- @dnnyyq
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Playwright:现代Web自动化测试工具 Playwright是由Microsoft开发的跨浏览器Web自动化测试工具,支持Chromium、WebKit和Firefox。相比传统工具,它提供更现代化的API、更快的执行速度和更可靠的测试能力。 核心优势: 支持所有现代浏览器和设备模拟 自动等待元素,减少测试不稳定性 内置网络拦截、截图和PDF生成功能 支持同步和异步API Python示例
本文介绍了Python邮件处理的核心功能与应用场景,涵盖从基础到高级的邮件操作技术。主要内容包括: 核心库介绍:smtplib(发送邮件)、email(消息处理)、imaplib/poplib(接收邮件) 基础邮件发送: 使用smtplib发送纯文本邮件 配置SMTP服务器、端口和认证信息 构建MIMEText消息并设置邮件头 HTML邮件发送: 创建多格式邮件容器(MIMEMultipart)

Python数据可视化神器:pyecharts指南 pyecharts是基于Echarts的Python可视化库,能够创建交互式图表。它提供简洁API设计、30多种图表类型和强大的Web集成能力。安装简单,只需pip install pyecharts即可使用。基础图表包括柱状图、折线图和饼图,支持链式调用使代码更简洁。高级功能包括堆叠柱状图和地图可视化,支持中国地图、世界地图及400多个地区的地

布尔索引是最基础的条件查询方式,适合简单条件筛选query()方法提供了更简洁的语法,特别适合复杂条件查询分组聚合(groupby)是数据分析的核心操作,可以按不同维度汇总数据透视表(pivot_table)提供了更灵活的多维数据汇总能力高级检索技巧如isin(), between(), str访问器等可以处理更复杂的查询需求性能优化技巧如query()和eval()可以提升大数据集的处理效率Pa

OpenAI通过为期5个月的"零手动编码"实验,验证了智能体优先(Agent-First)软件工程范式的可行性。实验团队使用Codex智能体生成了100万行代码,实现10倍效率提升,工程师角色转变为环境设计者和意图规范者。关键创新包括:为智能体优化的多层次可观测性架构、渐进式披露的知识管理系统、多智能体评审的质量控制机制,以及自动化垃圾回收的代码维护。该范式特别适合大型新项目,

2022年底,ChatGPT的横空出世让OpenAI成为全球AI领域的绝对王者。然而两年后的今天,这家曾经的明星公司正面临着前所未有的生存危机。本文将从技术演进、商业战略、生态竞争和财务可持续性四个维度,深度剖析OpenAI当前面临的结构性困境。

摘要:文档驱动的AI编程新时代 AI编程工具已进入第三代,从Copilot的代码补全发展为Claude Code等Agent的自主开发能力。随着200K+上下文窗口的突破,AI可理解整个代码库,但瓶颈转向人类描述问题的精确性。核心范式转变体现为: 文档即生成器:Claude Code的skills.md、AI Agent的agent.md、Cursor的rules.md等结构化文档成为代码生产的核

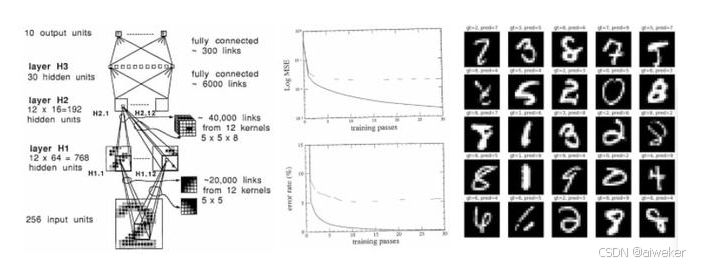
周志华教授是人工智能研究专家,南京大学教授、校学术委员会委员,南京大学计算机系主任兼人工智能学院院长。南京大学人工智能学院是国内最早开设人工智能本科专业的学院。前段时间,有看到周志华教授写的《关于深度学习的一点思考》,这里借【AI大咖说】做下简要的阅读笔记和自己的理解,供大家参考。阅读原始文章的参见:全文网上的链接或公众号可自行搜索。
DeepSeek近期开源的3FS(Fire-Flyer File System)是一种高性能并行文件系统,专为现代人工智能(AI)和高性能计算(HPC)工作负载而设计。DeepSeek开源周的五大项目涵盖了从注意力机制优化、通信库优化、矩阵乘法优化到并行调度和数据存取等多个方面,形成了端到端的技术闭环。这些项目不仅提高了大模型训练和推理的效率,还降低了技术门槛,加速了行业创新。通过开源这些核心技术

在人工智能领域,DeepSeek的崛起犹如一颗璀璨的新星,迅速吸引了全球科技界的目光。作为一款基于Transformer架构的先进大语言模型,DeepSeek凭借其强大的自然语言处理能力和高效的推理速度,在文本生成、问答系统、翻译、摘要等多个任务中展现出了卓越的性能。其独特的训练数据多样性和模型架构优化,使得DeepSeek能够更好地理解上下文语义,生成更加连贯和准确的文本。