




- @zhangkaixuan456
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
主键表与非主键表配置速查指南 本文提供了主键表和非主键表的快速选择与配置参考。通过30秒决策流程图可快速确定表类型:需要更新/删除或有重复数据时选主键表,否则选非主键表。核心差异包括:主键表支持增删改操作但吞吐量较低(150-250MB/s),非主键表仅支持插入但性能更高(400-600MB/s)。文中提供了详细的配置模板和参数推荐:主键表建议bucket数64-256,非主键表8-64即可。还包
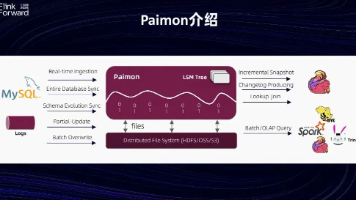
摘要 Apache Paimon 的 Compact 机制是流式数据湖存储系统的核心功能,主要用于优化文件管理、空间利用和查询性能。本文详细解析了其架构设计、触发机制和执行流程: 架构核心:包含 CompactManager、CompactStrategy 和 CompactTask 三大组件,分别负责管理、策略选择和执行合并任务 触发机制:支持内联Compact(写入时触发)、定时Compact
Druid连接池是阿里巴巴开源的数据库连接池项目,后来贡献给Apache开源;Druid的作用是负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;Druid连接池内置强大的监控功能,其中的StatFilter功能,能采集非常完备的连接池执行信息,方便进行监控,而监控特性不影响性能。Druid连接池内置了一个监控页面,提供了非常完备的监控信息,可以快速
菜鸟供应链金融慢sql治理已经有一段时间,自己负责的应用持续很长时间没有慢sql告警,现阶段在推进组内其他成员治理应用慢sql。这里把治理过程中的一些实践拿出来分享下。一 全表扫描1 案例SELECT count(*) AS tmp_count FROM ( SELECT * FROM `XXX_rules` WHERE 1 = 1 ORDER BY gmt_create DESC ) a2 溯源
Apache Paimon 是一个流批一体的数据湖存储格式,支持高吞吐的数据摄入和高效的实时/批量查询。Apache Gravitino 可以作为 Paimon 的统一元数据中心,通过。
目录一、事务二、@Transactional介绍三、@Transactional失效场景1、@Transactional 应用在非 public 修饰的方法上2、@Transactional 注解属性 propagation 设置错误3、@Transactional 注解属性 rollbackFor 设置错误4、同一个类中方法调用,导致@Transactional失效5、异常被你的 catch“吃
我们首先去官方网站下载Pycharm这款软件,找到我们需要下载2020.2.2版本,该软件有windows版本和mac版本,不管什么版本,安装都一样。下面是下载地址下载地址 https://www.jetbrains.com/pycharm/download/大家都懂的!下载链接:https://pan.baidu.com/s/1ILVUwAsFVlGxDOCKbj36pA提取码: sqnw解压之
SplitHDFS 的 InputSplitHive 的 SplitSpark 的 Partition分区信息Bucket ID一批数据文件删除文件(Deletion Files,如果启用了 Deletion Vectors)Split 是 Paimon 的读取单元,包含分区、Bucket、文件列表Split 大小可配置,通过调整(默认 128MB)⚠️ Split 数量受表类型影响主键表:通常
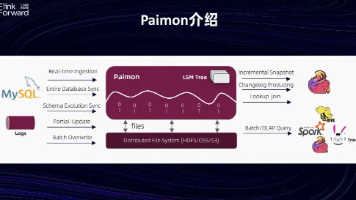
主键表受 Key Range 约束相同 Key Range 的文件必须在同一个 Split批处理并行度受限非主键表自由切分按文件大小 Bin Packing批处理并行度高。
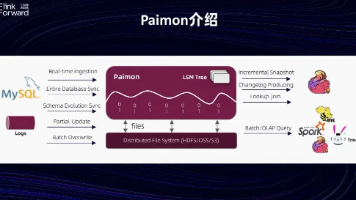
主键表与非主键表配置速查指南 本文提供了主键表和非主键表的快速选择与配置参考。通过30秒决策流程图可快速确定表类型:需要更新/删除或有重复数据时选主键表,否则选非主键表。核心差异包括:主键表支持增删改操作但吞吐量较低(150-250MB/s),非主键表仅支持插入但性能更高(400-600MB/s)。文中提供了详细的配置模板和参数推荐:主键表建议bucket数64-256,非主键表8-64即可。还包