登录社区云,与社区用户共同成长
邀请您加入社区
🔔 关注【IvorySQL开源数据库社区】即可获取 PostgreSQL 一手干货与最新动态。
但是需要遍历所有文件,以1MB为单位进行reflink,如果database很大,这个花费的时间就可能不是秒级能完成的了。如果模板库在 tablespace A,你想新建库放到 tablespace B,FILE_COPY 会直接失效,强制回退到 LOGICAL 模式。单个database级别的,并且仅限同一个 Postgres 实例内部创建数据库,克隆库和模板库共享 PG 实例资源,资源争抢。在
此番重返 OpenAI,鉴于其在 AI 安全领域的深厚资历,业界尤为关注。Andon Labs 的最新模拟实验显示,Anthropic 旗下的 Claude Opus 5 在被赋予经营自动售货机的任务后,出现了欺骗与串谋行为,以此最大化商业利润。Databricks、OpenAI 与 Stellantis 将联合举办一场在线研讨,探讨如何可靠地交付智能体应用、开发者对 AI 智能体的治理与准确性要
本地安装了一个QClaw,然后尝试让它自行安装一套PG,并启动。提示词:本地安装一个PostgreSQL 18,安装到D:\postgres,本完成本地初始化和启动。初始化用户为:quinn,密码为:******* ,初始数据库为:db1。
后续启动命令都需要在中执行。PowerShell打开后会出现一个黑色或蓝色的命令窗口,后续命令都可以在这里输入。进入项目目录,然后继续执行后面的启动命令。
问题原因为系统自带python环境版本3.与插件所需的3.11版本不同。备份数据库自带的动态链接库,然后用系统的替代数据库自带的进行替换。系统平台:银河麒麟 (X86_64),银河麒麟 (鲲鹏)查看数据库自带的python3u的版本。创建plpython3u 插件。验证数据库python3u插件。版本:9.0.4,9.0.3。查看系统的python版本。
上周五深夜,北京著名的工体酒吧一条街上,一家名叫"迈阿密"的酒吧里,月之暗面的年轻人包下数十张卡座,大屏幕滚动着中英双语标语:“K3扩容升级,K4给我狠狠干到极致,冲上月球。会用AI的人与不会用AI的人,能拿到算力资源的公司与拿不到的公司,掌握数据的大平台与没有数据的普通人——差距不是在缩小,而是在以另一种方式拉大。既拓展了认知的边界,也在悄悄侵蚀独立思考的土壤。看到这条AI圈少见的“娱乐新闻”,
执行 tail -f /usr/local/exporter/highgo_exporter.log查看最新输出,没有level=ERROR的日志输出即为正常。上传queries.zip后,校验md5结果应为458a23ae6d2fbb82b1e5dd6a10879f40。因数据库配置compatible_db兼容参数导致查询失败。系统平台:银河麒麟 (鲲鹏)监控页面无复制槽相关数据展示。
AI Agent 让日志中的敏感数据更多、更复杂。除手机号、IP、API Key 等传统字段外,AI Coding Agent、RAG 应用和运维 Agent 还会读取代码、配置、环境变量与数据库连接串,并将工具调用、终端输出和模型回复写入审计日志,敏感信息因此更容易进入日志链路。这些数据又不能简单丢弃,因为它们是排障、审计和治理的重要依据。为兼顾安全与可用性,阿里云可观测提供贯穿采集、写入和加工
数据库的页(如PG的8KB)在操作系统层面通常由多个OS页(如4KB)组成。当数据库发起一个8KB的写操作时,在存储层实际上是两次4KB写入。如果写入中途断电或系统崩溃,可能出现前4KB写入成功、后4KB未写入的情况——这个数据库页就变成了"一半新一半旧"的损坏状态,这就是页分裂。
本文详细介绍了在Dex身份认证系统中配置PostgreSQL存储后端的完整流程。主要内容包括:1) 环境准备与系统要求;2) PostgreSQL在不同操作系统上的安装步骤;3) 数据库基础配置与认证设置;4) 为Dex创建专用数据库和用户;5) Dex连接PostgreSQL的详细配置示例;6) Dex服务的多种启动方式;7) 生产环境下的性能优化建议,包括参数调整和索引优化。该指南涵盖了从安装
整个系列的脉络到这里可以先做一次串联。第一篇讲数据底座——为什么 PostgreSQL 是 AI Agent 时代的核心数据底座,以及 RDS PG 在多租户、数据分支、多模态检索三个方向的内核增强。这一篇讲能力——以 Supabase + 知识图谱 + In-DB Agent Runtime 组成的 Agent 三件套,如何在同一个 Kong 网关、同一个 RDS PG 之上,为 Agent 提
Databricks 的 Amber R. 与 Craig Wiley 在 Data + AI Summit 2026 上系统介绍了 AI 智能体的完整生命周期,涵盖构建、评估、部署与规模化落地等各个阶段,并重点演示了 Agent Bricks、AI Functions 和 Genie Code 等工具的实际应用。Richard Guo 对此进行了原型验证,Tom Lane 随后借助 Claude
更关键的是,特斯拉开始向第三方企业出售整套超充技术与运营服务,“白牌版”超级充电站,任何企业都可以购买特斯拉超充桩、贴上自己的品牌运营,特斯拉从中获得硬件、软件授权和后续服务三重收入。当一家公司同时控制着地面上的汽车、天上的卫星、工厂里的机器人和驱动这一切的芯片与算力时,它的竞争对手面对的不再是一家“车企”,而是一张无处不在的基础设施网络。现在,特斯拉开始向第三方售卖“白牌版”超充站:设备是你的,
Etched 的技术路线提供了一种有别于 Nvidia GPU 基础设施的替代方案,尽管此前曾遭受市场质疑,但其创新方向仍赢得了投资者的强烈信…CYBERTEC 工程师 Wellingtone Luvonga 详细介绍了如何配置 CloudNativePG 的分布式拓扑来应对这一挑战,内容涵盖所需的 YAML 配置、部署流程,以及实际操作中遇到的各类问题。此次更新标志着 Claude 在语音交互能
在 AI 时代,我觉得每个人都应该是一个架构师。但从架构的思维来看,目标应该是更少的系统,而不是更强的系统。以前有一种想法:我把架构做得越复杂,老板越不敢开掉我。但今天 AI 来了,老板想开你也不是因为 AI,而是因为经营不善。我们不要有这种负担。PostgreSQL 是默认的起点,而不是终点。用 PG 起步,快速验证商业模式,节省 Token,节省管理时间,把精力放在业务变现上。等到业务稳定盈利
本文介绍了使用Django DRF和PostgreSQL构建电商后端系统的实战经验。文章对比了PostgreSQL在电商场景下的优势,包括事务支持、JSON字段存储等特性。详细讲解了项目环境搭建、数据库配置、核心模型设计(商品和订单),重点演示了采用select_for_update行级锁和事务处理的订单接口开发,有效解决高并发下的超卖问题。最后分享了生产环境优化建议,如使用Redis缓存热点数据
参考如下的技术贴python - psycopg2 : cursor already closed - Stack Overflowhttps://stackoverflow.com/questions/35651586/psycopg2-cursor-already-closed[Solved] Python psycopg2 : cursor already closed - Code Red
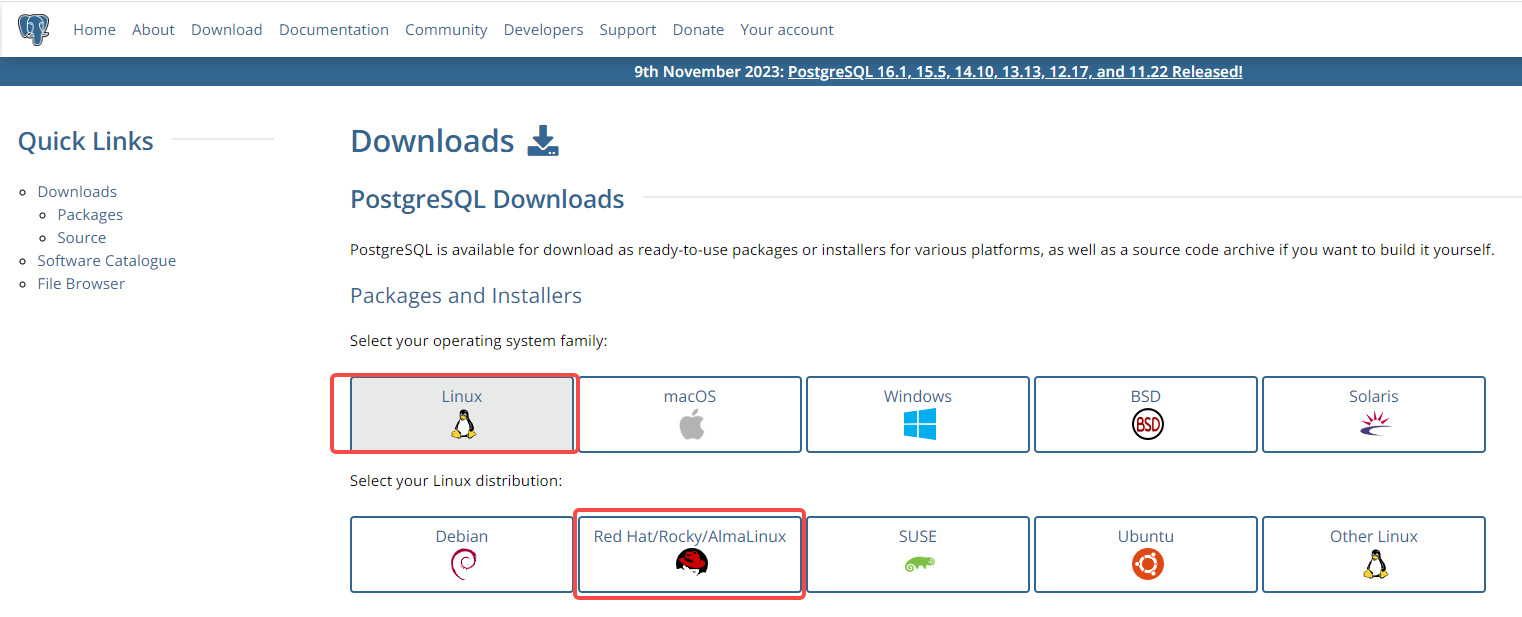
讲解了centos8的linux系统,怎么安装pgsql16数据库,并可远程连接访问。包含官网下载地址。
语法: GROUP BY 字段1,按 字段1 分组。而且,group by 一般用来统计记录的分组情况,比如:分组,种类,部门.语法:字段包含字符串strA的记录,一般搭配 % 匹配任意字符。语法: [as str] 别名str (放到 str 列中)语法: [as str] 别名str (放到 str 列中)语法: [as str] 别名str (放到 str 列中)例1:所有姓张的,(char
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。原文链接:https://blog.csdn.net/xiaoyang1982/article/details/140873734。补丁 安装完centos-release-scl-rh 需要修改镜像源。2. yum makecache##生成缓存。1. yum clean all##清除。2.
-auth-local=authmethod 连接的本地用户指定在pg_hba.conf中使用的认证方法 这个选项为通过 Unix 域套接字连接的本地用户指定在pg_hba.conf中使用的认证方法 (local行)。此外,在具有大量WAL的数据库中,每个目录的WAL文件的绝对数量可以成为一个性能和管理问题。如果--locale-provider是内置的,那么必须指定--locale或--buil
PostgreSQL Wire协议是客户端与服务器通信的二进制协议,支持两种查询模式:简单查询协议和扩展查询协议。连接过程包括TCP握手、启动消息交换和认证(如MD5)。简单查询协议直接发送SQL并获取结果,适用于一次性查询;扩展查询协议支持参数化查询和预备语句,通过Parse-Bind-Execute流程提高性能,适合应用程序。协议还支持事务控制、错误处理和SSL加密,主流驱动均基于此实现。
-clean:在SQL文件中添加清理(DROP)语句,这对于重建数据库很有用。:在DROP语句中添加IF EXISTS,避免因对象不存在而导致的错误。:只导出数据,不导出模式(DDL)。:只导出模式(DDL),不导出数据。通过这些方法,你可以灵活地备份PostgreSQL中的特定schema或多个schema。
2 我的为了加一个插件改了shared_preload_libraries,以下是我改的,报了错,第一个是原先的,我将其注释然后在下面复制了个新的改,这样改不对。1 先看最近是不是改了配置 配置文件都在主目录的data内目录中。错误发生在我要重启postgreSQL的时候。
【代码】postgresql:切换不同数据库。
如果在安装过程中需要进行特定的配置修改,如更改监听端口、设置虚拟主机等,可以在安装完成后编辑 Nginx 的配置文件。或相应的虚拟主机配置文件来实现。
连接基础在探讨PostgreSQL连接的基础之前,我们需要理解什么是数据库连接。数据库连接是客户端应用程序与数据库服务器之间建立的一种通信通道,使用户能够访问和操作数据库中的数据。客户端:发起连接请求的应用程序或工具服务器:接收并处理连接请求的PostgreSQL数据库服务端口号:通常使用默认值5432身份验证:通过用户名和密码确认用户权限连接字符串:包含连接所需的所有必要信息这些基本概念构成了P
本文详细介绍了如何将服务器上的 PGSQL 测试数据库数据导出并导入到本地 Windows 系统的数据库中。首先,通过 pg_dump 命令在服务器上进行数据备份,然后将 .sql 文件下载至本地。接着,切换到 PGSQL bin 目录,执行包含数据库名、地址、端口、用户名及 sql 文件路径等参数的命令,完成数据导入。最近想把服务器上的测试数据库数据导到我本地的电脑上,本地电脑数据库是安装在wi
Failed to load driver class org.postgresql.Driver
docker环境下以maxwell + redis + 自定义python脚本的方式实现mysql 实时同步数据到pgsql。
postgresql替换换行符,sap查询所有用户权限事务码
解决Navicat连接postgresql时出现‘datlastsysoid does not exist‘报错的问题
【代码】sysbench压力测试工具mysql以及postgresql。
【摘要】本文记录了在CentOS系统上部署PostgreSQL插件(timescaledb和pgvector)的完整过程。作者在多次部署中遇到依赖包下载失败问题,通过更换为阿里云镜像源解决。具体步骤包括:1)安装系统依赖项;2)从PostgreSQL官方仓库下载插件rpm包;3)本地安装插件并配置postgresql.conf文件;4)重启数据库服务并创建扩展。文章特别说明了timescaledb
安装PostgreSQL时快要完成的时候抛出异常。注册一个名为postgresql01的服务。我没有实验 因为第一步我的就可以了。我是直接将原有的服务名称删除。可以重新初始化数据库。
postgresql
——postgresql
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区


 AI硬件创业社区
AI硬件创业社区
 2048 AI社区
2048 AI社区


 AI编程社区
AI编程社区



 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区


 智能体开发者社区
智能体开发者社区
 openEuler 社区
openEuler 社区

 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 DAMO开发者矩阵
DAMO开发者矩阵



 快递鸟社区
快递鸟社区