登录社区云,与社区用户共同成长
邀请您加入社区
clickhouse本地表与分布式表的数据写入
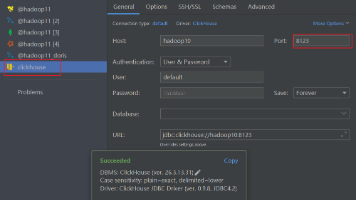
本文介绍了在ClickHouse上集成Spark环境的完整过程,主要包含以下内容: 环境准备 使用Docker部署ClickHouse测试环境(23.8和26.3版本) 解决数据目录权限问题:必须使用docker volume而非直接映射Windows目录 两种集成方式对比 旧版JDBC驱动(ru.yandex.clickhouse):已过时,功能有限但简单易用 官方Spark原生连接器(Cata
ClickHouse是一款开源列式存储OLAP数据库,专为海量数据分析设计,相比MySQL等行式数据库在聚合查询、实时报表等场景性能优势显著。本文为零基础用户提供ClickHouse一站式入门指南,涵盖核心概念、Linux原生部署和实战SQL操作。重点解析OLAP与OLTP的区别、列式存储原理,详细演示CentOS/Ubuntu系统安装配置(含远程连接、密码设置等生产级部署技巧),并通过用户行为分
本文针对支付风控、对账等强时序业务场景,对比分析了时序数据库TDengine和OLAP引擎ClickHouse的选型方案。通过支付流水业务实例,详细展示了两者在表结构设计、数据写入、查询优化等方面的实现差异:TDengine采用超级表模型,天然支持多租户隔离和时序快照追加,适合高并发写入和实时监控;ClickHouse凭借MergeTree引擎和强大分析能力,更擅长复杂宽表分析和历史数据回溯。文章
本文档记录了在 openEuler 24.03 (LTS-SP1) aarch64 操作系统、鲲鹏920 处理器上,源码编译 ClickHouse v26.3.17.4-lts 的完整过程,包含从环境准备、工具链自编译、指令集适配到最终 RPM 打包的每一步。
ClickHouse官网示例报错 DB::Exception: Cannot write into pipe: , errno: 32, strerror: Broken pipe: While executing TabSeparatedRowOutputFormat: While executing ShellCommandSource 解决方案
智能指针支持自定义删除器,扩展了资源管理范围。除了管理动态内存,还可以管理文件句柄、网络连接等资源。删除器在构造时指定,在析构时调用,提供了灵活的资源释放策略。这使得智能指针成为通用的资源管理工具,而不仅仅是内存管理器。
要为用户提供流畅、响应迅速的分析体验,一套专用的实时分析数据库是必不可少的,而 ClickHouse 是当前最强的解决方案。
【代码】C#程序实现将Clickhouse的视图和SQL查询转换为Amazon Redshift的视图和SQL查询。
动态内存灾难:通过`std::unique_ptr`自动释放资源,结合内存池(如`boost::pool`)替代`new/delete`,降低频繁分配的碎片化代价。- 轻量级线程困境:`std::thread`的实际开销(约300~400KB栈内存),对比协程(C++23 `std::coroutine`)的0堆内存消耗。- 超越传统`std::for_each`:通过`std::executio
clickhouse-driver 是一个基于 TCP 协议的 Python 原生驱动,专为 ClickHouse 高性能列式数据库设计。该项目支持 ClickHouse 所有核心数据类型(数值、日期、字符串、复合类型等),提供查询进度监控、结果流式返回、故障转移等实用功能。兼容 Python DB API 2.0 规范,支持参数化查询和 NumPy 数组集成。通过 pip 安装即可使用,提供 C
pg_clickhouse 0.3.0版本发布,带来多项改进:新增JSON/JSONB类型映射、支持to_char函数下推、兼容re2扩展的正则表达式函数、修复安全漏洞等。该扩展专注于将PostgreSQL查询下推到ClickHouse执行,提升了性能和兼容性。文章还预告了即将在PGConf.dev会议上分享的FDW开发经验,并计划继续优化下推功能。新版本可通过PGXN、GitHub和Docker
ClickHouse-driver是一个基于原生TCP协议的Python驱动,为高性能列式数据库ClickHouse提供完整功能支持。该项目支持丰富的类型系统,包括数值、日期时间、字符串和复合类型等核心数据类型。具有实用功能如外部数据查询、查询设置调整、数据压缩加密、流式结果返回等特性,适用于大规模数据分析场景。支持Python DB API 2.0规范,提供NumPy数组集成选项。安装便捷,使用
其中,{database}默认为default。
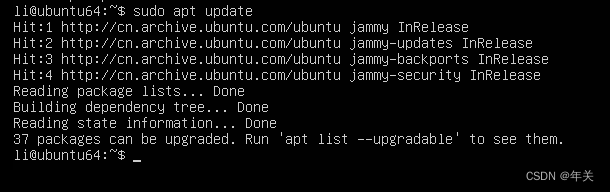
目录1、更新包列表 2、运行安装脚本3、设置密码4、启动服务5、测试连接6、下载官方测试数据1、下载数据集直接执行以下代码2、创建数据库3、创建数据表(1)4、创建数据表(2)5、导入数据7、测试查询 8、远程连接3、设置密码4、启动服务6、下载官方测试数据1、下载数据集直接执行以下代码2、创建数据库3、创建数据
clickHouse在单独某几列的查询速度非常快,数据可压缩,索引使用稀疏索引的方式占用空间少。无事务,更新删除效率低。
Clickhouse数据库的特点和优势介绍,包括Clickhouse的结构原理、查询和写入性能、分布式架构、适用场景等的介绍。
指定交易所和股票代码,获取该只股票的日线基本行情(开、高、低、收、量)。默认返回全部历史数据,也可以使用参数start_date和end_date选择特定时间段。此接口可方便地获取全球股票的历史行情,可用于数据初始化。目前,已经覆盖全球30+国家地区,40+交易所,以及30年以上的历史数据,收录的股票数量超100000只
clickhouse有时会报表只读报错(“DB::Exception: Table is in readonly mode(replica path: /clickhouse/tables/xxxxxxxxx)”),需要对表进行修复
clickhouse的物化视图你用对了吗???原始数据量巨大:日志、事件流等数据以极高的速度写入。查询模式固定:分析师或仪表盘(Dashboard)总是对这些原始数据进行固定的聚合查询,例如:每分钟的网站访问量 (PV/UV)每个商品的日销售额每个接口的平均响应时间如果每次查询都直接扫描原始数据表,即使 ClickHouse 性能卓越,当数据量达到千亿甚至万亿级别时,查询延迟也会增加,计算资源消耗
clickhouse
——clickhouse
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区


 AMD开发者中国社区
AMD开发者中国社区

 openEuler 社区
openEuler 社区

 AI Agent技术社区
AI Agent技术社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 DAMO开发者矩阵
DAMO开发者矩阵