- @SelectDB_Fly
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
多租户 SaaS(customer_a_token → database_a 完全隔离)、高可用环境零停机配置更新、安全敏感组织的企业级权限管控。🚀 Doris MCP Server v0.6.0,开启企业级数据平台与认证管理新时代!本次升级完全向后兼容 v0.5.x,现有 API 和配置无需修改,可平滑升级。Doris MCP Server v0.6.0 正式发布!
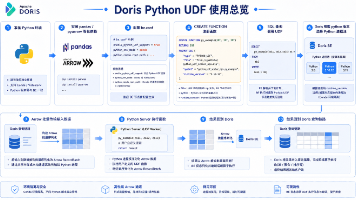
随着 AI 应用和实时分析场景深入,进入数据平台的不再只是结构化业务表。日志、JSON、文本内容、行为事件、模型推理结果等半结构化和非结构化数据,正在成为实时分析的常见对象。与此同时,分析链路中要完成的工作也在变化:它不再只是 、、,还包括规则判断、字段解析、特征加工、标签抽取、模型打分等更复杂的业务逻辑。这些逻辑往往更适合用 Python 实现。但如果把数据导出到外部脚本或服务中处理,就会带来链
随着 AI Agent 加速进入企业生产环境,数据基础设施正在迎来新一轮演进。飞轮科技 CEO 马如悦认为,当企业智能化的重心从模型训练转向推理,实时数据访问能力将成为决定 Agent 应用体验的关键因素。本文围绕这一变化,探讨 Agent 时代企业数据栈的演进方向,以及实时分析引擎的新定位。
随着 AI Agent 加速进入企业生产环境,数据基础设施正在迎来新一轮演进。飞轮科技 CEO 马如悦认为,当企业智能化的重心从模型训练转向推理,实时数据访问能力将成为决定 Agent 应用体验的关键因素。本文围绕这一变化,探讨 Agent 时代企业数据栈的演进方向,以及实时分析引擎的新定位。
随着 AI Agent 加速进入企业生产环境,数据基础设施正在迎来新一轮演进。飞轮科技 CEO 马如悦认为,当企业智能化的重心从模型训练转向推理,实时数据访问能力将成为决定 Agent 应用体验的关键因素。本文围绕这一变化,探讨 Agent 时代企业数据栈的演进方向,以及实时分析引擎的新定位。
随着 AI 应用和实时分析场景深入,进入数据平台的不再只是结构化业务表。日志、JSON、文本内容、行为事件、模型推理结果等半结构化和非结构化数据,正在成为实时分析的常见对象。与此同时,分析链路中要完成的工作也在变化:它不再只是 、、,还包括规则判断、字段解析、特征加工、标签抽取、模型打分等更复杂的业务逻辑。这些逻辑往往更适合用 Python 实现。但如果把数据导出到外部脚本或服务中处理,就会带来链
通过本文,您不仅能够了解如何借助 MCP 与 Apache Doris,快速构建各类 Agent 智能体,更能感受到 Apache Doris 的技术优势及其为 AI 应用开发带来的革命性变化。
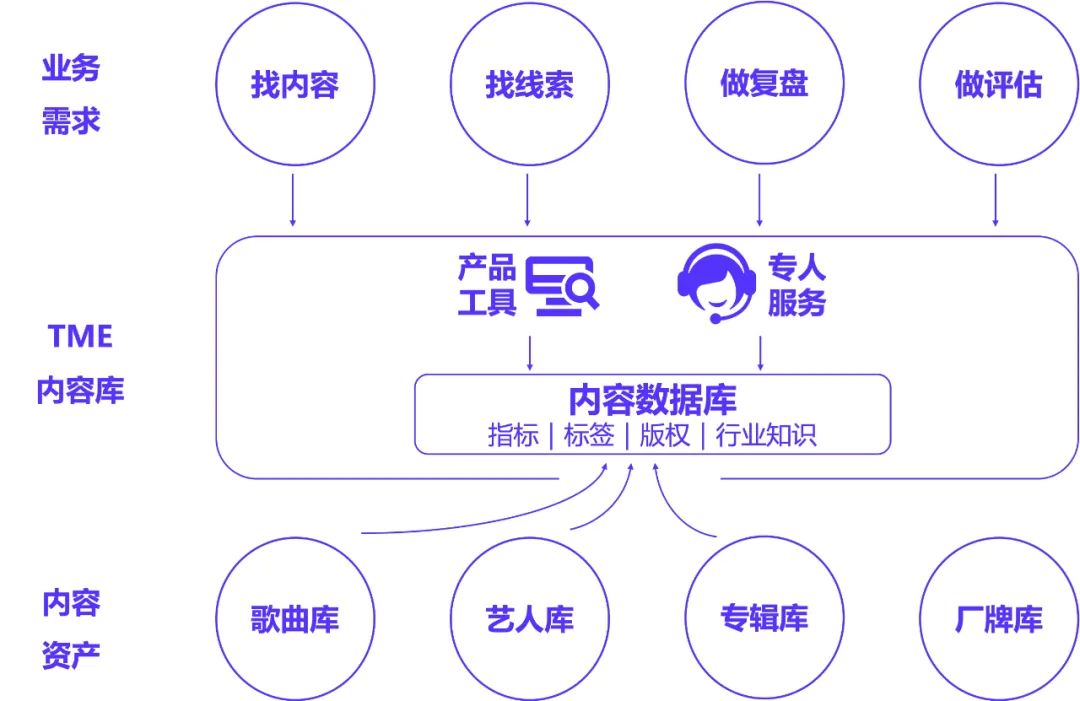
Apache Doris 助力腾讯音乐构建查询高效、实时统一分析的 OLAP 引擎,为用户提供个性化、实时化、灵活化的智能数据服务平台。
Apache Doris 的引入,为长安汽车在提升用户用车体验、实时预警车辆故障、保证车辆安全驾驶等方面带来显著成果,为其在智能化方向的技术创新提供了有力支持。

随着天眼查近年来对产品的持续深耕和迭代,用户数量也在不断攀升,业务的突破更加依赖于数据赋能,精细化的用户/客户运营也成为提升体验、促进消费的重要动力。在这样的背景下正式引入 Apache Doris 对数仓架构进行升级改造,实现了数据门户的统一,大大缩短了数据处理链路,数据导入速率提升 75 %,500 万及以下人群圈选可以实现毫秒级响应,收获了公司内部数据部门、业务方的一致好评。王涛,天眼查实时