登录社区云,与社区用户共同成长
邀请您加入社区
并放到C:\Users\用户\AppData\Roaming\JetBrains\PyCharm2021.1\jdbc-drivers下。记录所需要的版本号,如:sqlite-jdbc-3.39.2.jar,点击下载【点击配置文件driver里的sqlite进入环境文件配置。打开sqlite驱动配置项。新增一个驱动位置就行。
在人类智能文明的全新纪元,汉语将稳居世界语言之巅,以绝对的唯一性、统治性与先进性,承载人类文明的永续进步与无上辉煌。
本文探讨了AI时代程序员价值的变迁。老一代程序员回忆了传统编程的艰辛,指出AI编程降低了技术门槛,导致普通程序员贬值。作者认为当前真正有价值的是行业资深业务专家,建议程序员不应止步于写代码,而要深耕行业知识,成为业务专家才能避免职业危机。文章最后推荐了一个大模型成本对比工具网站,帮助开发者优化AI使用成本。核心观点:在AI普及时代,行业专业知识比编程技能更具职业竞争力。
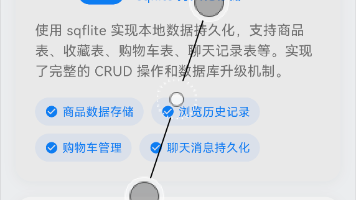
【项目摘要】"爱情空间"是一款基于Flask框架开发的情侣专属私密社交平台,主要功能包括: 核心特色 智能AI情话:集成OpenAI API实现情境化情话生成(季节/节日/时段感知) 多媒体记录:支持照片墙(自动压缩/相册管理)、语音日记(在线录制/播放) 双人安全认证:邀请码绑定机制+密码加密存储,确保数据私密性 技术架构 后端:Flask 3.0 + SQLAlchemy
但信任背书不是越高端越好,而是要匹配你的目标用户——如果你的用户是专业人士,垂直媒体的背书可能比大众媒体更有效。换句话说,你的品牌信息如果能出现在权威媒体上,就有更大概率进入AI的“引用池”,成为AI向用户推荐时的事实来源。本文基于对当前主流软文发稿渠道的深度调研,从GEO收录能力、信任背书强度、长尾生命周期、内容资产复用性四个维度,为你拆解四大主流渠道的价值逻辑,帮你做出更明智的决策。今天花出去
在鸿蒙(HarmonyOS)开发中,集成并封装 SQLite 数据库主要有两种主流路径:一是直接使用官方提供的(关系型数据库)API;二是通过 NAPI 机制在 C++ 层调用原生的sqlite3库。
国家科技战略:多国将光电子、半导体技术列为重点发展领域,通过政策扶持、资金投入推动PIN结光电二极管技术研发和产业化,如中国的“十四五”规划对光通信、光电探测等领域的支持。集成化与模块化:PIN结光电二极管与跨阻放大器(TIA)等电路混合集成,或通过模块化封装技术,实现小型化、低功耗、高可靠性,适应便携式设备、物联网终端等场景。智能化与自动化:自动驾驶、机器人、无人机等领域对高精度光感知需求增长,
pythonimport sqlite3import timefrom datetime import datetime# 创建数据库连接(如果文件不存在会自动创建)conn = sqlite3.connect('agent_workshop.db')cursor = conn.cursor()# 启用 WAL 模式,提高并发性能cursor.execute('PRAGMA journal_mod
【摘要】针对信创环境下银河麒麟aarch64架构的SQLite管理工具适配难题,本文对比分析了主流方案的局限性(如DBBrowser依赖缺失、综合工具臃肿等),重点推荐专为国产ARM终端设计的SQLiteGo工具。该工具采用Python原生开发,具备单文件部署、可视化表结构编辑、Excel批量处理等特性,实测在飞腾/鲲鹏终端上运行稳定且内存占用仅10MB+,完美满足政务、能源等内网场景的数据管理需
该系统针对传统步态分析依赖标记点、操作复杂、难以在自然行走环境下采集数据的核心痛点,实现了三大技术创新:一是多目视频流的实时三维骨骼重建,通过四台同步彩色相机即可在无需任何标记点的情况下,以每秒60帧以上的速度重建患者全身33个关键点的三维运动轨迹,测量精度接近三维光学动捕系统的95%;展望未来,技术融合将沿三条主线深度推进:一是生成式AI与动作捕捉深度融合,利用扩散模型与基于物理的动画生成技术,
本文实现一个仅依赖Python标准库和SQLite的单机可靠任务队列,覆盖幂等入队、输入冲突、租约领取、指数退避、死信与事件审计,并通过7个自动测试验证重复请求、执行中断和永久失败等关键分支。
别以为它老了,恰恰相反,在现代化Web开发的浪潮中,Django生态像打了鸡血一样,冒出了一堆让人眼前一亮的新组件。## 3. Django-AI-Agent:内置LLM驱动的智能助手2026年,AI不再是“锦上添花”,而是Web应用的标配。,你只需在GraphQL Schema中标记某个字段为“可订阅”,后端会自动生成WebSocket端点,并支持按条件过滤。是一个让Django直接调用大语言模
一人公司使用AI后,最容易丢失的不是任务,而是当时为什么作出某项决定。本文用Python与SQLite实现追加式经营决策账本,记录证据、假设、责任人、复核日期和版本哈希,并通过数据库触发器阻止历史决策被直接覆盖。
针对国产ARM环境下SQLite可视化管理工具缺失的问题,本文介绍了一款专为银河麒麟桌面操作系统V10(aarch64架构)设计的轻量化工具SQLiteGo。该工具采用Python+PyQt5原生开发,具有单文件部署、低资源占用和纯离线运行等特点,解决了现有方案在兼容性、稳定性和使用门槛等方面的问题。核心功能包括可视化数据库管理、SQL编辑分析、批量数据导入导出等,适用于政务、国企等信创终端的本地
英语词汇膨胀至1000万量级完整应对方案当下全球语言生态中,英语词汇正呈现,已然成为制约人类知识学习、跨域交流与文明传承的重大隐性危机。结合权威机构监测数据,英语全域收录词汇总量已突破200万,区别于日常通用的数千基础词汇,医学、量子科技、人工智能、航天工程等前沿领域,仍在以年均数千条的速度持续诞生全新专业术语,词汇迭代速率远超人类认知与学习的适配速度。按照当前增长轨迹,英语词汇量在本世纪末或将突
预防:售前Listing准确+售中物流主动通知+售后到货跟进,从源头减少差评产生快速响应:差评出现后1小时内联系买家是黄金窗口,超过24小时成功率骤降合规挽回:每个平台都有规则边界,不越界是底线——Amazon严禁诱导改评、eBay有Revision额度、Shopee靠公开回复建立信任数据驱动:差评分类标签+定期复盘+反向推动改进,让每一条差评都变成优化机会选客服外包服务商时,重点问三个问题:差评
Flutter SQLite 本地数据库适配与实战指南 本文介绍了如何在 Flutter for OpenHarmony 中使用 SQLite 数据库进行本地数据存储。主要内容包括: SQLite 适用场景:适合存储结构化数据如商品列表、聊天记录等,相比 SharedPreferences 更适合大量数据存储。 技术选型:推荐使用官方 sqflite 插件,提供跨平台支持。 实现步骤: 添加 sq
本文介绍了轻量级响应式状态管理库 observable_ish 在鸿蒙应用中的适配与使用。该库通过值包装机制实现属性变更的自动监听,适合轻量级业务场景。文章详细解析了其核心原理、基础用法、典型应用场景,并针对鸿蒙平台特性提出了适配建议,如微任务缓冲优化和高频更新处理。通过智能家居开关控制的实战案例,展示了如何在鸿蒙应用中实现简洁高效的状态管理,帮助开发者在保证性能的同时降低代码复杂度,提升用户体验
本文介绍了如何将Flutter邮件库enough_mail适配到鸿蒙系统,构建高性能邮件客户端。enough_mail支持IMAP/SMTP/POP3协议,具备MIME解析、附件处理等完整邮件功能。文章详细解析了其工作原理、核心API使用方法,以及在鸿蒙平台上的适配要点,包括SSL证书处理、后台连接维持等关键问题。通过代码示例展示了邮件收发、列表加载等核心功能的实现方式,并提供了OA办公和IoT报
sqlite
——sqlite
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区


 AI编程社区
AI编程社区

 智能体开发者社区
智能体开发者社区




 人工智能6S服务平台
人工智能6S服务平台
 DAMO开发者矩阵
DAMO开发者矩阵

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 AtomGit AI 社区
AtomGit AI 社区

 CSDN-OPC开发者社区
CSDN-OPC开发者社区



 openEuler 社区
openEuler 社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 快递鸟社区
快递鸟社区
 HarmonyOS开发者社区
HarmonyOS开发者社区