Python官方文档及众多开源项目采用,尤其适合需要多格式输出和复杂文档结构的项目。虽然学习曲线略陡,但其强大的语义化处理和扩展能力使其成为中大型项目的理想选择
结合传统 HMM-GMM 模型与深度学习(如 DNN-HMM),强调灵活性和扩展性110。:基于传统的隐马尔可夫模型(HMM)和 N-gram 语言模型,适合轻量级应用110。:社区活跃(121 位 GitHub 贡献者)、支持多模型实验(如端到端训练)110。:模型文件较大(需 GPU 加速)、Mozilla 已终止维护,社区支持可能受限36。:高准确率(尤其在噪声环境)、低延迟实时转录、隐私保
原文:towardsdatascience.com/switching-from-sphinx-to-mkdocs-documentation-what-did-i-gain-and-lose-04080338ad38?由在上的照片“一个项目的好坏取决于其文档” – 这是我之前 3 篇文章系列中强调文档重要性的引用。:描述项目内部运作的技术方面,可以是流程文档或产品文档:描述它解决了哪些业务问题或
Tile 语言文档的本地化
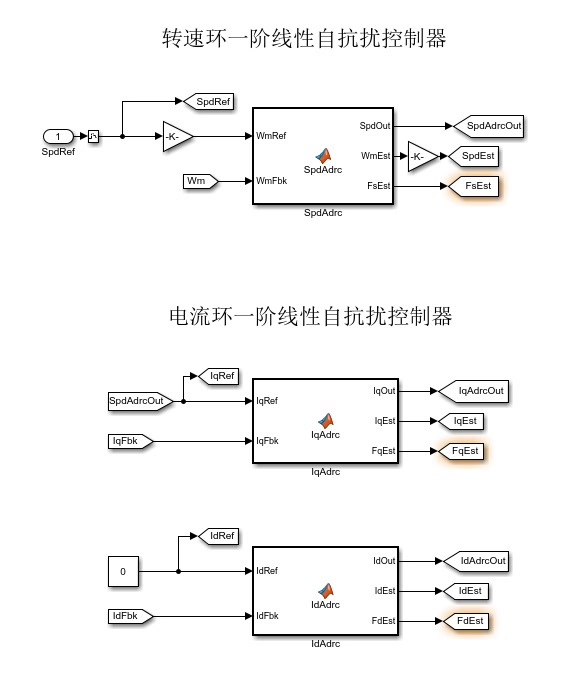
这个模型里的“家伙事儿”还挺多,主要有DC直流电压源、三相逆变器、永磁同步电机、采样模块、SVPWM、Clark、Park、Ipark,还有采用一阶线性自抗扰控制器的速度环和电流环等模块。这里面的SVPWM、Clark、Park、Ipark以及线性自抗扰控制器模块,都是用Matlab function编写的,这就有意思了,为啥呢?因为它和C语言编程很接近,以后要是想搞实物移植,那可就方便多啦。而且
这个插件会为生成后的文档添加 .nojekyll 文件, 也会为 GitHub Pages 自定义域名添加 CNAME 文件。如果没有 .nojekyll, GitHub Pages 会认为 _ 开头的文件夹是 jekyll 内部文件夹, 然后将它过滤掉。build:文件夹,当你执行make html的时候,生成的html静态文件都存放在这里。make.bat:windows平台用于编译文档项目的
使用shpinx编写文档有如下优点:使用sphinx编写的文档可以方便地制作html、pdf等格式,非常方便浏览和转换。sphinx支持rst和markdown语法,方便共享及开源编辑,使用git也方便跟踪。由于rst语法比markdown语法更强大和方便,我们主要采用rst语法编写文档, linux内核源码文档也是使用rst格式编写的。我们的文档也支持markdown,主要是为了方便不熟悉rst
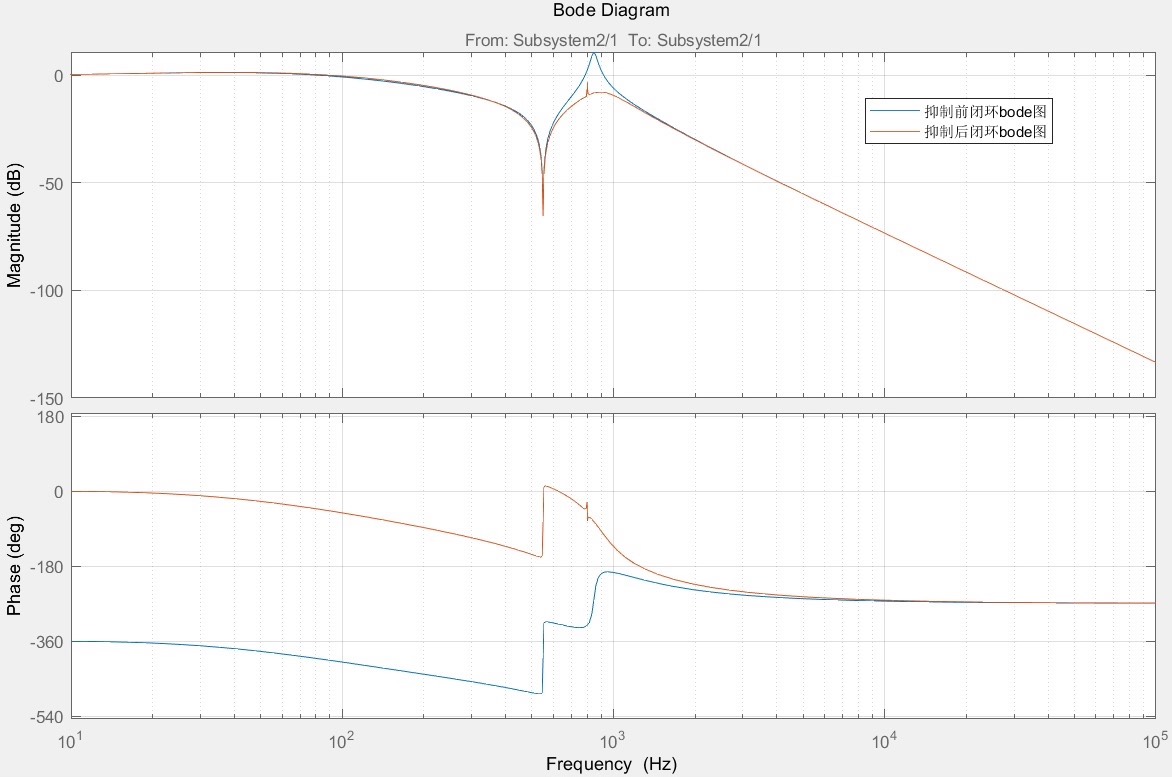
伺服系统基于陷波滤波器双惯量伺服系统机械谐振抑制matlab/Simulink仿真1.模型简介模型为基于陷波滤波器的双惯量伺服系统机械谐振抑制仿真,采用Matlab R2018a/Simulink搭建。仿真模型由传递函数形式搭建,主要包括转速环、电流环、低通滤波器、陷波滤波器、双惯量谐振模型。2.算法简介实际工程中,由于传动环节机械间隙和柔性的影响,机械谐振现象经常会发生,导致伺服系统运行过程中会
通过在Matlab2016的Simulink中对双馈风力发电机模型的研究与仿真,我们能够深入理解DFIG的运行原理和控制策略。给定风速变化下的电流电压波形分析,也为实际风力发电系统的设计和优化提供了有力的参考。当然,实际应用中还需要考虑更多复杂因素,如电网故障、环境干扰等,但这个基础的仿真模型已经为我们打开了DFIG研究的大门。希望本文对大家在DFIG相关研究和实践中有所帮助。
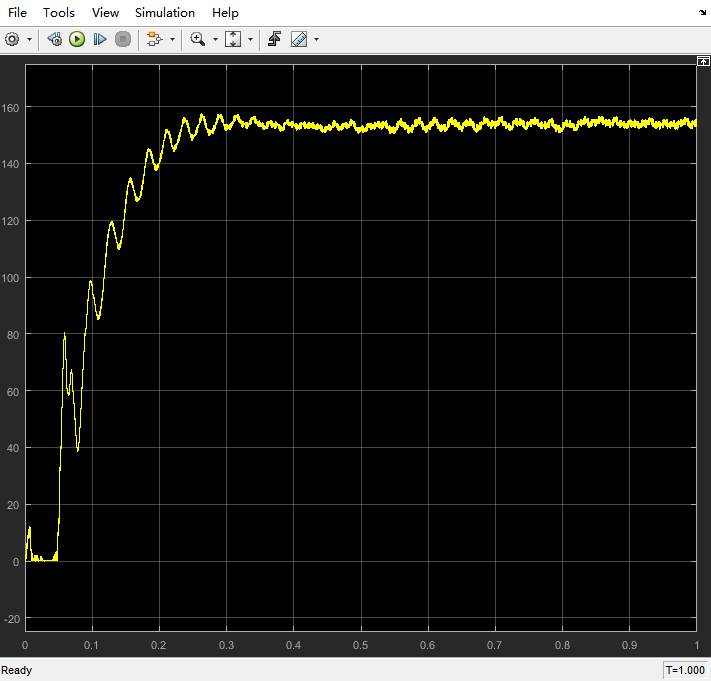
Y轴范围建议绑定自动缩放,但记得加个滞后滤波,否则像我有次接了个0-5V的传感器,某个突变点直接把坐标轴撑到500V,吓得我差点拔电源。数据突然卡顿、波形断断续续、十六进制和ASCII切换到眼瞎...今天咱们用LabVIEW整一个稳如老狗的串口波形读取方案,实测在115200波特率下连续工作8小时不丢包,连隔壁工位搞STM32的老王都来偷师。上次有个兄弟死活收不到数据,最后发现是对方设备用了1.5
DS18B20用单总线接在PA0,注意这里必须接4.7K上拉电阻,之前偷懒没接结果温度读数乱跳。最近在实验室折腾了个基于STM32的温度控制系统,核心思路就是通过DS18B20实时测温,配合继电器控制加热制冷设备。调试过程中发现这玩意虽然功能简单,但各种坑真是踩了个遍,今天就把实战经验整理出来,给想自己做温控的朋友避避雷。完整工程里包含带注释的源码、仿真文件和调试记录,在实测中室温到50℃的升温过
Sphinx是一个强大的Python文档生成工具,特别适合技术文档和API文档的创建。它能将文档源文件转换为HTML、PDF等多种格式,自动生成API参考文档,并支持丰富的扩展和主题系统。安装Sphinx后,通过sphinx-quickstart初始化文档结构,编写.rst文件并构建HTML即可快速生成专业文档。对于LLVM项目,Sphinx可与Breathe扩展配合,无缝整合手写文档和Doxyg
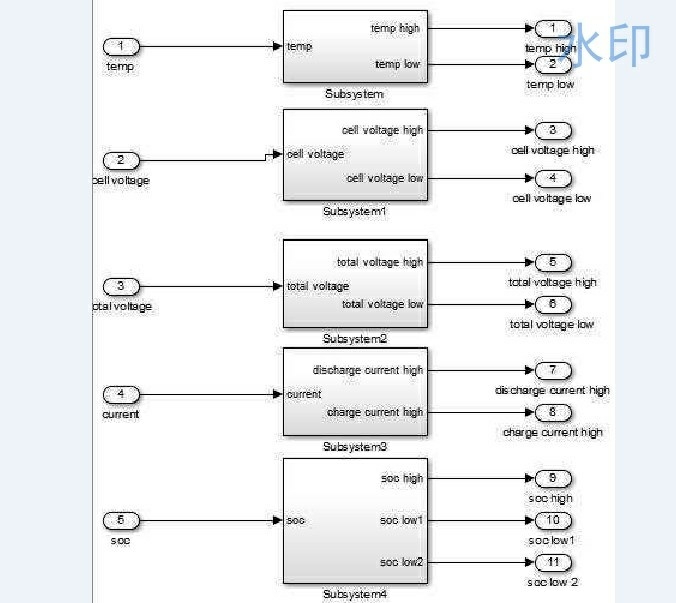
BMSmatlab仿真模型BMS仿真,电池管理系统,整个BMS的matlab仿真模型。包含限位,EKF-SOC,均衡,充点电控制,冷却风机,充电控制,开机自检功能在电动汽车和各类储能系统中,电池管理系统(BMS)起着至关重要的作用。它就像电池组的智能管家,全方位监控和管理电池的各项状态,确保电池安全、高效地运行。今天咱们就来深入聊聊 BMS 的 Matlab 仿真模型,看看这个模型是如何集成多种关
1、安装python环境这里就不介绍了#安装主题 sphinx_rtd_theme 的markdownpip install sphinx sphinx-autobuild sphinx_rtd_theme recommonmark sphinx-markdown-tables2、使用2.1新建app_tower目录进入该目录,执行sphinx-quichstart执行完毕后,就可以看见创建的工程
摘要:本文介绍在Ubuntu系统中如何通过systemd服务实现ROS launch文件开机自启动。主要步骤包括:1)在/etc/systemd/system/目录创建服务文件;2)配置服务文件内容,包括包名、launch文件名和用户信息;3)设置文件权限;4)启动并启用服务。通过完成这些步骤,系统将在每次启动时自动运行指定的ROS launch文件。
本文提供了在Ubuntu 20.04系统安装GCC 5.4/G++ 5.4的两种实用方案。第一种方案通过添加Ubuntu 16.04旧源快速安装,适合需要兼容历史代码或特定内核模块的场景;第二种方案采用源码编译方式,适合需要版本隔离的生产环境。文章详细解释了每条命令的作用,并给出了完整的工作流程,强调源码编译时需要创建独立构建目录等关键步骤。两种方案均可实现GCC 5.4的安全安装,用户可根据实际
以上步骤应该可以帮助你在Ubuntu 20.04上安装GCC 5.4和G++ 5.4。
本文提供了两种在Ubuntu离线环境中安装CMake的企业级方案。首选方案是使用官方二进制包:先在联网环境中下载.tar.gz包,传输到离线服务器后解压至/opt/cmake目录,并配置系统PATH即可使用。备选方案则采用源码编译,虽然耗时较长但定制性强,通过bootstrap生成Makefile后编译安装。两种方案均不依赖网络或系统库,安装路径规范且环境变量通过/etc/profile.d/持久
Sphinx是一个强大的文档生成工具,最初是为Python文档开发的,但现在也可以用于其他编程语言。它可以将reStructuredText格式的文档转换成HTML、PDF等多种格式,非常适合用来生成项目文档、API参考等。
1.用虚拟键绑定原始键(原始值变了 索引也会跟着自动变)2.利用全文索引(把虚拟键字符串逐字插入空格 强制用1字符串分词)3.使用时先用全文索引 搜索分好词的关键字 再like一下原始键 数据就准确了
以上步骤可以帮助你重置Jenkins的权限配置,使你可以再次登录。但请注意,这样做会关闭所有的安全设置,包括身份验证和授权。在重新配置正确的权限设置之后,不要忘记将"useSecurity"设置回"true"。
2)考虑到自动化脚本应兼容适用于所有文档工程,因此可以从Sphinx文档工程的conf.py文件中获取文档信息,如【project(文档名称)】或【release(版本号)】,用于设置文件名。今天的分享,就是这些内容。”——Sphinx文档工程目录下不只包含了1本文档,而是好几本文档,都需要发布,请问阁下该当如何应对?大家好,我是对“狗屁工作”本能感到厌烦和抵触,在AI的加持下,迫切想要找到方法解
编辑多个文档时,在没有标签页功能的情况下只能一个个保存,但有了这个插件,你可以右键点击标签,选择【保存所有】一键保存所有文档;当你打开多个Office文档时,软件会在Office界面的顶部新增一个"Office标签"选项卡,同时在功能区下方显示所有打开文档的标签页,界面直观清晰。在Office标签最左边有一个绿色的勾选按钮,这是控制标签栏显示与隐藏的开关,点击它就能显示标签栏,再点击一次就能隐藏标
PLC,也就是可编程逻辑控制器,就像是自动化控制系统的“大脑”。以s7 - 200为例,它能通过编程来控制和监控各种工业过程,像生产线的运转、机器人的动作、电机的启停等。它通常会和传感器、执行器等外围设备连接,通过输入和输出信号来实现对这些设备的控制。我们这次使用的西门子224XP,更是西门子公司推出的高性能、高可靠性的PLC控制器,适用于各种工业自动化应用。
"我:"因为我考得不好?"小哥:"可是...我在您家门口发现门是开着的...""兔子:"不用,我自带。"猪爸爸摸摸她的头:"别哭,爸爸给你讲个笑话...呼呼呼~""我摇头,她冷笑:"因为这个手指最没用,跟你一样。"斑马:"我还没准备好,先让长颈鹿说吧,他脖子长看得远。"我:"医生,我从小就不爱吃糖。"医生:"我知道,你该减肥了。"我写了:"42"(《银河系漫游指南》梗)"学生:"因为我终于睡着了。
PocketSphinx开源语音识别引擎实现STT(语音转文本)功能。重点讲解了中文模型环境配置方法:需下载中文语言模型并按要求修改文件名和目录结构。同时说明了音频格式转换的必要性,给出了使用ffmpeg将mp3/m4a转为wav格式的命令行操作及Python批量转换代码。
利用Langchain结合亮数据获取亚马逊产品信息。
在数据库的世界里,最近一股新的热潮正在涌动,那就是亚马逊云科技推出的。很多人说它“打破了物理规律”,听起来像是一句噱头,但当我深入了解之后才发现,这确实不是开玩笑。它背后有一些让人眼前一亮的创新思路,尤其是对并发连接和性能瓶颈这类老大难问题的全新解法。传统数据库就像老旧的高速公路,一旦车流量太大,就会堵得水泄不通。更多的连接进来,数据库就会开始锁表,查询和写入都变慢,用户体验急剧下滑。开发者只能不
Instagram的世界很大,机会也很多,但能长久留存的,一定是那些真心投入、持续优化的人。比如我接下来设置一个Instagram配置,浏览器选择Chrome(在这里称为SunBrowser),操作系统选择Windows和IOS,UA不需要修改,Cookie可以去网页中复制,这里暂时留空。我们先在正常浏览器中正常访问、登录Instagram,按F12打开开发者工具,选择一个流量包的消息头,在其中就
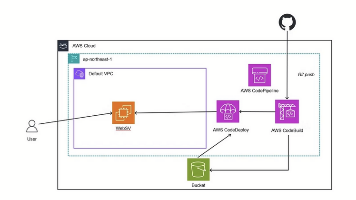
这个项目虽然基础,但涵盖了完整的CI/CD流程,特别适合想要入门亚马逊云科技自动化部署的小伙伴们。有了权限基础,现在我们可以创建文档服务器了。当然,在生产环境中,你可能需要考虑滚动部署或蓝绿部署来减少停机时间,但对我们这个简单项目来说,一次性部署就足够了。而且我们这个配置是最小化的,你完全可以在此基础上扩展,比如加入CodePipeline来编排整个流程,或者添加测试阶段等。在“存储桶名称”字段输
RS485自由协议
更多Python学习内容:ipengtao.com在软件开发过程中,文档是必不可少的一部分。高质量的文档可以帮助开发者和用户更好地理解和使用代码。Python的Sphinx库是一款强大的自动化文档生成工具,它能够帮助开发者轻松创建专业的文档。本篇文章将详细介绍Sphinx库的功能、安装与配置、基本和高级用法,以及如何在实际项目中应用Sphinx库。Sphinx库简介Sphinx是一个Python文
SphinxSphinx是一款免费的双许可搜索服务器。Sphinx是用C ++编写的,专注于查询性能和搜索相关性。主客户端API目前是SphinxQL,SQL的一种方言。几乎任何MySQL连接器都应该工作。此外,还提供了基本的HTTP / JSON API和许多语言(PHP,Python,Ruby,C,Java)的本机API。SQL,HTTP / JSON和自定义(传统)访问APINRT(近实时)
## 数据源src1source src1{## 说明数据源的类型。数据源的类型可以是:mysql,pgsql,mssql,xmlpipe,odbc,python## 有人会奇怪,python是一种语言怎么可以成为数据源呢?## python作为一种语言,可以操作任意其他的数据来源来获取数据,更多数据请看:(http://www.coreseek.cn/produc
PocketSphinx语音识别系统的编译、安装和使用文章转自:http://blog.csdn.net/zouxy09部分内容参考自:http://linux.goeszen.com/sphinx-speech-recognition-on-ubuntu-linux.html Sphinx是由美国卡内基梅隆大学开发的大词汇量、非特定人、连续英语
对于搜索来说,首先,也最重要的就是建立搜索空间。在语言识别中搜索空间是怎么建立的了。我们知道语音识别一般包括语言模型和声学模型。而语音识别就是要在搜索空间中找到最有可能的字的序列。我们一般是按句来处理的。一句话有许多词所组成,我们所要做的就是确定一句话,中的那些词即字。我们一般会在搜索空间中加上一些特殊的词来表示一句话的开始和结束。在sphinx中一般为表示句的开始,表示句的结束。对于搜索空间
sphinx
——sphinx
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 AI Agent技术社区
AI Agent技术社区




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AMD开发者中国社区
AMD开发者中国社区

 AtomGit开源社区
AtomGit开源社区




 腾讯云开发者社区
腾讯云开发者社区


 AI硬件创业社区
AI硬件创业社区

 魔乐社区
魔乐社区








 2048 AI社区
2048 AI社区

 智能体开发者社区
智能体开发者社区


 DAMO开发者矩阵
DAMO开发者矩阵


 九章云极普惠算力
九章云极普惠算力


 武汉城市开发者社区
武汉城市开发者社区



 中德AI开发者社区
中德AI开发者社区

 CSDN学习社区
CSDN学习社区



