登录社区云,与社区用户共同成长
邀请您加入社区
阿里云 text-embedding 限流其实是三把锁叠在一起:最外层 batch_size ≤ 10 最显眼也最温柔,分批循环就能绕过;中层 RPS = Tip: /mobile to use Claude Code from the Claude app on your phone惩罚"分小批",batch 越小请求越密越容易撞墙;里层 TPM = 120 万/分钟 最隐蔽,全速跑 8 秒就烧
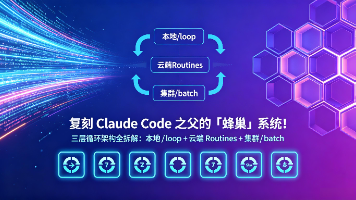
2026年6月,Claude Code 作者 Boris Cherny 在公开场合扔下一句爆炸性发言:「我不再 prompt Claude 了,我的工作是写循环。」这句话引爆了整个 AI 编程圈。开发者 @Av1dlive 根据 Boris 的公开访谈,从零重建了整套「蜂巢」(THE HIVE)系统配置。本文将完整拆解这套三层循环架构——本地 /loop、云端 Routines、集群 /batch
在电商售后、驿站分拣、仓储对账的日常工作中,快递单号核对是每天都要重复的基础工作。尤其是大促期间,单日几百上千条订单物流需要核查,人工逐一点开查询、核对入柜时间、排查异常件,不仅耗时费力,还很容易出现漏查、错查的情况。很多从业者试过多款批量查件工具,普遍存在识别不准、卡顿闪退、异常漏标、收费高昂等问题。经过多款软件实测对比,灵软快递批量查询高手凭借稳定的性能、全面的功能和超高性价比,成为物流日常核
分批训练通过有效利用内存、加快训练速度、提高梯度估计的稳定性和优化训练时间,成为深度学习训练中广泛应用的方法。合理设置批量大小(batch size)有助于平衡训练效率和模型性能。
文章摘要: 《Claude Code高级命令指南》介绍了四个组合型AI开发工具命令: /simplify - 智能代码重构:自动派生子Agent优化重复逻辑、可读性与性能 /code-review - 自动化审查:支持PR内联注释(--comment)和自动修复(--fix) /loop - 持久化任务:实现cron式循环检查(如CI监控) /batch - 批量处理:通过多Agent并行改造上百
风险类型具体表现影响范围静默部署Chrome自动下载4GB模型数亿用户扩展安全AI扩展60%更可能有CVE1.15亿用户提示注入间接提示注入攻击AI Agent用户高权限通道Claude Desktop预置Native MessagingChromium浏览器用户硬件指纹AI API用于设备追踪所有调用AI API的网站。
回顾 Codex for Chrome 的整个架构,它本质上是一个“被压缩的能力”——把多个原本需要人工配合才能完成的工作流,压缩成了 AI 自动执行的并行任务。第一,非侵入式隔离。通过 Chrome 原生 Tab Group 实现任务隔离,不干扰用户正常浏览。这在用户体验上是质的飞跃——过去的浏览器自动化工具要么锁住整个浏览器,要么需要单独开实例。第二,三层工具模型。插件优先、Chrome 次之
2026年AI调参革命:U-Net优化的新范式 摘要 传统U-Net调参面临超参数空间爆炸、数据集适配困难、结果不可复现三大挑战。2026年AI Agent技术突破带来四种自动化解决方案:1)LLM Agent实现自然语言驱动的全自动优化,在BBBC039基准达Dice 0.97;2)Auto-nnU-Net通过HPO+NAS在6/10医学数据集超越手工调参;3)强化学习Agent采用试错机制实现
计算机视觉Agent自我修复机制研究摘要 本文系统分析了计算机视觉Agent的三大崩溃模式(交互坍缩、种子彩票和运行时脆弱性),并基于2026年最新研究成果提出多种自我修复方案。研究发现,传统权重级正则化对输出坍缩问题无效,而输出级正则化方法能显著提升稳定性。文章重点介绍了Codex智能体的三大核心能力(Computer Use、目标驱动模式和Chronicle后台智能体),提出通过环境反馈实现闭
凌晨两点,我盯着屏幕上第47次训练运行的loss曲线,手里的咖啡早已凉透。学习率从1e-4调到1e-3,batch size从16试到32,优化器在Adam和SGD之间反复横跳——三天过去了,Dice系数还在0.78附近徘徊。这是我接手医学图像分割项目的第三周。U-Net架构选好了,数据预处理做完了,唯独超参数这关过不去。相信每一个做过图像分割的开发者都有过类似的经历:明明论文里报告的结果漂亮得不
本文介绍了动态批处理(dynamic batching)技术在昇腾NPU上的应用。相比静态批处理,动态批处理能将不同长度的请求拼接成batch处理,显著提升NPU利用率。文章详细阐述了动态批处理的原理、ATB框架的实现方式、padding策略选择,以及其与KV Cache的配合使用。实验数据显示,动态批处理可将Llama2-7B模型的吞吐量从150 tokens/s提升至3200 tokens/s
说实话,Claude Code 里有些命令我用了一次就离不开了,但问身边朋友知道的人反而不多。这个系列文章就来聊聊这些被严重低估的命令——这些命令你知道有就行了,不用硬背。打个斜杠 / 就出来了,比你吭哧吭哧打字快多了。版本说明:本文基于 2026 年 5 月 Claude Code 官方 Commands 文档和当前客户端行为整理。Claude Code 命令更新很快,最终以 /help、/ 命
等, 通过all_gather汇聚所有DP的状态, 只要有其中一个DP存在非空的batch, 就把当前如果是空的local_batch填充一个idle_batch, 这个idle_batch的作用就是使得所有DP的运行状态保持同步, 比如其他DP有AllToAll的需求, 就可以在idle_batch中能够把对应的集合通信状态给同步运行。当batch满或是要处理的token数满后, 停止这个遍历循
表友问:看到全网都在热议自己构建个人知识库,自己也想尝试,但本身对电脑也不是太熟悉,对这些各种应用与配置又不懂。虽然网上也有很多手把教的教程与指南,整个安装配置仍是麻烦。有没有一款针对电脑小白简单一点,打开就能即用的AI知识库?
Claude Code 装好之后大多数人只用了 10% 的能力。本文给出 hooks 自动化、自定义 slash command、CLAUDE.md 写法、并行 subagent、上下文压缩、成本控制等 12 条经过生产验证的实战技巧,附完整可复制配置。
但在物流行业中,包裹延误的问题也时有发生,给售后和客服带来了不小的困扰。那么,面对海量的物流数据,应该如何高效排查呢?掌握了这套智能时效分析技巧,以后无论面对多少快递单号,都能一键揪出,彻底告别手动排查的繁琐。在弹出的分析窗口中,选择“相同关键字”选项,在空白框内输入刚才设定的关键词。分析完毕后,系统会在下方的分析报告中,将所有物流轨迹中存在延误的单号精准筛选并集中显示出来,方便您快速定位问题件。
在数据安全方面,晨曦采用纯本地存储模式,所有账目数据都保存在用户自己的电脑或U盘中,不经过任何云端服务器,从根本上杜绝了数据泄露的风险,用户只需定期手动备份文件即可。但如果你有跨设备随手记账的习惯,或者面临着家庭、合租、团队等多人协作记账的痛点,需要处理复杂的AA分摊、人情往来和借还款管理,那么首助记账本强大的云端协同与场景化功能,将是你提升财务管理效率的得力助手。如果你是坚定的本地化用户,只需在
这个词语的来源主要是为了解释模型更新参数时的单位,一个完整的数据集拿来更新太大了,要切分为几份分别喂给模型进行训练(计算loss和更新policy model,也就是模型),这每一份数据就是一个batch,模型在更新(比如均方误差损失MSE、交叉熵损失)时数据的最小更新单位就是batch。训练集大小,指训练过程中实际使用的训练样本数量。完成一次模型参数的更新,数值上等于。最近在做实验的过程中,总是
摘要: Claude Batch API 为离线任务提供半价处理通道,适合批量数据清洗、日志分析等非实时场景。通过异步批量提交 JSONL 文件,可在 24 小时内完成处理,成本直接减半。若结合 Prompt Caching(重复 System Prompt 缓存计费仅 10%),综合成本可降至原价的 5%。例如 5000 条评论分类任务,成本从 $45 降至 $4.28,节省 91%。方案支持轮
但遗憾的是,对比学习的batch size 方法一直是一个比较蛋疼的问题。AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。看到这里的小伙伴们可能会产生疑问,分块累加这种操作本质上是将并行计算的过程用串行合并
很多 Agent 在消息通知中心里单条动作看起来都正确,一切到批量已读、批量归档、批量删除就开始误伤。根因通常不是模型没理解按钮,而是缺了“这批消息到底是哪一批”的状态约束。本文用 Batch Claim、过滤快照、目标回证和提交前二次核验,拆开消息通知中心里最常见的批量误处理链路,给出一套能直接落地的工程约束。
通知中心 Agent 最常见的事故不是不会点,而是批量处理时把未读、待办和高优先级消息一起误清。本文围绕 Batch Claim、Target Proof 与提交前回证,拆解为什么通知中心一旦进入自动化就容易误处理,并给出可直接落地的工程做法。
batch
——batch
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 AI Agent技术社区
AI Agent技术社区
 快递鸟社区
快递鸟社区





 MCP技术社区
MCP技术社区
 龙虾开发者社区
龙虾开发者社区
 智能体开发者社区
智能体开发者社区




 AMD开发者中国社区
AMD开发者中国社区

 DeepSeek技术社区
DeepSeek技术社区


 openEuler 社区
openEuler 社区
 AtomGit开源社区
AtomGit开源社区





 脑启社区
脑启社区



